机器学习入门-K-means算法
无监督问题,我们手里没有标签
聚类:相似的东西聚在一起
难点:如何进行调参
K-means算法
需要制定k值,用来获得到底有几个簇,即几种类型
质心:均值,即向量各维取平均值
距离的度量: 欧式距离和余弦相似度
优化目标: min∑∑dist(ci, xi) 即每种类别的数据到该类别质心距离的之和最小
1-k x
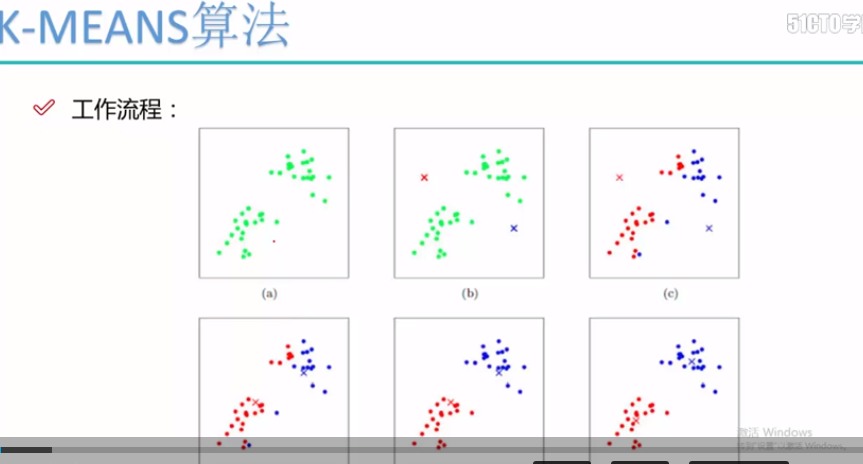
根据上述的工作流程:
第一步:随机选择两个初始点,类别的质心点(图二)
第二步: 根据所选的质心点,根据欧式距离对数据进行分类(图三)
第三步:求得分类后的每个类别的质心(图四)
第四步: 根据所选的质心点,根据欧式距离对数据进行分类(图五)
第五步:求得分类后的每个类别的质心(图五)
.... 一直到分类的数据类别不发生变化为止
优势:简单,快速,适用于常规数据集,分布较为规则的数据集
劣势:
K值难确定
复杂度与样本数据呈线性关系
不太适用于不规则的数据
我们使用sklearn来实现kmeans代码,使用silhouette_score轮廓系数来作为评估
第一步:读入数据
第二步:提取特征列
第三步:建立kmeans模型和训练
第四步:使用.grouby计算每一种类别的聚类中心,即求平均
第五步:使用scatter_matrix 画出两个变量关系的散点图
第六步:使用sihouette_score 轮廓系数来比较不同数目的聚类簇的结果影响
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd # 1.读入数据
data = pd.read_csv('data.txt', sep=' ') # 2.提取特征
X = data[['calories', 'sodium', 'alcohol', 'cost']] # 3.建立Kmeans模型和训练
from sklearn.cluster import KMeans model = KMeans(n_clusters=3).fit(X)
beer = data.copy()
beer['cluster3'] = model.labels_
# 根据分类结果,从小到大进行排序
beer = beer.sort_values(by=['cluster3']) # 4. 使用groupby 计算出每一个聚类中心的质心点, 画散点图
centers = beer.groupby(by=['cluster3']).mean()
colors = np.array(['red', 'green', 'blue', 'yellow'])
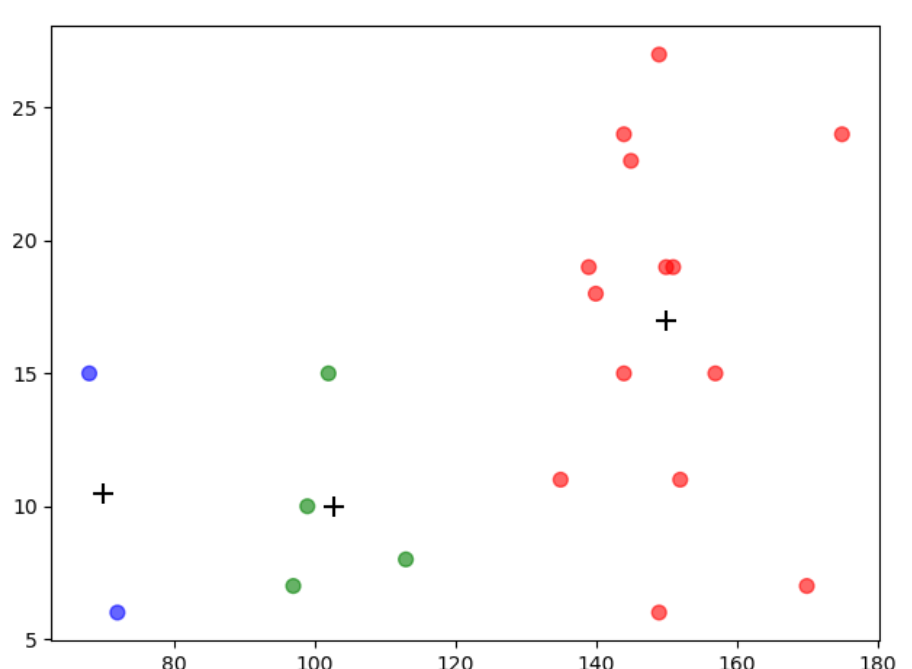
plt.scatter(beer['calories'], beer['sodium'], c=colors[beer['cluster3']], s=50, alpha=0.6)
# 画出质心的位置
plt.scatter(centers.calories, centers.sodium, c='k', marker='+', s=100)
