制作并量化GGUF模型上传到HuggingFace和ModelScope
llama.cpp 是 Ollama、LMStudio 和其他很多热门项目的底层实现,也是 GPUStack 所支持的推理引擎之一,它提供了 GGUF 模型文件格式。GGUF (General Gaussian U-Net Format) 是一种用于存储模型以进行推理的文件格式,旨在针对推理进行优化,可以快速加载和运行模型。
llama.cpp 还支持量化模型,在保持较高的模型精度的同时,减少模型的存储和计算需求,使大模型能够在桌面端、嵌入式设备和资源受限的环境中高效部署,并提高推理速度。
今天带来一篇介绍如何制作并量化 GGUF 模型,将模型上传到 HuggingFace 和 ModelScope 模型仓库的操作教程。
注册与配置 HuggingFace 和 ModelScope
- 注册 HuggingFace
访问 https://huggingface.co/join 注册 HuggingFace 账号(需要某上网条件)
- 配置 HuggingFace SSH 公钥
将本地环境的 SSH 公钥添加到 HuggingFace,查看本地环境的 SSH 公钥(如果没有可以用 ssh-keygen -t rsa -b 4096 命令生成):
cat ~/.ssh/id_rsa.pub
在 HuggingFace 的右上角点击头像,选择 Settings - SSH and GPG Keys,添加上面的公钥,用于后面上传模型时的认证。
- 注册 ModelScope
访问 https://www.modelscope.cn/register?back=%2Fhome 注册 ModelScope 账号
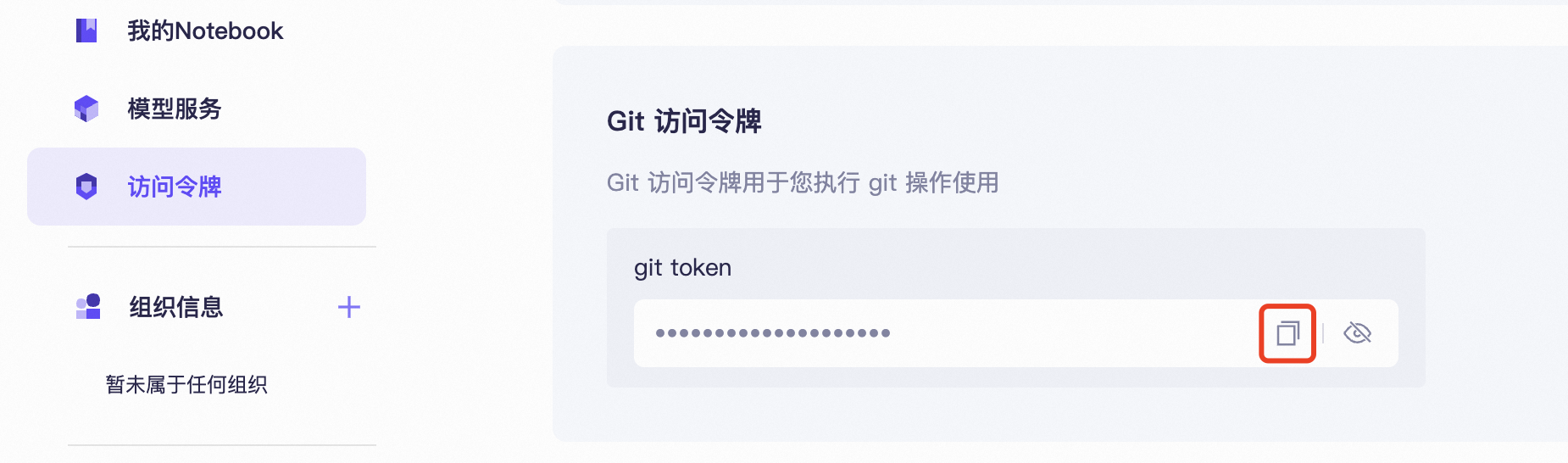
- 获取 ModelScope Token
访问 https://www.modelscope.cn/my/myaccesstoken,将 Git 访问令牌复制保存,用于后面上传模型时的认证。
准备 llama.cpp 环境
创建并激活 Conda 环境(没有安装的参考 Miniconda 安装:https://docs.anaconda.com/miniconda/):
