01.SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql
第一次引入文件组的概念:http://www.cnblogs.com/dunitian/p/5276431.html
上次说了其他的解决方案(http://www.cnblogs.com/dunitian/p/6041745.html),就是没有说水平分库,这次好好说下。
上次共享的第一份大数据,这次正好来演示一下水平分库
1.模拟部分数据
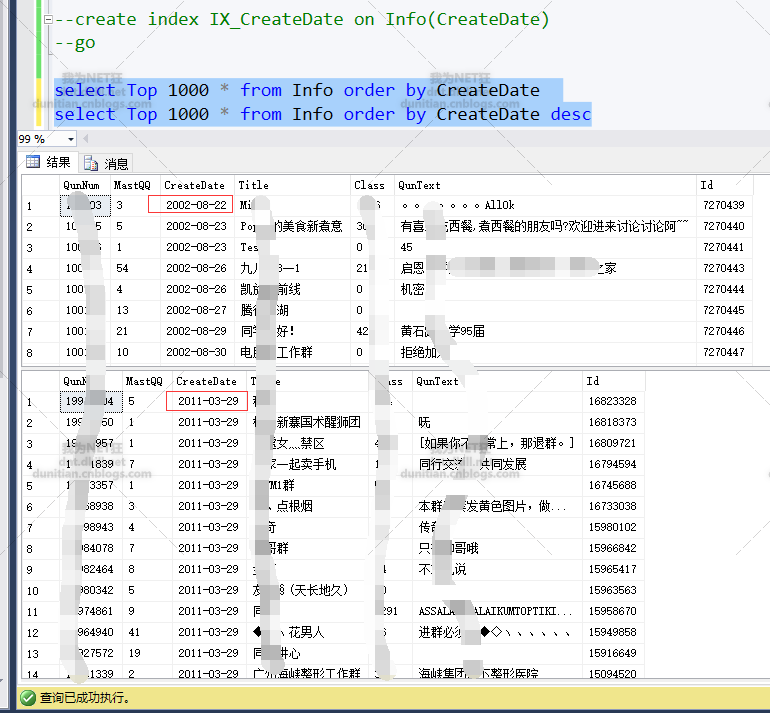
2.创建索引后,发现可以根据日期来分组
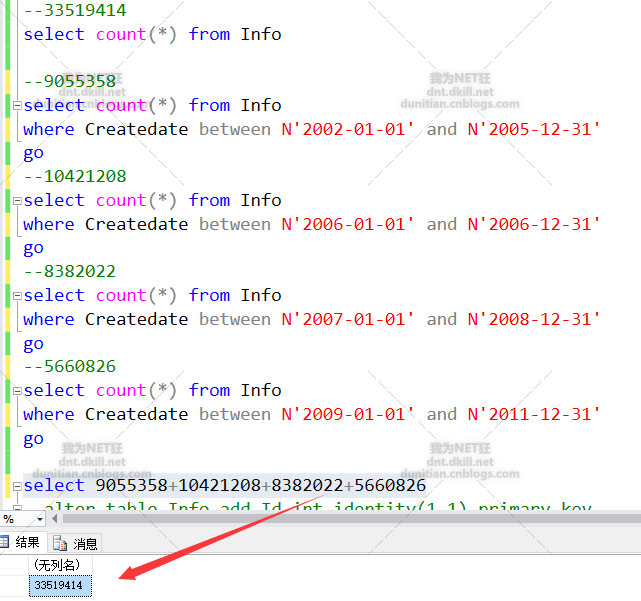
按数据量大致分一下
步入正轨
---------------------------------------------------------------------
GUI方法:
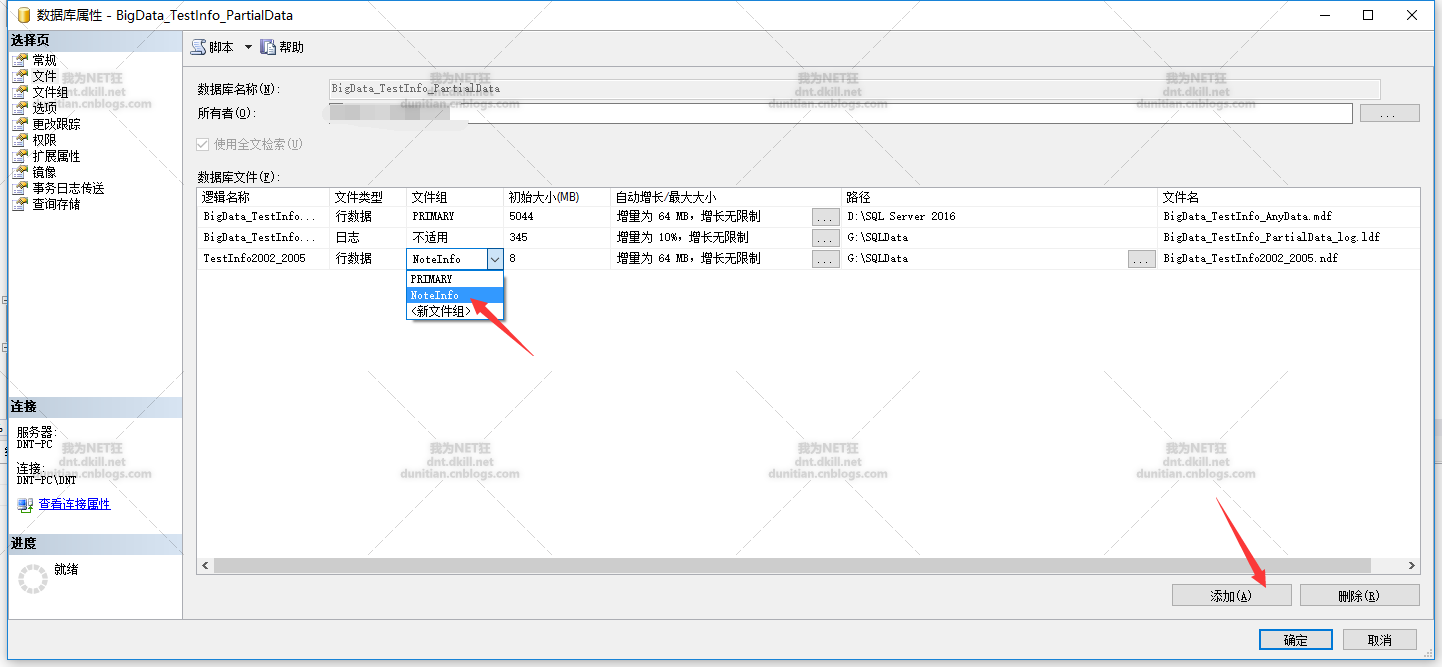
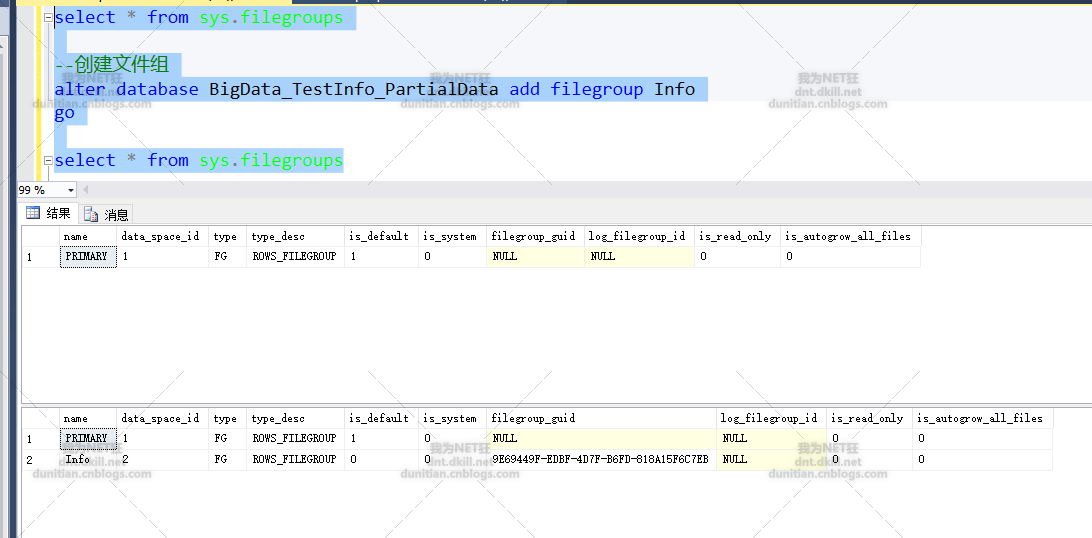
3.0创建文件组

添加文件到文件组
命令操作:
