AI可解释性 I | 对抗样本(Adversarial Sample)论文导读(持续更新)
AI可解释性 I | 对抗样本(Adversarial Sample)论文导读(持续更新)
导言
本文作为AI可解释性系列的第一部分,旨在以汉语整理并阅读对抗攻击(Adversarial Attack)相关的论文,并持续更新。与此同时,AI可解释性系列的第二部分:归因方法(Attribution)也即将上线,敬请期待。
Intriguing properties of neural networks(Dec 2013)
作者:Christian Szegedy
简介
Intriguing properties of neural networks 乃是对抗攻击的开山之作,首次发现并将对抗样本命名为Adversarial Sample,首先发现了神经网络存在的两个性质:
单个高层神经元和多个高层神经元的线性组合之间并无差别,即表示语义信息的是高层神经元的空间而非某个具体的神经元
there is no distinction between individual high level units and random linear combinations of high level units, ..., it is the space, rather than the individual units, that contains of the semantic information in the high layers of neural networks.
神经网络的输入-输出之间的映射很大程度是不连续的,可以通过对样本施加难以觉察的噪声扰动(perturbation)最大化网络预测误差以使得网络错误分类,并且可以证明这种扰动并不是一种随机的学习走样(random artifact of learning),可以应用在不同数据集训练的不同结构的神经网络
we find that deep neural networks learn input-output mappings that are fairly discontinuous to a significant extend. Specifically, we find that we can cause the network to misclassify an image by applying a certain imperceptible perturbation, which is found by maximizing the network's prediction error. In addition, the specific nature of these perturbations is not a random artifact of learning: the same perturbation can cause a different network, that was trained on a different subset of the dataset, to misclassify the same input.
神经元激活
文章通过实验证明,某个神经元的方向(natural basis direction)和随机挑选一个方向(random basis)再和整个层级的激活值作余弦相似度之后的结果完全不可区分。
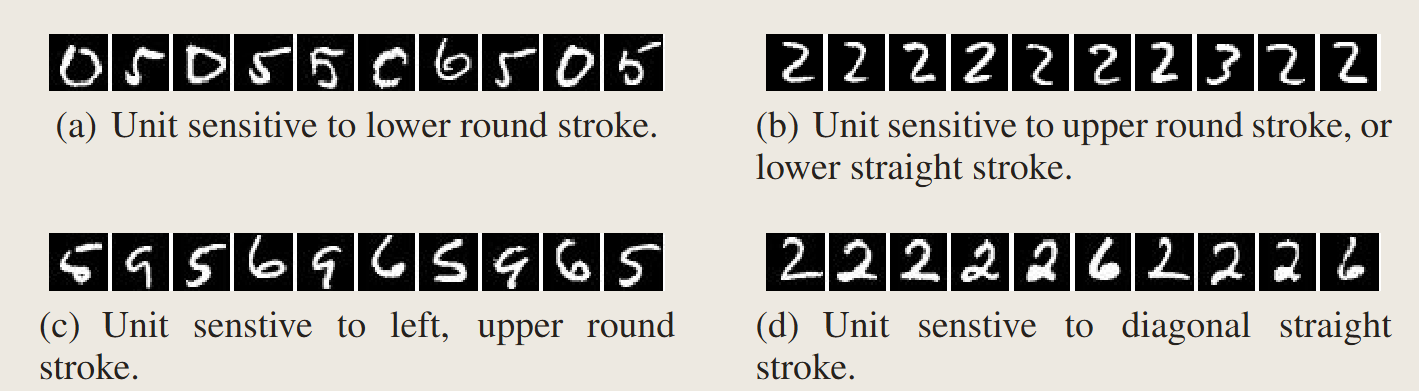