plt.show()
 、
、
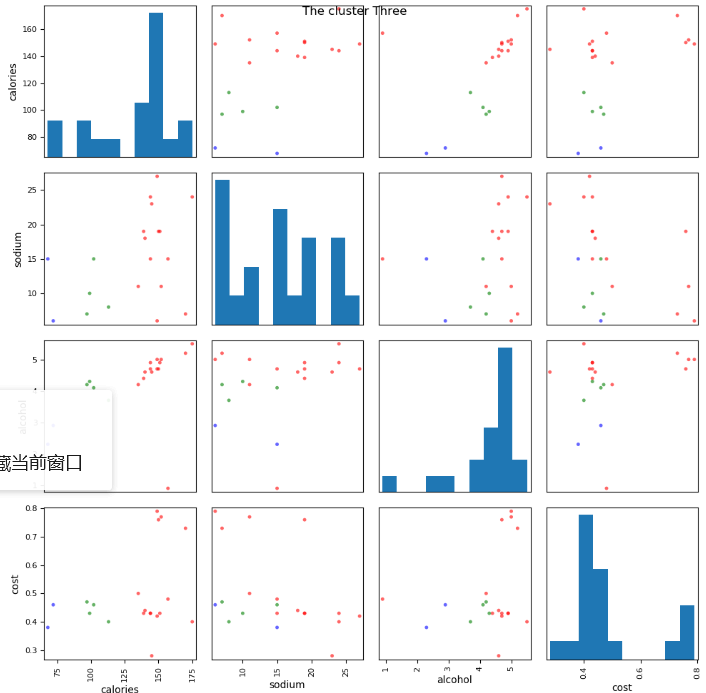
# 5. 使用scatter_matrix画出两两变量的关系图
from pandas.tools.plotting import scatter_matrix scatter_matrix(beer[['calories', 'sodium', 'alcohol', 'cost']], s=50, alpha=0.6, c=colors[beer['cluster3']], figsize=(10, 10))
plt.suptitle('The cluster Three')
plt.show()
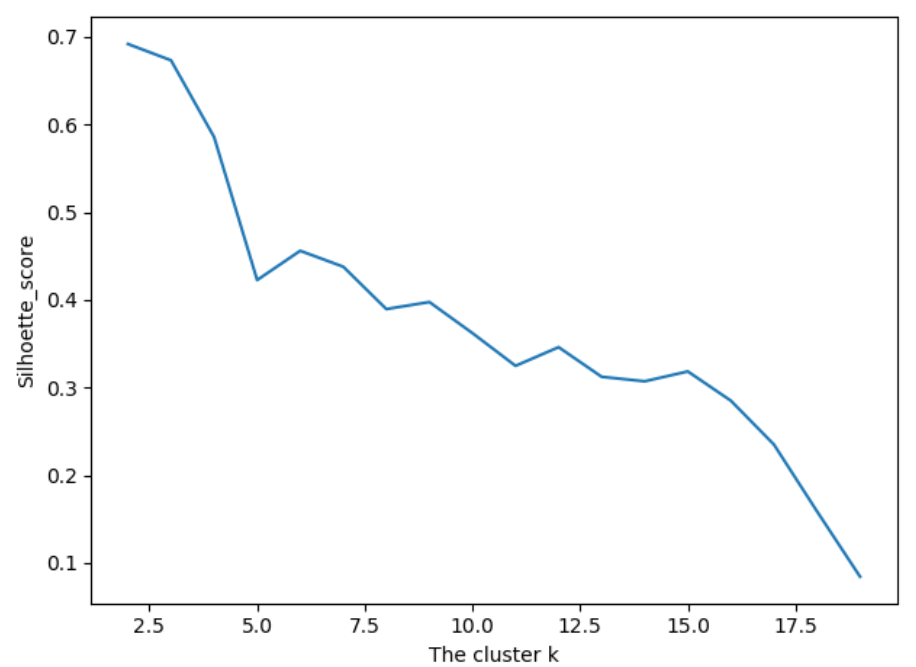
# 6.silhouette_score引入轮廓系数作为评估的标准
import sklearn # k_cluster 从2-19,判断聚类的效果
scores = []
for i in range(2, 20):
labels = KMeans(n_clusters=i).fit(X).labels_
score = sklearn.metrics.silhouette_score(X, labels)
scores.append(score)
print(score) plt.plot(list(range(2, 20)), scores)
plt.xlabel('The cluster k')
plt.ylabel('Silhoette_score')
plt.show()
机器学习入门-K-means算法的更多相关文章
- 机器学习入门:K-近邻算法
机器学习入门:K-近邻算法 先来一个简单的例子,我们如何来区分动作类电影与爱情类电影呢?动作片中存在很多的打斗镜头,爱情片中可能更多的是亲吻镜头,所以我们姑且通过这两种镜头的数量来预测这部电影的主题. ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 【机器学习】K均值算法(II)
k聚类算法中如何选择初始化聚类中心所在的位置. 在选择聚类中心时候,如果选择初始化位置不合适,可能不能得出我们想要的局部最优解. 而是会出现一下情况: 为了解决这个问题,我们通常的做法是: 我们选取K ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- [机器学习实战] k邻近算法
1. k邻近算法原理: 存在一个样本数据集,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 机器学习入门KNN近邻算法(一)
1 机器学习处理流程: 2 机器学习分类: 有监督学习 主要用于决策支持,它利用有标识的历史数据进行训练,以实现对新数据的表示的预测 1 分类 分类计数预测的数据对象是离散的.如短信是否为垃圾短信,用 ...
- 机器学习之K近邻算法
