2-6 C/C++ 编写头文件
建议直接看总结,如果有地方不懂在回头看细节
头文件怎么起作用
当一个test.cpp中#include "Sal_Item.h"时,实际上编译器会把Sal_Item.h文件内的内容全部复制到test.cpp中
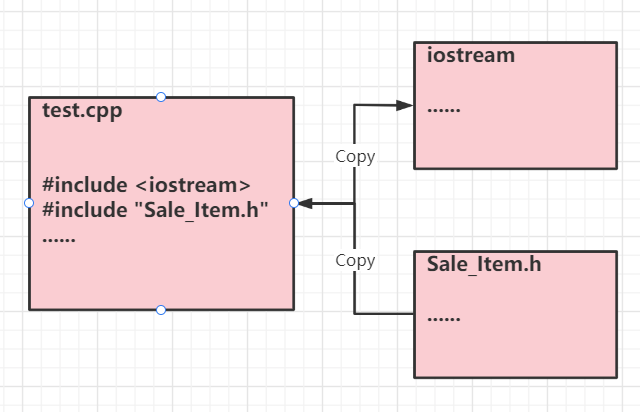
//Sale_Item.h 【未完全版】
#include<string>
struct Sale_Item{
std::string bookname;
double renenue;
int copies;
};
//test.cpp
#include<iostream>
#include<string>
#include"Sale_Item.h" //Sale_Item.h的内容会被复制到这里
using namespace std;
int main(){
Sale_Item data;
return 0;
}
避免头文件被重复引用
因为头文件
Sale_Item.h内容会被复制到引用它的文件test.cpp中所以如果头文件
Sale_Item.h被重复引用,就会导致在Sale_Item.h中定义的变量在test.cpp中被定义了多次,造成编译错误。因此,需要避免头文件被重复引用以及不同头文件中定义了同名的全局变量【当这些定义了同名变量的文件被#include到同一个程序时,同样会造成编译错误】
必须对上面的
Sale_Item.h进行改进,否则一旦被重复引用就会报错执行下面的代码
#include<iostream>
#include<string>
#include"Sale_Item.h"
#include"Sale_Item.h" //重复调用了Sale_Item.h,对于此时的头文件Sale_Item.h是不允许的
using namespace std;
int main(){
Sale_Item data;
std::string name = "xxx";
data.bookname = name;
return 0;
}
结果

避免头文件被重复引用的方法:条件编译
1. 给每个头文件添加一个预编译变量(preprocessor variable)作为标记(Label)
#define SALE_ITEM_H
- 此时
define的作用是定义预编译变量SALE_ITEM_H,而不是定义宏 - 为什么预编译变量如此命名?
- 头文件内容会被复制到
test.cpp中,而且预编译变量无视作用域规则,也就是说整个test.cpp中不能出现与预编译变量SALE_ITEM_H同名的变量 - 一般约定俗成把预编译变量写成头文件名的大写,这样既直观,又不容易和
test.cpp和其他头文件的预编译变量产生冲突
- 头文件内容会被复制到
2. 使用头文件保护符:ifdef/ifndef
ifdef XXX:如果预编译变量XXX已经被定义,则执行该指令与endif之间的代码块
ifndef XXX:如果预编译变量XXX还没有被定义,则执行该指令与endif之间的代码块
常规写法
//Sale_Item.h
#ifndef SAL_ITEM_H //如果SAL_ITEM_H未被定义
#define SAL_ITEM_H //定义SAL_ITEM_H预编译变量作为标记(Lable)。
//如果`test.cpp`在之前已经引用过该头文件,那么SAL_ITEM_H就已经被定义过
//在ifndef的作用下,之后的Sale_Item.h文件都不会执行
#include<string>
int i;
struct Sal_Item{
std::string bookname;
double renenue;
int copies;
};
#endif //结束符
3. 关于使用条件编译的必要性的探讨
- 或许读者会有一个疑问:既然重复引用
Sale_Item.h会导致test.cpp出错,那么不重复引用不就行了,何必那么麻烦写条件编译呢 - 在上述例子中,
Sale_Item.h不写条件编译确实可以,但在很多情况下,我们不得不重复引用同一个头文件。 - 还是以上述例子为例,对于头文件
string。- 在
Sale_Item.h中,我们#include<string>来定义一个变量std::string bookname - 在
test.cpp中,我们#include<string>来定义一个变量std::string name来给对象赋值 - 所以
test.cpp实际上就引用了头文件string两次,一次是显式地引用,一次是在#include"Sale_Item.h"时隐式地引用了string【Sale_Item.h中也include了string】
- 在
- 所以,无论是否有必要,我们建议在书写头文件时,都习惯性地使用条件编译
总结:创建自己的头文件
//Sale_Item.h
#ifndef SAL_ITEM_H //如果SAL_ITEM_H未被定义
#define SAL_ITEM_H //定义SAL_ITEM_H预编译变量作为标记(Lable)。
//如果`test.cpp`在之前已经引用过该头文件,那么SAL_ITEM_H就已经被定义过
//在ifndef的作用下,之后的Sale_Item.h文件都不会执行
#include<string>
int i;
struct Sal_Item{
std::string bookname;
double renenue;
int copies;
};
#endif //结束符
//test.cpp
#include<iostream>
#include<string>
#include"Sale_Item.h"
// #include"Sale_Item.h" //加上不要紧,因为进行了条件编译
using namespace std;
int main(){
Sale_Item data;
std::string name = "xxx";
data.bookname = name;
return 0;
}
2-6 C/C++ 编写头文件的更多相关文章
- 编写自己的C头文件
1. 头文件用于声明而不是用于定义 当设计头文件时,记住定义和声明的区别是很重要的.定义只可以出现一次,而声明则可以出现多次. 下列语句是一些定义,所以不应该放在头文件里: extern ...