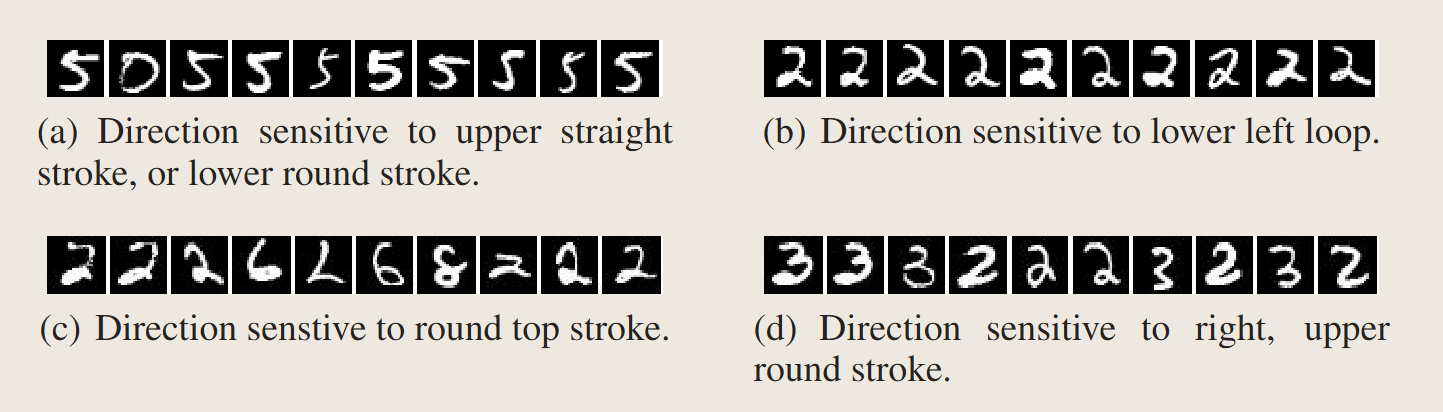
可以证明,单个神经元的解释程度和整个层级的解释程度不分伯仲,即所谓”神经网络解耦了不同坐标上的特征“存在疑问。
This suggest that the natural basis is not better than a random basis in for inspecting the properties of \(\phi(x)\). Moreover, it puts into question the notion that neural networks disentangle variation factors across coordinates.
虽然每个层级似乎在了输入分布的某个部分存在不变性,但是很明显在这些部分的邻域中又存在着一种反直觉的未定义的行为。
神经网络的盲点(Blind Spots in Neural Networks)
观点认为神经网络的多层非线性叠加的目的就是为了使得模型对样本空间进行非局部泛化先验(non-local generalization prior)的编码,换句话说,输出可能会对其周围没有训练样本的输入空间邻域分配不显著(推测约为非\(\epsilon\))的概率(对抗攻击可以发生的假设)。这样做的好处在于,不同视角的同一张图片可能在像素空间产生变化,但是经过非局部泛化先验编码使得在概率上的输出是不变的。
In other words, it is possible for the output unit to assign non-significant (and, presumably, non-epsilon) probabilities to regions of the input space that contain no training examples in their vicinity.
这里可以推导出一种平滑性假设,即训练样本在\(\epsilon\)领域内(\(||x^\prime-x||<\epsilon\))的所有样本都是满足和训练样本的类别一致。
And that in particular, for a small enough radius " in the vicinity of a given training input x, an x " which satisfies ||x x " || < " will get assigned a high probability of the correct class by the model.
Uzuki评论:神经网络验证做的工作就是寻找这个\(\epsilon\),证明在\(\epsilon\)邻域内不存在对抗样本
接下来,作者将通过实验证明这种平滑性假设在很多的核方法(kernel method)上都是不成立的,可以通过一种高效的优化算法完成(即对抗攻击),这种优化过程在于遍历从网络形成的流形上以寻找“对抗样本”。这些样本在网络的高维流形上被认为是低概率出现的局部“口袋“。
In some sense, what we describe is a way to traverse the manifold represented by the network in an efficient way (by optimization) and finding adversarial examples in the input space.