conda create -n llama-cpp python=3.12 -y
conda activate llama-cpp
which python
pip -V
克隆 llama.cpp 的最新分支代码,编译量化所需的二进制文件:
cd ~
git clone -b b4034 https://github.com/ggerganov/llama.cpp.git
cd llama.cpp/
pip install -r requirements.txt
brew install cmake
make

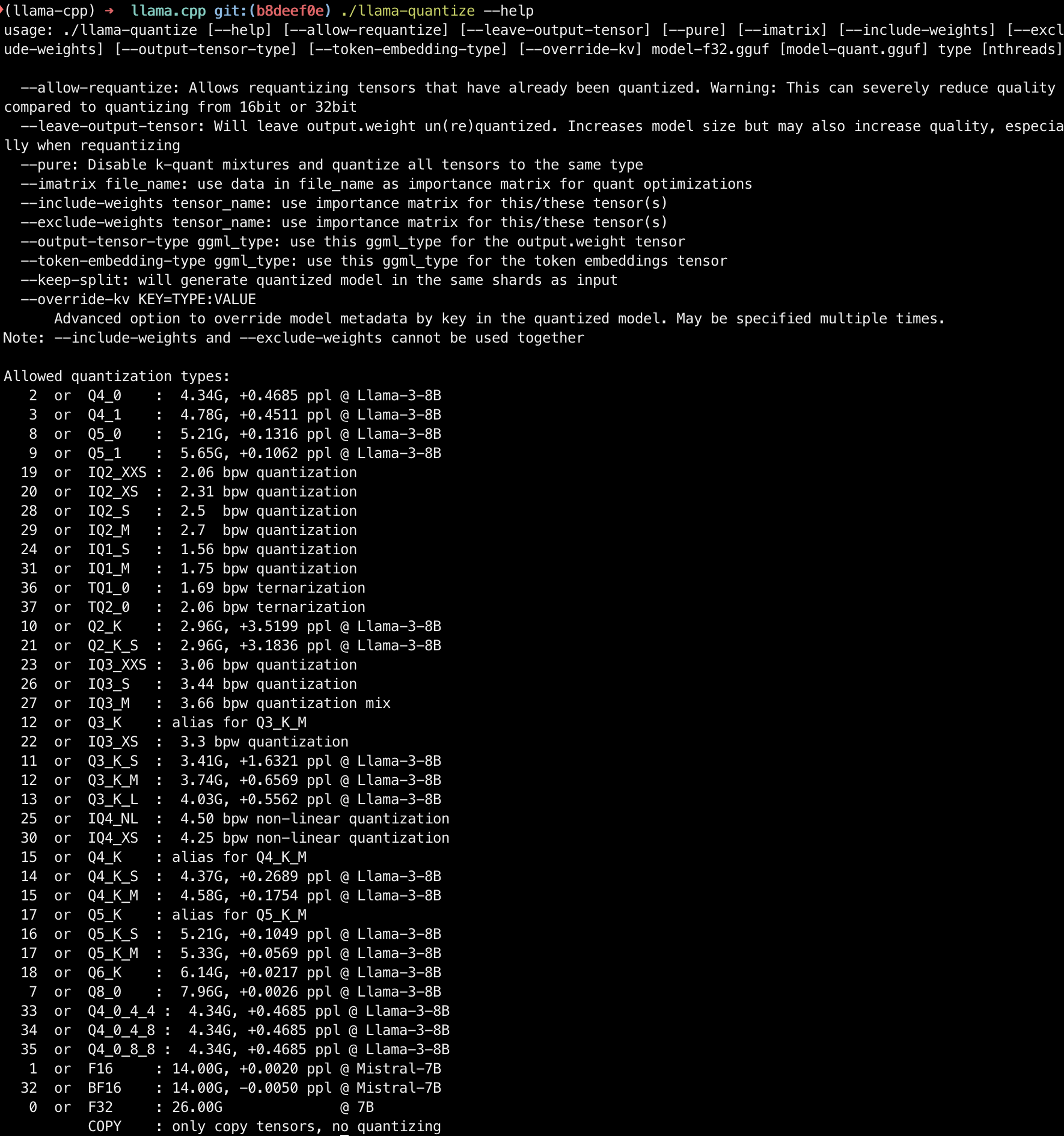
编译完成后,可以运行以下命令确认量化所需要的二进制文件 llama-quantize 是否可用:
./llama-quantize --help
下载原始模型
下载需要转换为 GGUF 格式并量化的原始模型。
从 HuggingFace 下载模型,通过 HuggingFace 提供的 huggingface-cli 命令下载,首先安装依赖:
pip install -U huggingface_hub
国内网络配置下载镜像源:
export HF_ENDPOINT=https://hf-mirror.com
这里下载 meta-llama/Llama-3.2-3B-Instruct 模型,该模型是 Gated model,需要在 HuggingFace 填写申请并确认获得访问授权:
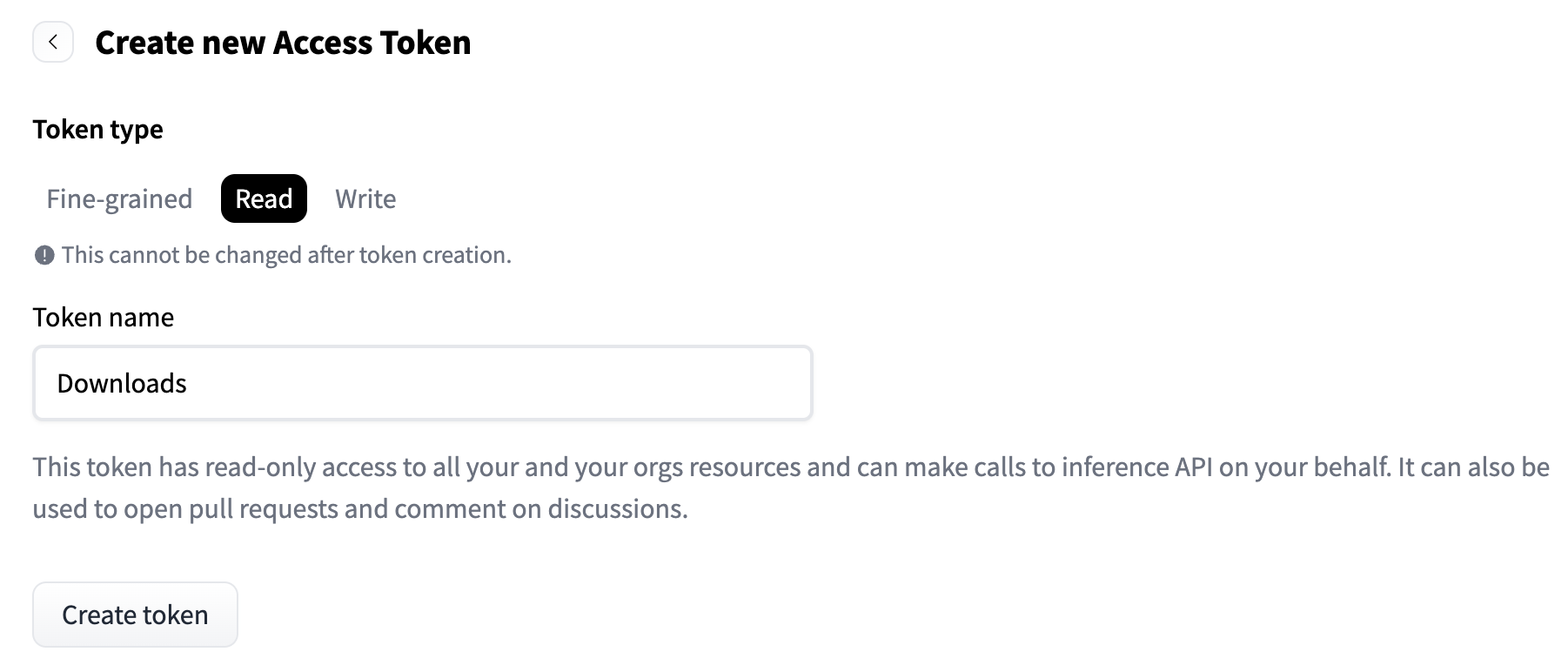
在 HuggingFace 的右上角点击头像,选择 Access Tokens,创建一个 Read 权限的 Token,保存下来:
下载 meta-llama/Llama-3.2-3B-Instruct 模型,--local-dir 指定保存到当前目录,--token 指定上面创建的访问 Token:
mkdir ~/huggingface.co
cd ~/huggingface.co/
