02.SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql
第一次引入文件组的概念:http://www.cnblogs.com/dunitian/p/5276431.html
上次说了其他的解决方案(http://www.cnblogs.com/dunitian/p/6041745.html),就是没有说水平分库,这次好好说下。
上次共享的第一份大数据,这次正好来演示一下水平分库
1.模拟部分数据
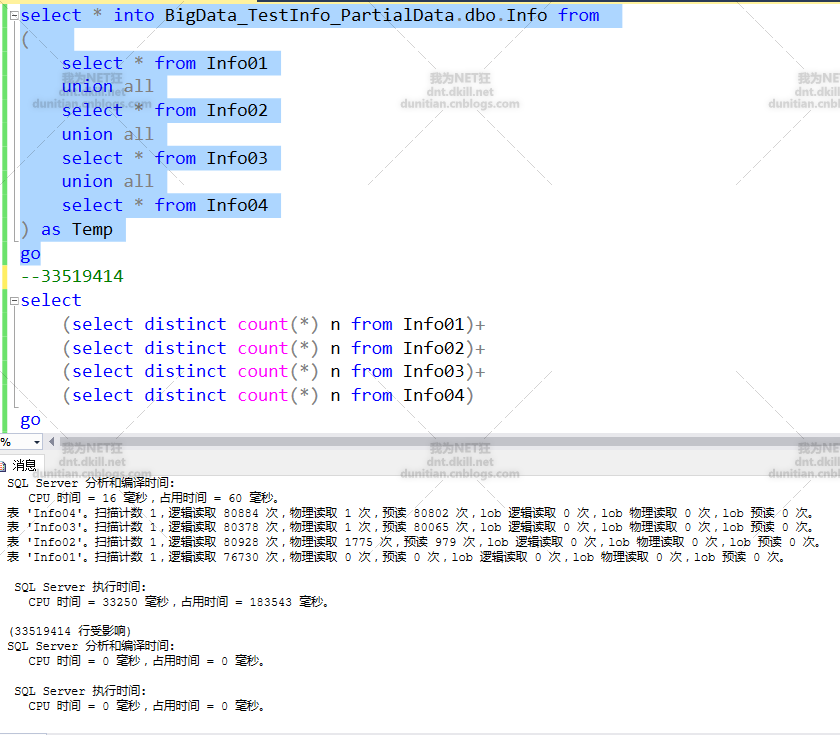
2.创建索引后,发现可以根据日期来分组
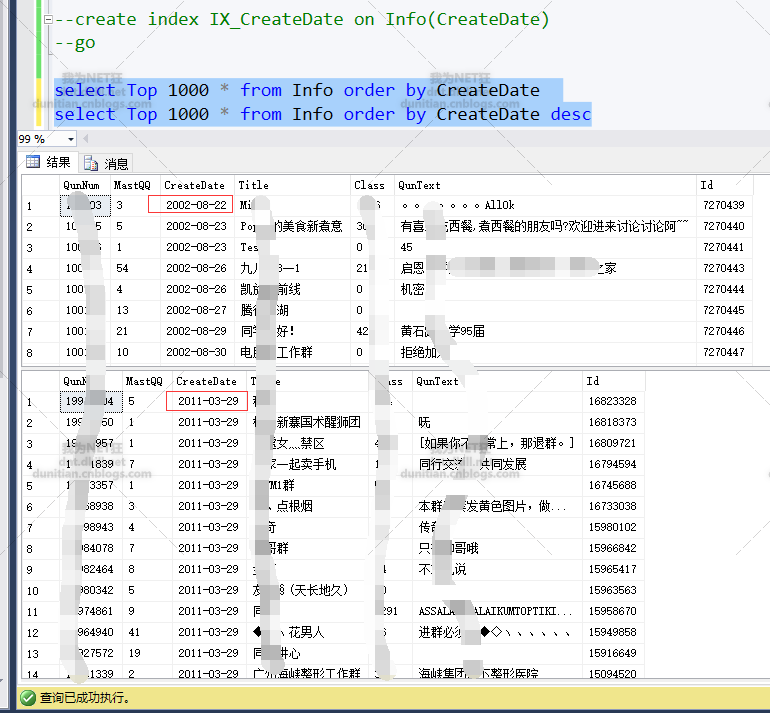
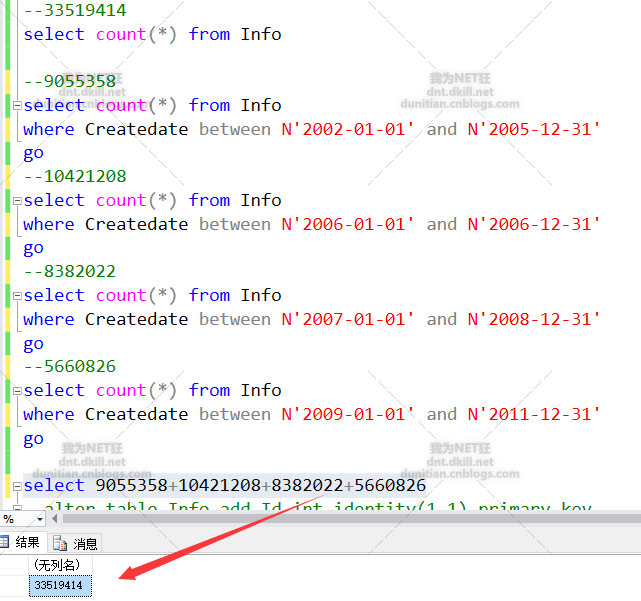
按数据量大致分一下
步入正轨
---------------------------------------------------------------------
GUI方法:
3.0创建文件组

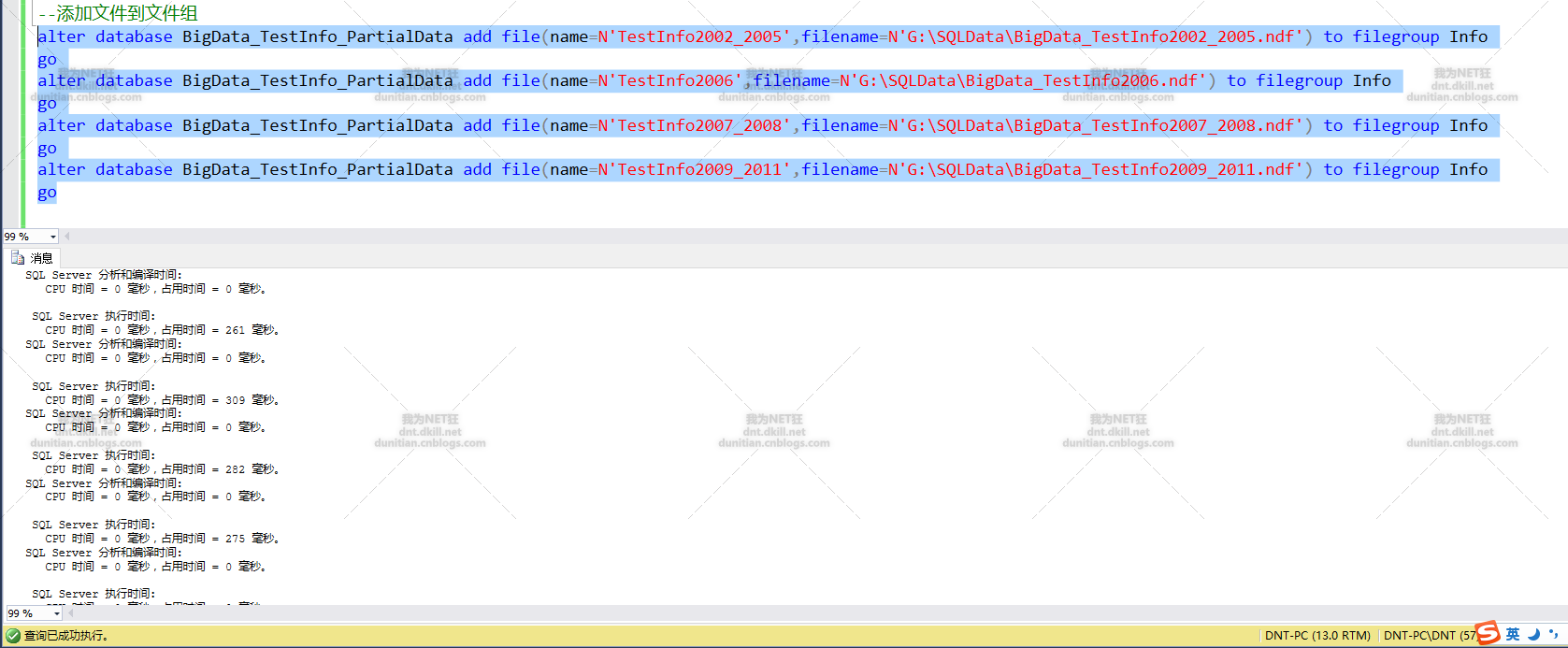
添加文件到文件组
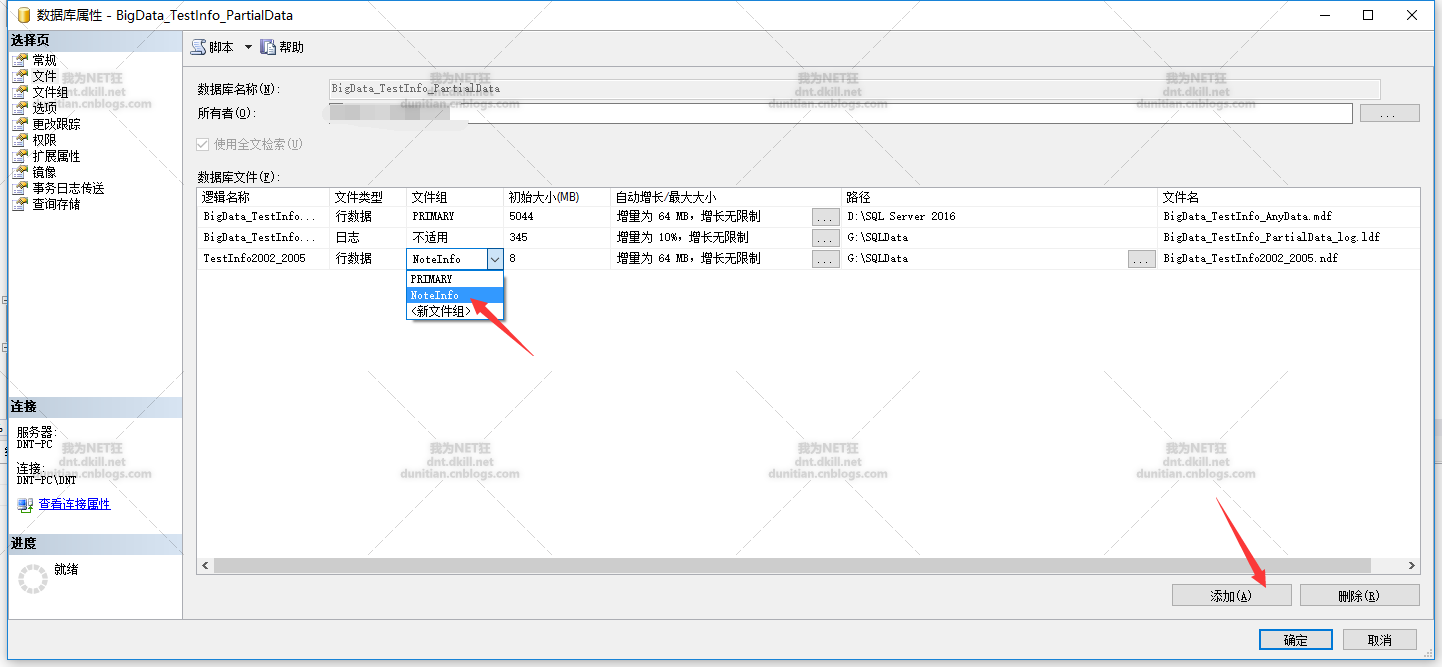
命令操作:
alter database BigData_TestInfo_PartialData add filegroup Info
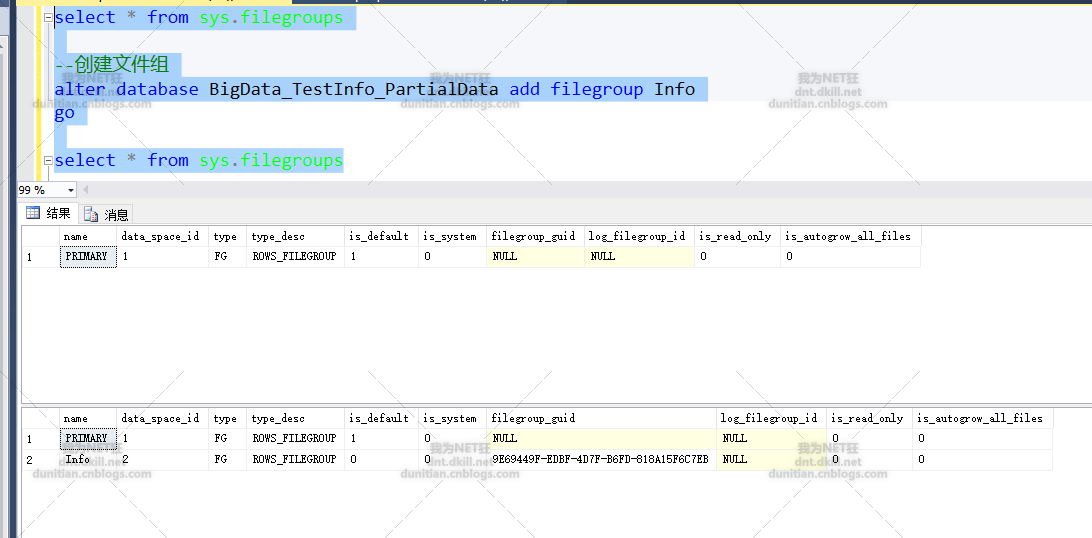
alter database BigData_TestInfo_PartialData add file(name=N'TestInfo2006',filename=N'G:\SQLData\BigData_TestInfo2006.ndf') to filegroup Info
注意:BigData_TestInfo2006.ndf是数据库自己创建的,不需要自己手动创建(有些同志手动创建了,然后报错。。。。呃,有点哭笑不得了)
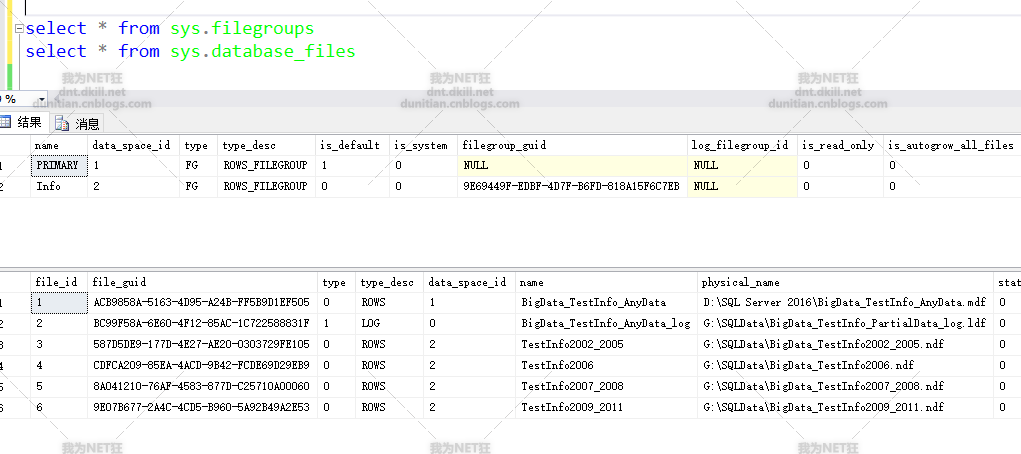
查询看看:select * from sys.filegroups
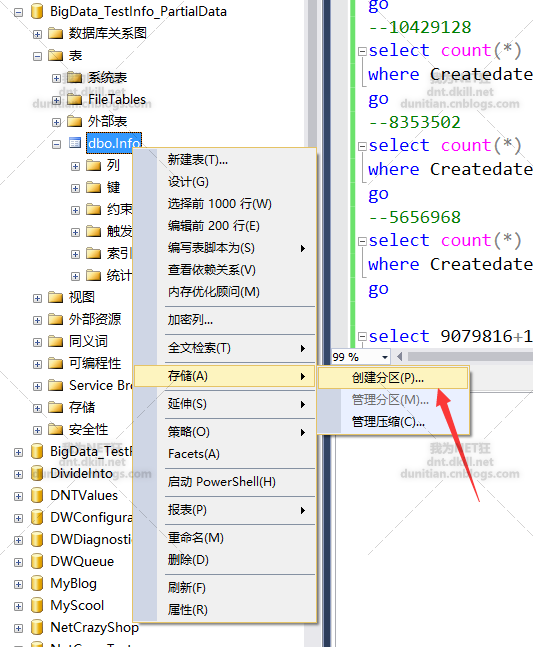
水平分区走起:一般就几步,1.创建分区函数 2.创建分区方案 3.创建分区表
GUI方法
分区函数
分区方案
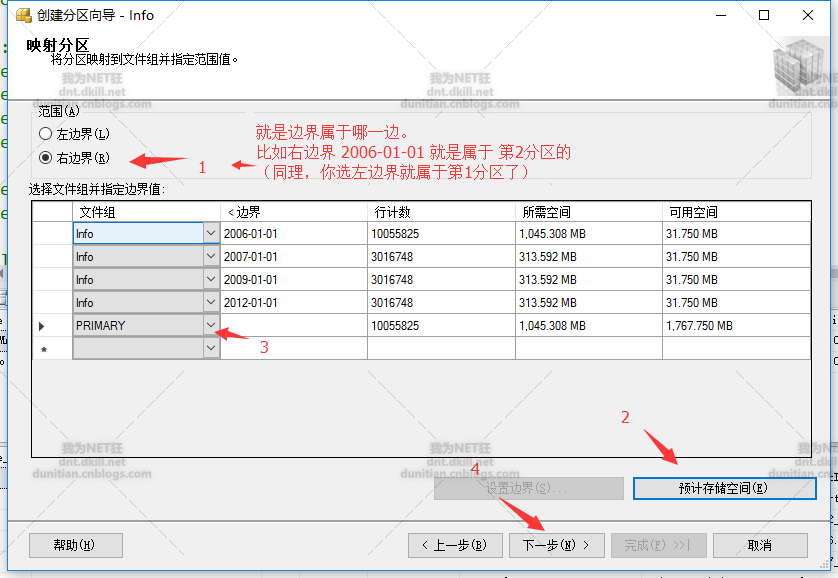
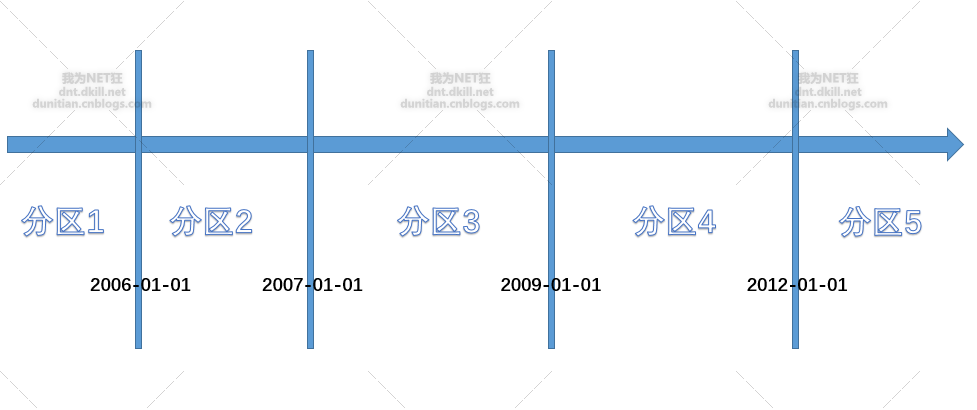