K 近邻 (K-nearest neighbor, KNN) 算法直接作用于带标记的样本,属于有监督的算法.它的核心思想基本上就是 近朱者赤,近墨者黑. 它与其他分类算法最大的不同是,它是一种&quo ...
随机推荐
- 如何查看Eclipse的数字版的版本(转)
为什么叫数字版的版本,因为Eclipse软件里显示的是文字版的版本,比如我现在的就是Version: Indigo Release.这在下载插件的时候很不方便. 如何查看文字版的版本信息:打开Ecli ...
- 极快瑞的函数式编程,Jquery涉及的一些函数
$(function(){ 一些实现功能的代码:})————————————文档载入完成后执行的函数.$(function(){}) 是 $(document).ready(function(){}) ...
- USB gadget 驱动 printer.c 分析
1. modprobe g_printer idVendor=0x0525 idProduct=0xa4a8 modprobe后面也可以加模块参数 2. prn_example从stdout获取数据然 ...
- webpack 基本使用
1. 创建webpack-test文件夹 2. npm初始化 3. 安装webpack 4. 使用webpack打包 hello.js 是需要打包的文件 hello.bundle.js 是打包完以后 ...
- Angular 4 路由时传递数据
路由时传递数据的方式有 1. 在查询参数中传递数据 2. 在路由路径中传递参数 3. 在路由配置中传递参数 一.在查询参数中传递数据 在前一节的基础上,我们增加路由数据传递 2. 接收参数的地方 3. ...
- 【python】格式化字符
格式化字符串总结如下,红色部分是需要掌握部分: 以下几个常用的实例: 1.%s的使用 "%s is the author" %("paulwinflo")> ...
- java Collections工具类
Collections 是专门对集合进行操作的类 比如排序sort 也可以使用自定义的比较器 sort文档中的定义 必须具有比较性,具有比较性必须是comparable 的子类 '<T ext ...
- Python数据结构算法
Python内置了许多非常有用的数据结构,比如列表(list),集合(set)以及字典(dictionary).就绝大部分情况而言,我们可以直接使用这些数据结构.但是,我们通常还要考虑比如搜索,排序, ...
- Spring IOC - 控制反转(依赖注入) - 单例和多例
Spring容器管理的bean在默认情况下是单例的,即一个bean只会创建一个对象,存在map中,之后无论获取多少次该bean,都返回同一个对象. Spring默认采用单例方式,减少了对象的创建,从而 ...
- Excel 公式CORREL算出相关系数
当对 N 个主体中的每一个变量进行观测时,CORREL 工作表函数可计算两个测量变量之间的相关系数.(缺少任何主体的观测值将导致该主体在分析中被忽略.)当 N 个主体中的每一个均具备两个以上的测量变量 ...