huggingface-cli download meta-llama/Llama-3.2-3B-Instruct --local-dir Llama-3.2-3B-Instruct --token hf_abcdefghijklmnopqrstuvwxyz
转换为 GGUF 格式与量化模型
创建 GGUF 格式与量化模型的脚本:
cd ~/huggingface.co/
vim quantize.sh
填入以下脚本内容,并把 llama.cpp 和 huggingface.co 的目录路径修改为当前环境的实际路径,需要为绝对路径,将 d 变量中的 gpustack 修改为 HuggingFace 用户名:
#!/usr/bin/env bash
llama_cpp="/Users/gpustack/llama.cpp"
b="/Users/gpustack/huggingface.co"
export PATH="$PATH:${llama_cpp}"
s="$1"
n="$(echo "${s}" | cut -d'/' -f2)"
d="gpustack/${n}-GGUF"
# prepare
mkdir -p ${b}/${d} 1>/dev/null 2>&1
pushd ${b}/${d} 1>/dev/null 2>&1
git init . 1>/dev/null 2>&1
if [[ ! -f .gitattributes ]]; then
cp -f ${b}/${s}/.gitattributes . 1>/dev/null 2>&1 || true
echo "*.gguf filter=lfs diff=lfs merge=lfs -text" >> .gitattributes
fi
if [[ ! -d assets ]]; then
cp -rf ${b}/${s}/assets . 1>/dev/null 2>&1 || true
fi
if [[ ! -d images ]]; then
cp -rf ${b}/${s}/images . 1>/dev/null 2>&1 || true
fi
if [[ ! -d imgs ]]; then
cp -rf ${b}/${s}/imgs . 1>/dev/null 2>&1 || true
fi