上一张图有些人可能不懂,用PPT画张概念图:
创建脚本
系统生成脚本:
use [BigData_TestInfo_PartialData]
go begin transaction create partition function [CreatedatePartitionFun](varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01') create partition scheme [CreatedatePartitionScheme] as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary]) alter table [dbo].[Info] drop constraint [PK__Info__3214EC07B2FE10C8] alter table [dbo].[Info] add primary key nonclustered
(
[Id] asc
)with (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] set ansi_padding on create clustered index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info]
(
[CreateDate]
)with (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [CreatedatePartitionScheme]([CreateDate]) drop index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info] commit transaction
go
命令方式创建(根据上面生成的命令逆推)
创建分区函数和架构(方案)
create partition function CreatedatePartitionFun(varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01')

create partition scheme CreatedatePartitionScheme as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary])
创建分区表
尚未创建表的情况

已经创建了表(基本上都是这种情况)
主要就两步,把主键变为非聚集索引+创建分区聚集索引
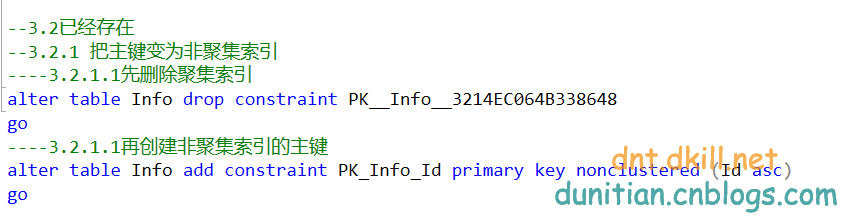
alter table Info drop constraint PK__Info__3214EC064B338648
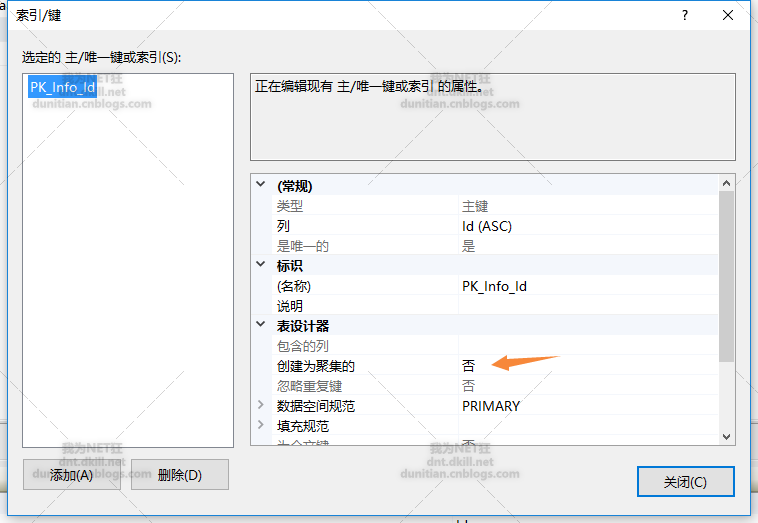
alter table Info add constraint PK_Info_Id primary key nonclustered (Id asc)

create clustered index IX_Info_CreateDate on Info(CreateDate) on CreatedatePartitionScheme(CreateDate)
测试:基本上是均匀分散在各个文件中,生产环境的时候可以把这些文件放各个磁盘

参考文章:
http://www.cnblogs.com/gaizai/p/3582024.html
http://www.cnblogs.com/lyhabc/p/3480917.html
http://www.cnblogs.com/libingql/p/4087598.html
http://www.cnblogs.com/CareySon/p/3252670.html
http://database.51cto.com/art/201009/225448.htm
http://www.cnblogs.com/knowledgesea/p/3696912.html
http://www.cnblogs.com/CareySon/archive/2011/12/30/2307766.html
http://www.cnblogs.com/lykbk/p/erererert343243434388773437878.html
02.SQLServer性能优化之---水平分库扩展的更多相关文章
- 01.SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 第一次引入文件组的概念:http://www.cnblogs.com/dunitian/ ...
- SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 第一次引入文件组的概念:http://www.cnblogs.com/dunitia ...
- 02.SQLServer性能优化之---牛逼的OSQL----大数据导入
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 上一篇:01.SQLServer性能优化之----强大的文件组----分盘存储 http ...