算法的形式化描述
给定一个分类器\(f:\mathbb{R}^m\rightarrow \{1\dots k\}\)以及一个连续的损失函数\(\mathbb{R}^m\times\{1\dots k\} \rightarrow \mathbb{R}^+\),输入图像\(x\in\mathbb{R}^m\)和目标类别${1\dots k} $以解开下面如下的箱约束(box-constrained)问题:
- 最小化\(||r||_2\)并保证:
- \(f(x+r)=l\)
- \(x+r\in[0,1]^m\)(确保是RGB范围)
这个问题只要\(f(x)\neq l\)就是一个非平凡的难解问题,因此我们通过box-constrained L-BFGS算法去优化近似求解。问题可以如下表示:通过线搜索找到一个最小的\(c\),以最小化\(r\)
- 最小化\(c|r|+\text{loss}_f(x+r,l)\quad s.t.\quad x+r\in[0,1]^m\)
In general, the exact computation of D(x, l) is a hard problem, so we approximate it by using a box-constrained L-BFGS. Concretely, we find an approximation of D(x, l) by performing line-search to find the minimum c > 0 for which the minimizer r of the following problem satisfies f (x + r) = l.
实验
通过实验,可以得到如下三个结论:
- 对于文章研究的所有网络(包括MNIST、QuocNet、AlexNet),针对每个样本,始终能够生成与原始样本极其相似、视觉上无法区分的对抗样本,且这些样本均被原网络误分类。
- 跨模型的泛化性:当使用不同超参数(如层数、正则化项或初始权重)从头训练网络时,仍有相当比例的对抗样本会被误分类。
- 跨训练集的泛化性:在完全不同的训练集上从头训练的网络,同样会误分类相当数量的对抗样本。
- For all the networks we studied (MNIST, QuocNet [10], AlexNet [9]), for each sample, we always manage to generate very close, visually indistinguishable, adversarial examples that are misclassified by the original network (see figure 5 for examples).
- Cross model generalization: a relatively large fraction of examples will be misclassified by networks trained from scratch with different hyper-parameters (number of layers, regularization or initial weights).
- Cross training-set generalization a relatively large fraction of examples will be misclassified by networks trained from scratch trained on a disjoint training set.
可以证明对抗样本存在普适性,一个微妙但关键的细节是:对抗样本需针对每一层的输出生成,并用于训练该层之上的所有层级。实验表明,高层生成的对抗样本比输入层或低层生成的更具训练价值。
A subtle, but essential detail is that adversarial examples are generated for each layer output and are used to train all the layers above. Adversarial examples for the higher layers seem to be more useful than those on the input or lower layers.
然而,这个实验仍然留下了关于训练集依赖性的问题。生成示例的难度是否仅仅依赖于我们训练集作为样本的特定选择,还是这一效应能够泛化到在完全不同训练集上训练的模型?
Still, this experiment leaves open the question of dependence over the training set. Does the hardness of the generated examples rely solely on the particular choice of our training set as a sample or does this effect generalize even to models trained on completely different training sets?
网络不稳定性的谱分析
作者将上一节提出这种监督学习网络对这些特定的扰动族存在的不稳定性可以被如下数学表示:
给定多个集合对\((x_i,n_i)\),使得\(||n_i||<\delta\)但\(||\phi(x_i;W)-\phi(x_i+n_i;W)||\ge M \ge 0\),其中\(\delta\)是一个非常小的值,\(W\)是一个一般的可训练参数。那么这个不稳定的扰动\(n_i\)取决于网络结构\(\phi\)而非特定训练的参数\(W\)
Uzuki评论:这个结论就不得不提对抗训练(Adversarial training)了,因为对抗训练不改变网络结构但是改变了训练集的结构以生成不同的训练参数,提高模型对对抗样本的防护能力,因此对抗训练应该是证明了某个特定的对抗样本生成算法本身总不是最优的
结论
通过寻找对抗样本的过程,我们可以证明神经网络本身并没有很好地实现泛化能力,尽管这些对抗样本在训练过程中出现的概率是极低的,但是模型构建的空间本身是稠密的,几乎每个正常样本都能寻找到对抗样本。
AI可解释性 I | 对抗样本(Adversarial Sample)论文导读(持续更新)的更多相关文章
- 好用的函数,assert,random.sample,seaborn tsplot, tensorflow.python.platform flags 等,持续更新
python 中好用的函数,random.sample等,持续更新 random.sample random.sample的函数原型为:random.sample(sequence, k),从指定序列 ...