if [[ ! -f README.md ]]; then
cp -f ${b}/${s}/README.md . 1>/dev/null 2>&1 || true
fi
set -e
pushd ${llama_cpp} 1>/dev/null 2>&1
# convert
[[ -f venv/bin/activate ]] && source venv/bin/activate
echo "#### convert_hf_to_gguf.py ${b}/${s} --outfile ${b}/${d}/${n}-FP16.gguf"
python3 convert_hf_to_gguf.py ${b}/${s} --outfile ${b}/${d}/${n}-FP16.gguf
# quantize
qs=(
"Q8_0"
"Q6_K"
"Q5_K_M"
"Q5_0"
"Q4_K_M"
"Q4_0"
"Q3_K"
"Q2_K"
)
for q in "${qs[@]}"; do
echo "#### llama-quantize ${b}/${d}/${n}-FP16.gguf ${b}/${d}/${n}-${q}.gguf ${q}"
llama-quantize ${b}/${d}/${n}-FP16.gguf ${b}/${d}/${n}-${q}.gguf ${q}
ls -lth ${b}/${d}
sleep 3
done
popd 1>/dev/null 2>&1
set +e
开始将模型转换为 FP16 精度的 GGUF 模型,并分别用 Q8_0、Q6_K、Q5_K_M、Q5_0、Q4_K_M、Q4_0、Q3_K、Q2_K 方法来量化模型:
bash quantize.sh Llama-3.2-3B-Instruct
脚本执行完后,确认成功转换为 FP16 精度的 GGUF 模型和量化后的 GGUF 模型:
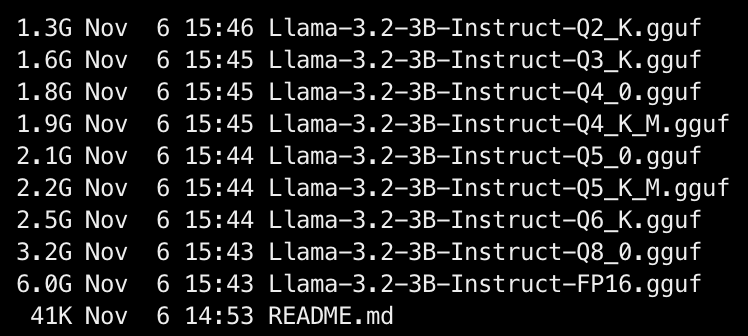
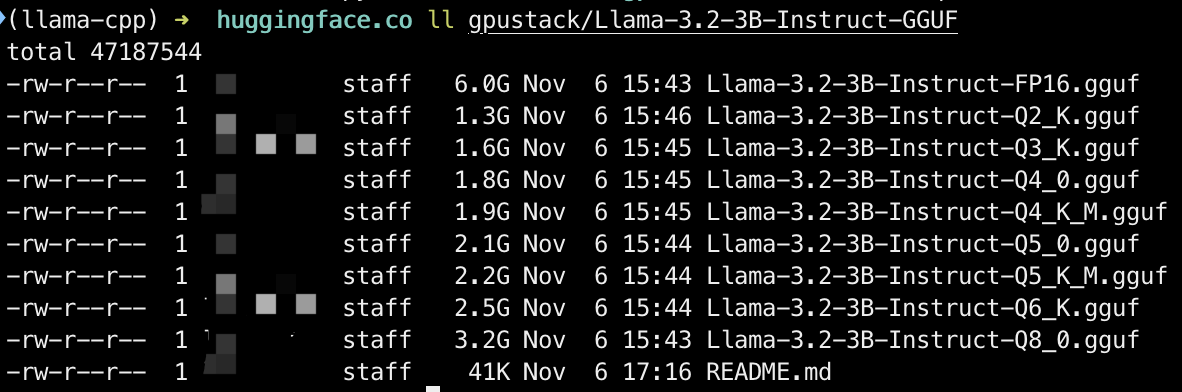
模型被存储在对应用户名的目录下:
ll gpustack/Llama-3.2-3B-Instruct-GGUF/