alter database BigData_TestInfo_PartialData add filegroup Info
alter database BigData_TestInfo_PartialData add file(name=N'TestInfo2006',filename=N'G:\SQLData\BigData_TestInfo2006.ndf') to filegroup Info
注意:BigData_TestInfo2006.ndf是数据库自己创建的,不需要自己手动创建(有些同志手动创建了,然后报错。。。。呃,有点哭笑不得了)
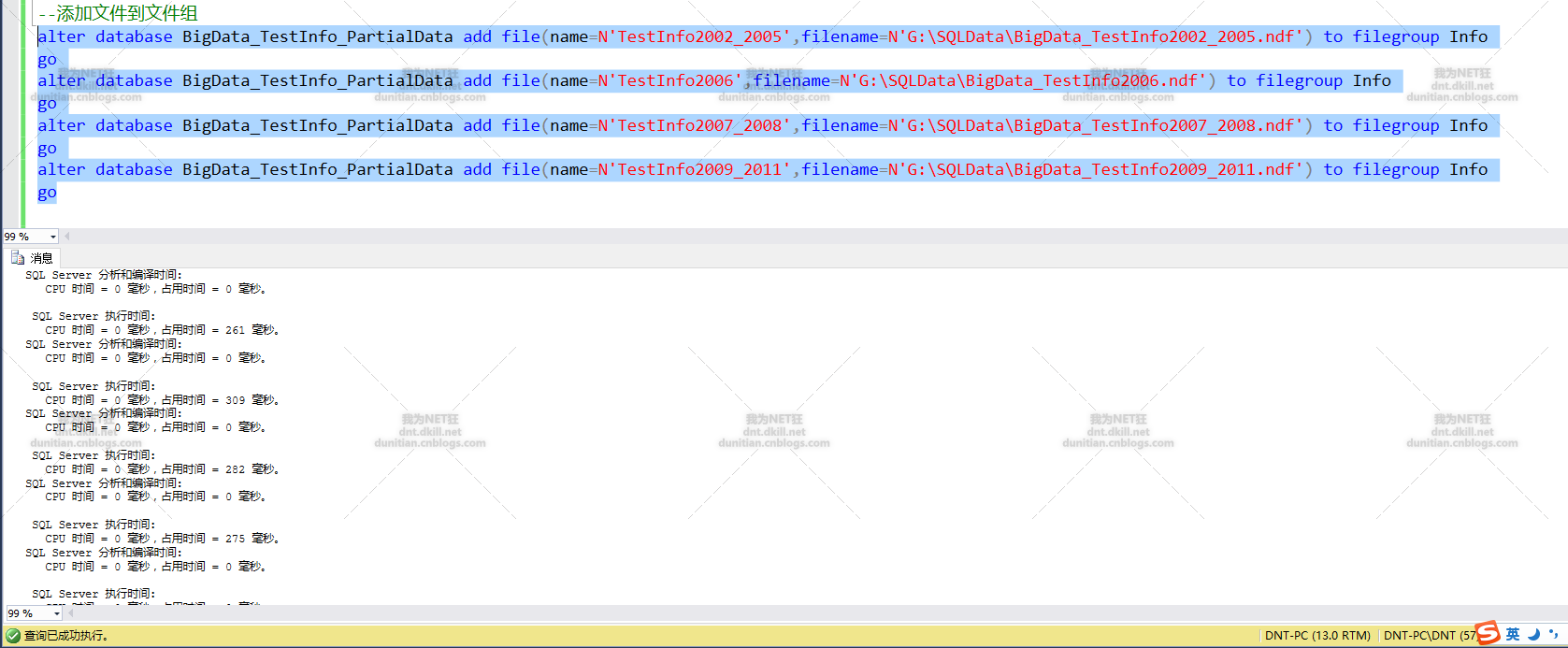
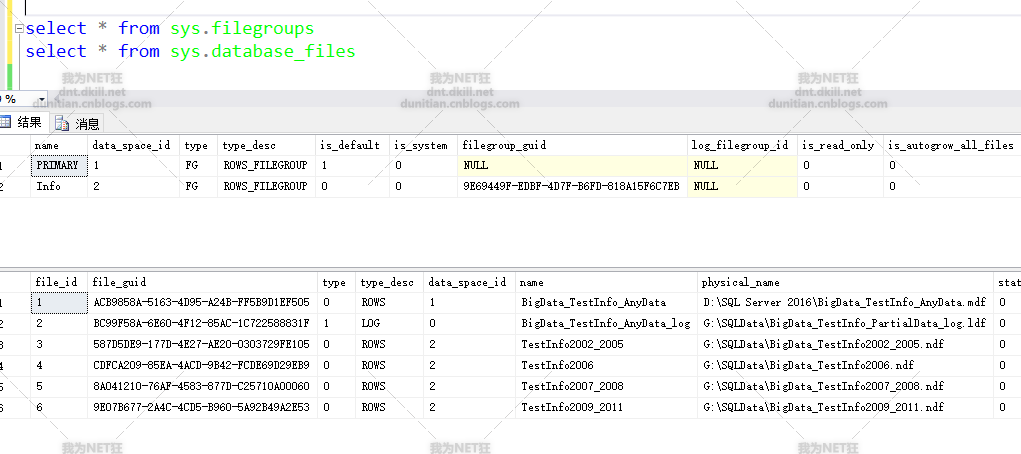
查询看看:select * from sys.filegroups
水平分区走起:一般就几步,1.创建分区函数 2.创建分区方案 3.创建分区表
GUI方法
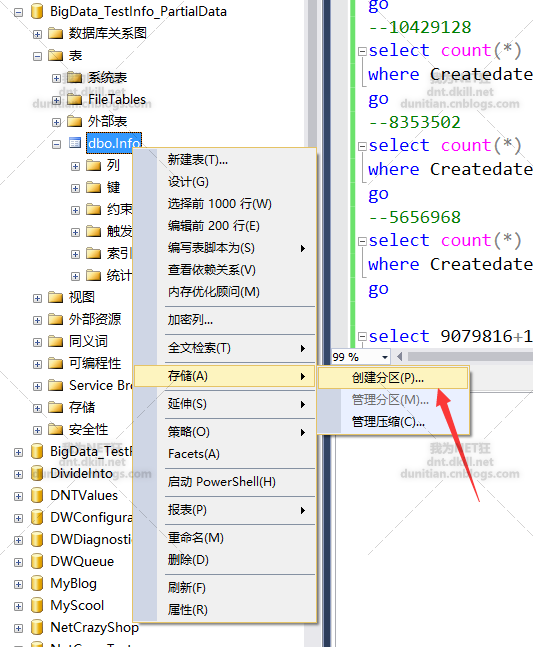
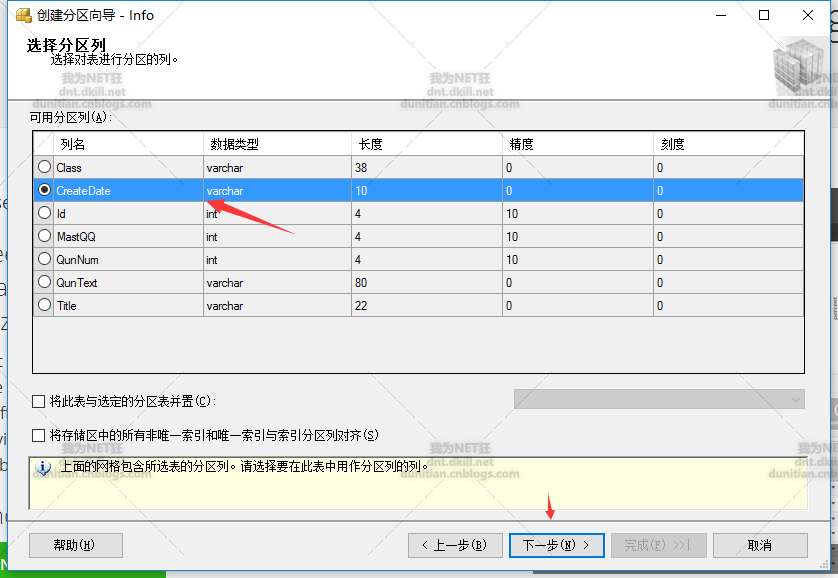
分区函数