- SQLServer性能优化专题
SQLServer性能优化专题 01.SQLServer性能优化之----强大的文件组----分盘存储(水平分库) http://www.cnblogs.com/dunitian/p/5276431. ...
- 01.SQLServer性能优化之----强大的文件组----分盘存储
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 文章内容皆自己的理解,如有不足之处欢迎指正~谢谢 前天有学弟问逆天:“逆天,有没有一种方 ...
- 03.SQLServer性能优化之---存储优化系列
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 概 述:http://www.cnblogs.com/dunitian/p/60413 ...
- SQLServer性能优化之---数据库级日记监控
上节回顾:https://www.cnblogs.com/dotnetcrazy/p/11029323.html 4.6.6.SQLServer监控 脚本示意:https://github.com/l ...
- SqlServer性能优化和工具Profiler(转)
合理的优化和熟练的运用Profiler会让你更好的掌握系统的sql语句和存储过程的效率 目录 第1章 如何打开SQL Server Profile. 3 第2章 SQL Server Profile. ...
- SqlServer性能优化 查询和索引优化(十二)
查询优化的过程: 查询优化: 功能:分析语句后最终生成执行计划 分析:获取操作语句参数 索引选择 Join算法选择 创建测试的表: select * into EmployeeOp from Adve ...
随机推荐
- 实践中 XunSearch(讯搜)的使用教程步骤
XunSearch(讯搜)的使用教程步骤 一.安装编译工具 yum install make gcc g++ gcc-c++ libtool autoconf automake imake mysql ...
- 【原创】IO流:读写操作研究(输入流)
默写代码(以下问题要求能默写,不翻书不百度) 输入 问题一:从文件abc.txt中读取数据到字节数组并打印出来. 分析:如果读取数据,首先第一个问题,数据有多少?如果数据量不确定,如果确定字节数组大小 ...
- centos 安装部署zabbix
Zabbix_server初始安装部署 各模块要安装的模块 Server:server+nginx+mysql+php Agentd:agentd Proxy:proxy+mysql 1.准备环境: ...
- 转 Refresh Excel Pivot Tables Automatically Using SSIS Script Task
Refresh Excel Pivot Tables Automatically Using SSIS Script Task https://www.mssqltips.com/sqlservert ...
- codeforces 1066 B heater
菜鸡只配做水题 思路就很简单嘛:肯定扩展的越靠后边越好了 0 0 1 0 1 1 0 0 假设范围是3 ,第一个1一定要选上,第2.3个肯定选3啦,越靠后边就一定能节省更多的点,没看出来和子问题有什么 ...
- [ 10.4 ]CF每日一题系列—— 486C
Description: 给你一个指针,可以左右移动,指向的小写字母可以,改变,但都是有花费的a - b 和 a - z花费1,指针移动也要花费,一个单位花费1,问你把当前字符串变成回文串的最小化费是 ...
- kubernets基础
1.定义和功能. 1.1定义:kubernets解释为舵手或者飞行员,以Borg为主衍生出. 1.2功能:自动装箱,自我修复,水平扩展,服务发现和负载均衡,自动发布和回滚. 密钥和配置管理,存储编排, ...
- JAVA程序CPU 100%问题排查
做JAVA开发的同学一定遇到过的爆表问题,看这里解决 https://www.cnblogs.com/qcloud1001/p/9773947.html 本文由净地发表于云+社区专栏 记一次Ja ...
- eclipse运行spark程序时日志颜色为黑色的解决办法
自从开始学习spark计算框架以来,我们老师教的是local模式下用eclipse运行spark程序,然后我在运行spark程序时,发现控制台的日志颜色总是显示为黑色,哇,作为程序猿总有一种强迫症,发 ...
- Javascript高级编程学习笔记(52)—— DOM2和DOM3(4)元素大小
在日常实践中,我们在使用JS的时候难免会需要获取元素的大小及位置 首先要声明的是,这一部分的内容并不属于DOM2样式规范,因为DOM中并没有对我们如何获取元素大小的相关信息做出规范 偏移量 偏移量及元 ...