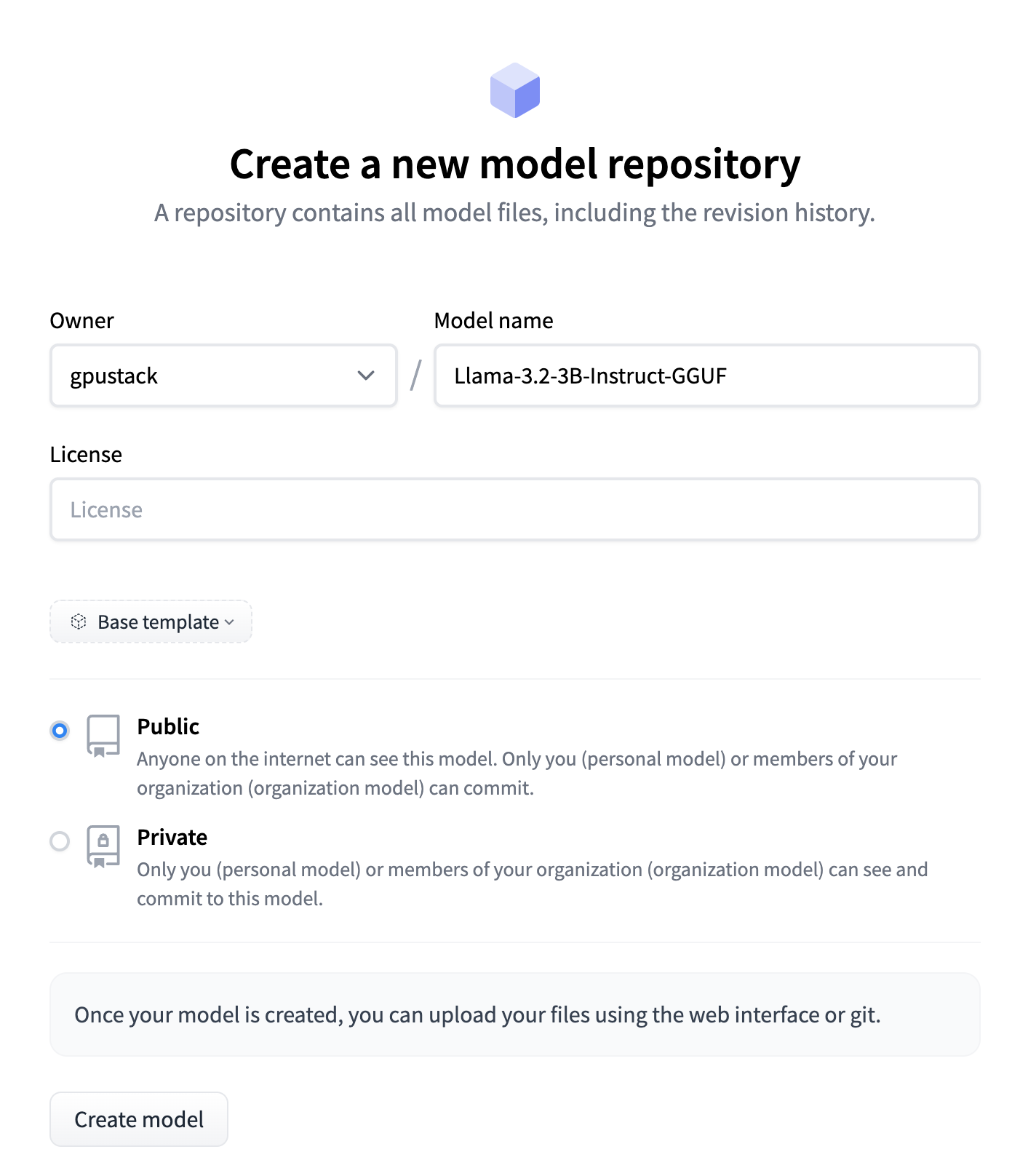
上传模型到 HuggingFace
在 HuggingFace 右上角点击头像,选择 New Model 创建同名的模型仓库,格式为 原始模型名-GGUF:
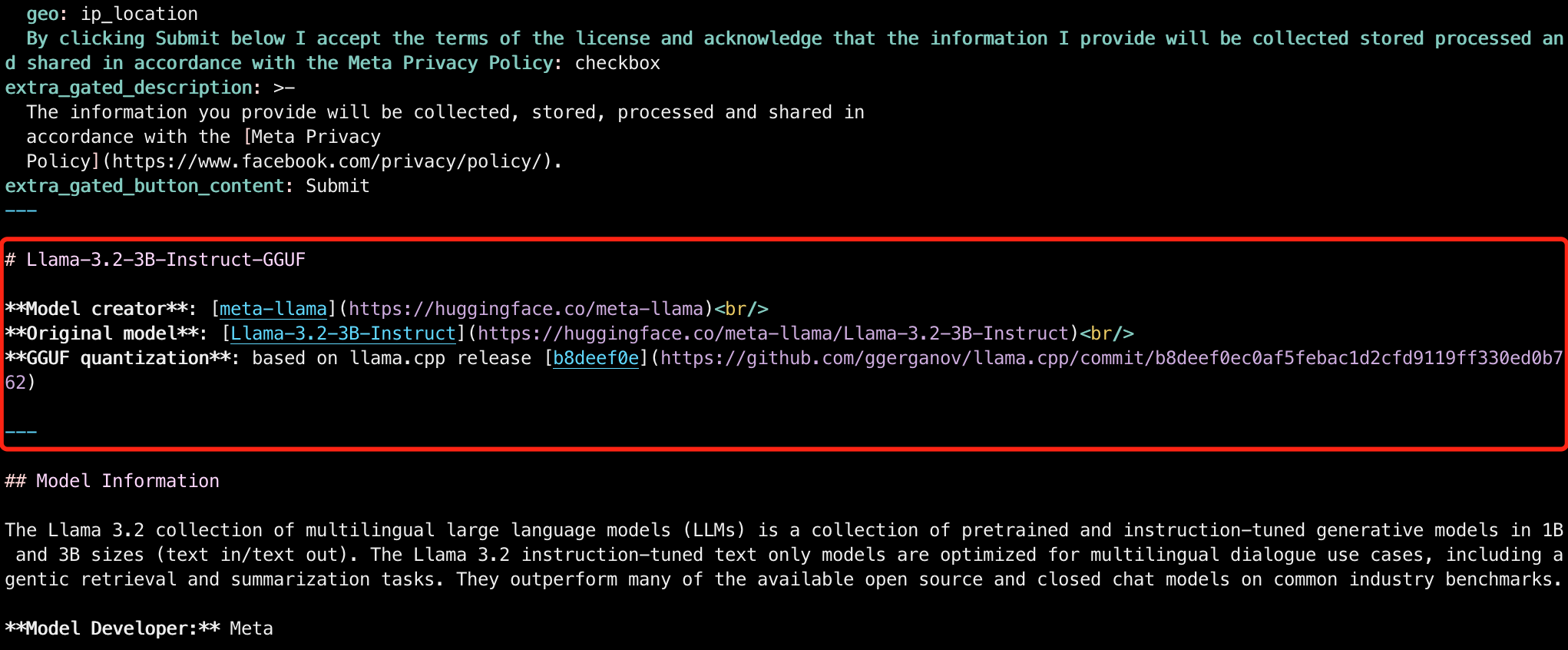
更新模型的 README:
cd ~/huggingface.co/gpustack/Llama-3.2-3B-Instruct-GGUF
vim README.md
为了维护性,在开头的元数据之后,记录原始模型和 llama.cpp 的分支代码 Commit 信息,注意按照原始模型的信息和llama.cpp 的分支代码 Commit 信息更改:
# Llama-3.2-3B-Instruct-GGUF
**Model creator**: [meta-llama](https://huggingface.co/meta-llama)<br/>
**Original model**: [Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct)<br/>
**GGUF quantization**: based on llama.cpp release [b8deef0e](https://github.com/ggerganov/llama.cpp/commit/b8deef0ec0af5febac1d2cfd9119ff330ed0b762)
---
准备上传,安装 Git LFS 用于管理大文件的上传:
brew install git-lfs
添加远程仓库:
git remote add origin git@hf.co:gpustack/Llama-3.2-3B-Instruct-GGUF
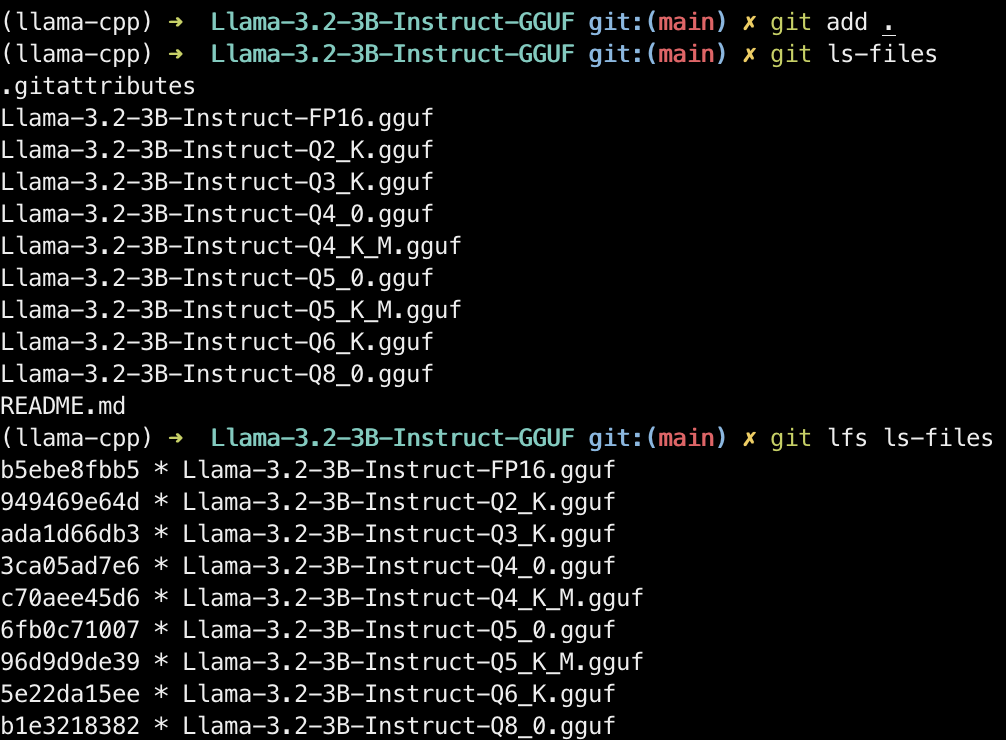
添加文件,并通过 git ls-files 确认提交的文件, git lfs ls-files 确认所有 .gguf 文件被 Git LFS 管理上传:
git add .
git ls-files
git lfs ls-files