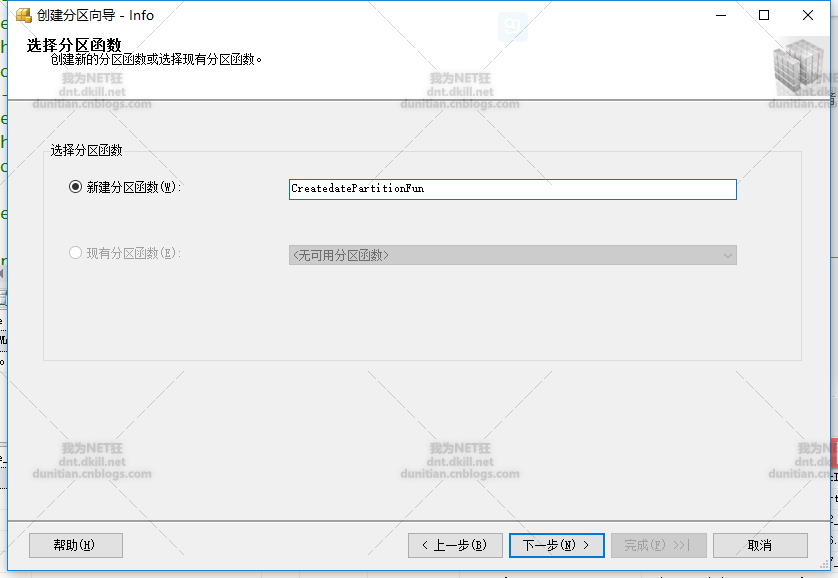
分区方案
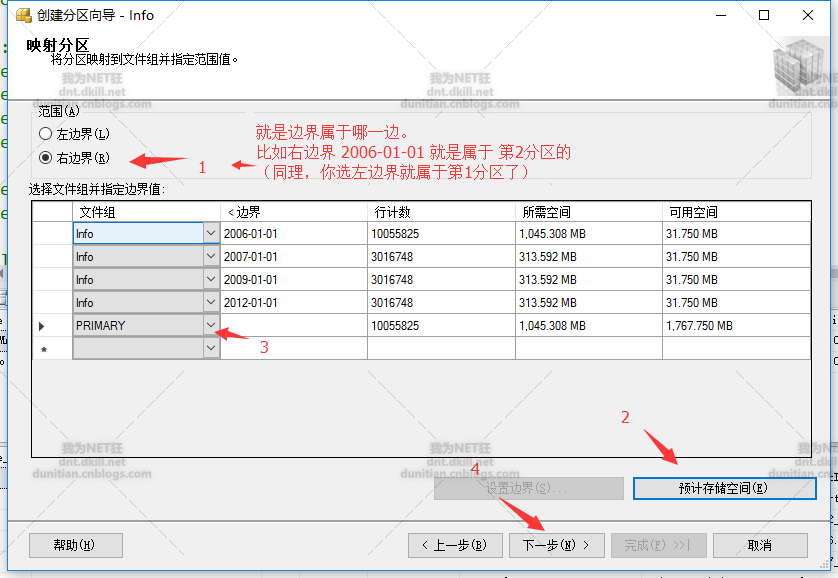
上一张图有些人可能不懂,用PPT画张概念图:
创建脚本
系统生成脚本:
use [BigData_TestInfo_PartialData]
go begin transaction create partition function [CreatedatePartitionFun](varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01') create partition scheme [CreatedatePartitionScheme] as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary]) alter table [dbo].[Info] drop constraint [PK__Info__3214EC07B2FE10C8] alter table [dbo].[Info] add primary key nonclustered
(
[Id] asc