- 头文件里面的ifndef /define/endif的作用
c,c++里面,头文件里面的ifndef /define/endif的作用 今天和宿舍同学讨论一个小程序,发现有点地方不大懂······ 是关于头文件里面的一些地方: 例如:要编写头文件test.h ...
- C++头文件为什么要加#ifndef #define #endif
#ifndef 在头文件中的作用 在一个大的软件工程里面,可能会有多个文件同时包含一个头文件,当这些文件编译链接成一个可执行文件时 ,就会出现大量“重定义”的错误.在头文件中实用#ifndef #de ...
- 头文件为什么要加#ifndef #define #endif
#ifndef 在头文件中的作用 在一个大的软件工程里面,可能会有多个文件同时包含一个头文件,当这些文件编译链接成一个可执行文件时 ,就会出现大量“重定义”的错误.在头文件中实用#ifndef #de ...
- 头文件中的#ifndef/#define/#endif 的作用
在一个大的软件工程里面,可能会有多个文件同时包含一个头文件,当这些文件编译链接成一个可执行文件时,就会出现大量重定义的错误.在头文件中实用#ifndef #define #endif能避免头文件的重定 ...
- c++中,保证头文件只被编译一次,避免多重包含的方法
保证头文件只被编译一次 #pragma once这是一个比较常用的C/C++杂注,只要在头文件的最开始加入这条杂注,就能够保证头文件只被编译一次. #pragma once是编译器相关的,有的编译器支 ...
- c语言头文件的认识
c头文件的作用是什么,和.c文件是怎么联系的,该怎么样编写头文件呢?这些问题我一直没搞明白,在阅读uCOS-II(邵贝贝)“全局变量”部分有些疑惑,今天终于搞清楚了头文件的一些基础知识,特地分享一下. ...
- 头文件中ifndef/define/endif的作用以及#pragma once使用
例如:要编写头文件test.h 在头文件开头写上两行: #ifndef _TEST_H #define _TEST_H//一般是文件名的大写 ············ ············ 头文件 ...
- C++学习 之 初识头文件
声明: 本人自学C++, 没有计算机基础,在学习的过程难免会出现理解错误,出现风马牛不相及的现象,甚至有可能会贻笑大方. 如果有幸C++大牛能够扫到本人的博客,诚心希望大牛能给予 ...
- C/C++ 引入头文件时 #include<***.h> 与 #include"***.h" 区别
两种情况区分: 1.#include <> 编译器只会去系统文件目录中查找,找不到就报错. 2.#include " " 编译器会先在用户目录中查找,再到编译器设定的 ...
随机推荐
- 【CMake系列】03-cmake 注释、常用指令 message、set、file、for_each、流程控制if
本文给出了 cmake 中的 一些常用的 指令,可以快速了解,为后面的内容深入 打点基础. 本专栏的详细实践代码全部放在 github 上,欢迎 star !!! 如有问题,欢迎留言.或加群[3927 ...
- MFC 静态拆分视图窗口
今天学习了MFC中拆分窗口,现将方法记录下. 想要在窗口视图中拆分成左右两个视图窗口,首先要注意的是拆分后要加载到左右的视图要符合动态创建的类, 也就是要在自己创建的视图类中添加动态创建机制宏. 类内 ...
- 充分利用HarmonyOS NEXT:开发者的全功能指南
随着技术的不断进步,开发者们面临着如何在复杂的技术环境中创造出卓越应用的挑战.在当今的科技浪潮中,如何抓住创新的机遇?HarmonyOS NEXT的发布,带来了全新的机遇和功能.本文将探讨开发者如何充 ...
- 使用 nuxi add 快速创建 Nuxt 应用组件
title: 使用 nuxi add 快速创建 Nuxt 应用组件 date: 2024/8/28 updated: 2024/8/28 author: cmdragon excerpt: 通过使用 ...
- Ruby 学习笔记
基本语法 变量 name = "Alice" age = 30 puts "Name: #{name}, Age: #{age}" var # 局部变量 @va ...
- 禁止 SSH 传递 locale 环境变量
SSH 在连接远程机器时默认会传递一些环境变量,其中就包括你本机的 locale 变量.这会导致远程机器的 locale 配置变成和你本地主机一样.有时候我们不希望这种行为,我们可以通过修改 SSH ...
- 【FFmpeg】之Mac系统爬取所有M3U8视频下载方法
前言 由于有的网站不允许下载视频,到了有效期就不能看了,但是我想以后反复看,怎么办呢? 前提准备 操作系统:Mac 浏览器:谷歌浏览器 抓取m3u8工具:猫爪 视频处理工具:ffmpeg 需要安装工具 ...
- centos上yum无法使用的问题以及无法用yum安装screen,iftop,nethogs等的解决办法
大家可能都发现了centos8已经不在更新了.当我们使用yum安装某些工具的时候,会提示安装源失败 解决方案:删除repo文件 然后重新下载即可修复yum安装报错问题1.进入/etc/yum.repo ...
- ASP.NET Core Library – Google libphonenumber (Country Dial Code)
前言 Google libphonenumber 是 Java 的, ASP.NET Core 只是 port 过去而已. 以前在 angular2 学习笔记 ( translate, i18n 翻译 ...
- Asp.net core 学习笔记 ( 小东西 )
简单的为 url 添加 query var parametersToAdd = new System.Collections.Generic.Dictionary<string, string& ...