上传超过 5GB 大小的文件到 HuggingFace 需开启大文件上传,在命令行登录 HuggingFace,输入上面下载模型章节创建的 Token:
huggingface-cli login
为当前目录开启大文件上传:
huggingface-cli lfs-enable-largefiles .

将模型上传到 HuggingFace 仓库:
git commit -m "feat: first commit" --signoff
git push origin main -f
上传完成后,在 HuggingFace 确认模型文件成功上传。
上传模型到 ModelScope
在 ModelScope 右上角点击头像,选择 创建模型 创建同名的模型仓库,格式为 原始模型名-GGUF,并填写 License、模型类型、AI 框架、是否公开模型等其他配置:
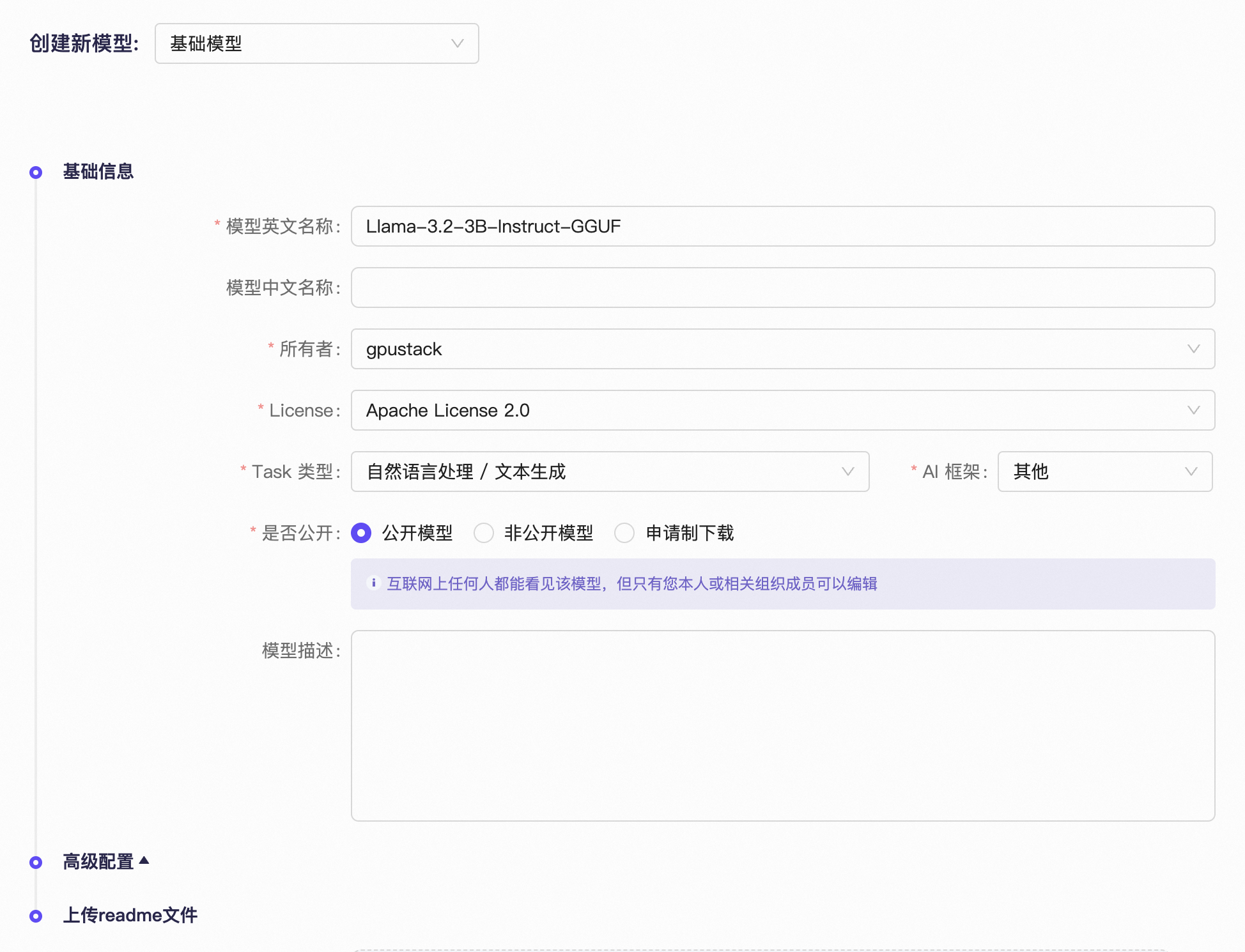
上传本地仓库的 README.md 文件并创建:

添加远程仓库,需要使用本文最开始获得的 ModelScope Git 访问令牌提供上传模型时的认证:
git remote add modelscope https://oauth2:xxxxxxxxxxxxxxxxxxxx@www.modelscope.cn/gpustack/Llama-3.2-3B-Instruct-GGUF.git
获取远端仓库已存在的文件:
git fetch modelscope master
由于 ModelScope 使用 master 分支而非 main 分支,需要切换到 master 分支并通过 cherry-pick 将main 下的文件移到 master 分支,先查看并记下当前的 Commit ID:
git log
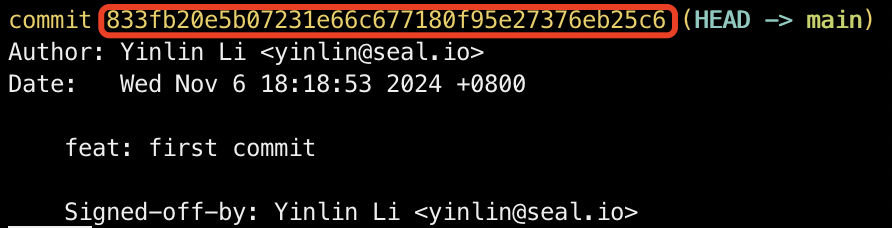
切换到 master 分支,并通过 main 分支的 Commit ID 将main 分支下的文件移到 master 分支:
git checkout FETCH_HEAD -b master
git cherry-pick -n 833fb20e5b07231e66c677180f95e27376eb25c6