)with (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] set ansi_padding on create clustered index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info]
(
[CreateDate]
)with (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [CreatedatePartitionScheme]([CreateDate]) drop index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info] commit transaction
go
命令方式创建(根据上面生成的命令逆推)
创建分区函数和架构(方案)
create partition function CreatedatePartitionFun(varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01')

create partition scheme CreatedatePartitionScheme as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary])
创建分区表
尚未创建表的情况

已经创建了表(基本上都是这种情况)
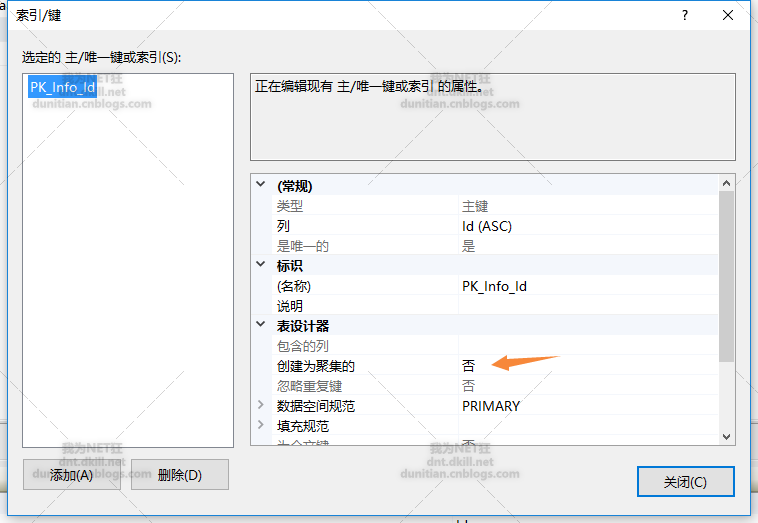
主要就两步,把主键变为非聚集索引+创建分区聚集索引
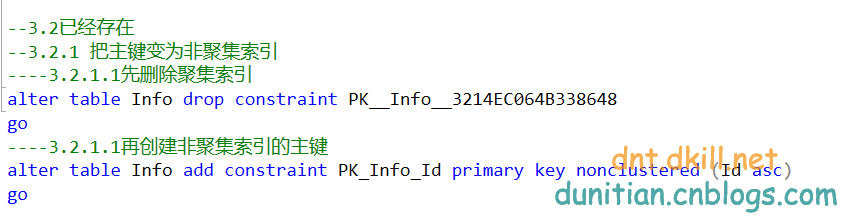
alter table Info drop constraint PK__Info__3214EC064B338648
alter table Info add constraint PK_Info_Id primary key nonclustered (Id asc)

create clustered index IX_Info_CreateDate on Info(CreateDate) on CreatedatePartitionScheme(CreateDate)
测试:基本上是均匀分散在各个文件中,生产环境的时候可以把这些文件放各个磁盘

参考文章:
http://www.cnblogs.com/gaizai/p/3582024.html
http://www.cnblogs.com/lyhabc/p/3480917.html
http://www.cnblogs.com/libingql/p/4087598.html
http://www.cnblogs.com/CareySon/p/3252670.html
http://database.51cto.com/art/201009/225448.htm
http://www.cnblogs.com/knowledgesea/p/3696912.html
http://www.cnblogs.com/CareySon/archive/2011/12/30/2307766.html
http://www.cnblogs.com/lykbk/p/erererert343243434388773437878.html
01.SQLServer性能优化之---水平分库扩展的更多相关文章
- 02.SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 第一次引入文件组的概念:http://www.cnblogs.com/dunitian/ ...
- SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 第一次引入文件组的概念:http://www.cnblogs.com/dunitia ...
- 01.SQLServer性能优化之----强大的文件组----分盘存储
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 文章内容皆自己的理解,如有不足之处欢迎指正~谢谢 前天有学弟问逆天:“逆天,有没有一种方 ...
- SQLServer性能优化专题
SQLServer性能优化专题 01.SQLServer性能优化之----强大的文件组----分盘存储(水平分库) http://www.cnblogs.com/dunitian/p/5276431. ...
- 02.SQLServer性能优化之---牛逼的OSQL----大数据导入
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 上一篇:01.SQLServer性能优化之----强大的文件组----分盘存储 http ...
- 03.SQLServer性能优化之---存储优化系列
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 概 述:http://www.cnblogs.com/dunitian/p/60413 ...
- SQLServer性能优化之---数据库级日记监控
上节回顾:https://www.cnblogs.com/dotnetcrazy/p/11029323.html 4.6.6.SQLServer监控 脚本示意:https://github.com/l ...
- Linux性能优化从入门到实战:01 Linux性能优化学习路线
我通过阅读各种相关书籍,从操作系统原理.到 Linux内核,再到硬件驱动程序等等. 把观察到的性能问题跟系统原理关联起来,特别是把系统从应用程序.库函数.系统调用.再到内核和硬件等不同的层级贯 ...
- SqlServer性能优化和工具Profiler(转)
合理的优化和熟练的运用Profiler会让你更好的掌握系统的sql语句和存储过程的效率 目录 第1章 如何打开SQL Server Profile. 3 第2章 SQL Server Profile. ...
随机推荐
- Photoshop将普通照片快速制作二次元漫画风格效果
今天为大家分享Photoshop将普通照片快速制作二次元漫画风格效果,教程很不错,对于喜欢漫画的朋友可以参考本文,希望能对大家有所帮助! 一提到日本动画电影,大家第一印象肯定是宫崎骏,但是日本除了宫崎 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- 拦截UIViewController的popViewController事件
实现拦截UIViewController的pop操作有两种方式: 自定义实现返回按钮,即设置UIBarButtonItem来实现自定义的返回操作. 创建UINavigatonController的Ca ...
- 解决 Could not find com.android.tools.build:gradle 问题
今天拉同事最新的代码,编译时老是报如下错误: Error:Could not find com.android.tools.build:gradle:2.2.0.Searched in the fol ...
- 什么是英特尔® Edison 模块?
英特尔® Edison 模块 是一种 SD 卡大小的微型计算芯片,专为构建物联网 (IoT) 和可穿戴计算产品而设计. Edison 模块内含一个高速的双核处理单元.集成 Wi-Fi*.蓝牙* 低能耗 ...
- 《Note --- Unreal 4 --- Sample analyze --- StrategyGame(continue...)》
---------------------------------------------------------------------------------------------------- ...
- EF里Guid类型数据的自增长、时间戳和复杂类型的用法
通过前两章Lodging和Destination类的演示,大家肯定基本了解Code First是怎么玩的了,本章继续演示一些很实用的东西.文章的开头提示下:提供的demo为了后面演示效果,前面代码有些 ...
- Webgl的2D开发方案(一)spritebatcher
使用TypeScript 和 webgl 开发 第一步:实现了SpriteBatcher 例子如下 http://oak2x0a9v.bkt.clouddn.com/test/index.html ...
- 访问IIS网站需要输入用户名密码(非匿名登录)问题汇总
无语了,最近不少Windows服务器都出现这个访问网站需要输入的问题,而且每次解决方法还不一样...唉,先汇总下解决方法吧,有时间再仔细研究下这些问题是如何导致的. 当IIS已启用"允许匿名 ...
- 「标准」的 JS风格
首先,这份 JS风格指南已经在我司的前端团队实行半年多了: 其次,在程序员的世界里,从入行到资深都需要面对几个世界级的难题,如: 世界上最好的编辑器是什么? 是用空格还是 TAB?用空格还特么衍生出 ...