修改冲突文件,解决冲突(可以用原始模型的 .gitattributes 合并 *.gguf filter=lfs diff=lfs merge=lfs -text,参考 quantize.sh 脚本相关逻辑 ):
vim .gitattributes
添加文件,并通过 git ls-files 确认提交的文件, git lfs ls-files 确认所有 .gguf 文件被 Git LFS 管理上传:
git add .
git ls-files
git lfs ls-files
将模型上传到 ModelScope 仓库:
git commit -m "feat: first commit" --signoff
git push modelscope master -f
上传完成后,在 ModelScope 确认模型文件成功上传。
总结
以上为使用 llama.cpp 制作并量化 GGUF 模型,并将模型上传到 HuggingFace 和 ModelScope 模型仓库的操作教程。
llama.cpp 的灵活性和高效性使得其成为资源有限场景下模型推理的理想选择,应用十分广泛,GGUF 是 llama.cpp 运行模型所需的模型文件格式,希望以上教程能对如何管理 GGUF 模型文件有所帮助。
如果觉得写得不错,欢迎点赞、转发、关注。
制作并量化GGUF模型上传到HuggingFace和ModelScope的更多相关文章
- Android如何制作自己的依赖库上传至github供别人下载使用
Android如何制作自己的依赖库上传至github供别人下载使用 https://blog.csdn.net/xuchao_blog/article/details/62893851
- [New Portal]Windows Azure Virtual Machine (11) 在本地使用Hyper-V制作虚拟机模板,并上传至Azure (1)
<Windows Azure Platform 系列文章目录> 本章介绍的内容是将本地Hyper-V的VHD,上传到Azure数据中心,作为自定义的虚拟机模板. 注意:因为在制作VHD的最 ...
- [New Portal]Windows Azure Virtual Machine (12) 在本地使用Hyper-V制作虚拟机模板,并上传至Azure (2)
<Windows Azure Platform 系列文章目录> 本章介绍的内容是将本地Hyper-V的VHD,上传到Azure数据中心,作为自定义的虚拟机模板. 注意:因为在制作VHD的最 ...
- [New Portal]Windows Azure Virtual Machine (13) 在本地使用Hyper-V制作虚拟机模板,并上传至Azure (3)
<Windows Azure Platform 系列文章目录> 本章介绍的内容是将本地Hyper-V的VHD,上传到Azure数据中心,作为自定义的虚拟机模板. 注意:因为在制作VHD的最 ...
- [New Portal]Windows Azure Virtual Machine (14) 在本地制作数据文件VHD并上传至Azure(1)
<Windows Azure Platform 系列文章目录> 之前的内容里,我介绍了如何将本地的Server 2012中文版 VHD上传至Windows Azure,并创建基于该Serv ...
- [New Portal]Windows Azure Virtual Machine (15) 在本地制作数据文件VHD并上传至Azure(2)
<Windows Azure Platform 系列文章目录> 在上一章内容里,我们已经将包含有OFFICE2013 ISO安装文件的VHD上传至Azure Blob Storage中了. ...
- docker制作自己的镜像并上传dockerhub
1.首先注册自己的dockerhub账号,注册地址:https://hub.docker.com 2.在linux服务器登录自己的账号:docker login --username=qiaoyeye ...
- iOS - Scenekit3D引擎初探之 - 导入模型+上传服务器+下载并简单设置
SceneKit是ios8之后苹果推出了一个3D模型渲染框架. SceneKit现在可以支持有限的几种模型,截止到我写这篇文章为止似乎只有.dae和.abc后一种模型我没有使用过.这篇文章只针对.da ...
- MarkDown本地图片上传工具制作总结
引言:开始尝试使用MarkDown语法写文档,发现图片必须用外链的形式才能插入到文章中,而自己平时最常用的插入图片方式就是QQ截屏,觉得很不方便所以制作的小工具辅助上传,因为时间和水平有限,其实代码写 ...
- alpine制作jdk、jre镜像、自定义镜像上传阿里云
alpine制作jdk镜像 alpine Linux简介 1.Alpine Linux是一个轻型Linux发行版,它不同于通常的Linux发行版,Alpine采用了musl libc 和 BusyBo ...
随机推荐
- canvas实现手动绘制矩形
开场白 虽然在实际的开发中我们很少去绘制流程图 就算需要,我们也会通过第3方插件去实现 下面我们来简单实现流程图中很小的一部分 手动绘制矩形 绘制一个矩形的思路 我们这里绘制矩形 会使用到canvas ...
- freertos学习(九)软件定时器
软件定时器 软件定时器是freeRTOS通过一个硬件定时器,实现的定时器.可以实现不同时长的多个定时任务 不从中断上下文中执行定时器回调函数(不消耗任何处理时间) 实现流程 设置软件定时器,推入定时器 ...
- python的命名风格(下划线篇)
一个下划线开头的代表模块私有 用from xxx import * 时python会自动屏蔽带下划线的东西,想要取消屏蔽可以用__all__方法,但不建议(不符合规范) 两个下划线开头的代表类私有
- iPhone 打不开 Apple News 解决方法
想看 Apple News,但是在主屏幕找不到,在 App Store 搜索 Apple News 后打开时显示访问控制已启用,然而在设置中检查发现访问控制并没有启用. 经过一番摸索,发现这个访问控制 ...
- 将.gradle下的 带hash名称文件夹中的依赖 转换为 .m2上的依赖
背景: android studio 在无法下载依赖的情况下 , 仅 使用 mavenLocal() 本地 .gradle 下有对应依赖 , .m2下没有 故将.gradle下的 带hash名称文件 ...
- android 访问域名接口报错
1. 移动端访问https域名及接口,显示 java.net.UnknownHostException: Unable to resolve host "xxx" : No add ...
- RabbitMQ核心概念以及工作原理【转】
RabbitMQ核心概念以及工作原理 我们来看看流行的RabbitMQ消息系统以及它是如何让你的系统之间进行解耦的. 英文原文 RabbitMQ 在这篇短文里,我们会介绍什么是RabbitMQ,它 ...
- 解决Mac安装软件的“已损坏,无法打开...”问题
解决Mac安装软件的"已损坏,无法打开. 您应该将它移到废纸篓"问题 不管在安装时会遇到以已损坏无法打开的困惑, 解决: 一.允许"任何来源"开启 苹果从mac ...
- 为何不要随便用from xx import *
新单位,新工作,远程办公,你想想有多麻烦吧. 一块块看每个模块的详细功能. 看到一个函数,返回值也是一个函数,这本来没啥难的,但是文件里只出现一次.怎么都找不到来自哪个文件,后来全项目搜才找到,原来来 ...
- Azure 入门系列 (第四篇 Key Vault)
本系列 这个系列会介绍从 0 到 1 搭建一个 Web Application 的 Server. 间中还会带上一些真实开发常用的功能. 一共 6 篇 1. Virtual Machine (VM) ...