- 对抗样本攻防战,清华大学TSAIL团队再获CAAD攻防赛第一
最近,在全球安全领域的殿堂级盛会 DEF CON 2018 上,GeekPwn 拉斯维加斯站举行了 CAAD CTF 邀请赛,六支由国内外顶级 AI 学者与研究院组成的队伍共同探讨以对抗训练为攻防手段 ...
- 用Caffe生成对抗样本
同步自我的知乎专栏:https://zhuanlan.zhihu.com/p/26122612 上篇文章 瞎谈CNN:通过优化求解输入图像 - 知乎专栏 中提到过对抗样本,这篇算是针对对抗样本的一个小 ...
- NLP中的对抗样本
自然语言处理方面的研究在近几年取得了惊人的进步,深度神经网络模型已经取代了许多传统的方法.但是,当前提出的许多自然语言处理模型并不能够反映文本的多样特征.因此,许多研究者认为应该开辟新的研究方法,特别 ...
- 对抗防御之对抗样本检测(一):Feature Squeezing
引言 在之前的文章中,我们介绍了对抗样本和对抗攻击的方法.在该系列文章中,我们介绍一种对抗样本防御的策略--对抗样本检测,可以通过检测对抗样本来强化DNN模型.本篇文章论述其中一种方法:feature ...
- Face Aging with Conditional Generative Adversarial Network 论文笔记
Face Aging with Conditional Generative Adversarial Network 论文笔记 2017.02.28 Motivation: 本文是要根据最新的条件产 ...
- 无监督域对抗算法:ICCV2019论文解析
无监督域对抗算法:ICCV2019论文解析 Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adapta ...
- 千人基因组(1000 Genomes)提取群体(population)或者样本(sample ID)信息
进入链接:http://www.internationalgenome.org/data-portal/sample 点击“filter by population”,在弹出的选择框里,选择想要下载的 ...
- 生成对抗网络资源 Adversarial Nets Papers
来源:https://github.com/zhangqianhui/AdversarialNetsPapers AdversarialNetsPapers The classical Papers ...
- 增量学习不只有finetune,三星AI提出增量式少样本目标检测算法ONCE | CVPR 2020
论文提出增量式少样本目标检测算法ONCE,与主流的少样本目标检测算法不太一样,目前很多性能高的方法大都基于比对的方式进行有目标的检测,并且需要大量的数据进行模型训练再应用到新类中,要检测所有的类别则需 ...
随机推荐
- itextpdf 找出PDF中 文字的坐标
目录 添加引用 添加工具类 调用 找到位置,签名的话见:https://www.cnblogs.com/vipsoft/p/18644127 新项目可以尝试一下 iText 7 , 我这边是老项目所以 ...
- 前端学习openLayers配合vue3(面的绘制,至少三个点)
我们学习了点和线的绘制,当然我们也可以绘制一个面 关键代码,需要注意的一点就是面的绘制需要三维数组,线的绘制是个二维数组 const polygonLayer = new VectorLayer({ ...
- Elasticsearch的分享
一.生活中的数据 搜索引擎是对数据的检索,所以我们先从生活中的数据说起.我们生活中的数据总体分为两种: 结构化数据 非结构化数据 结构化数据: 也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格 ...
- python实现excel数据处理
python xlrd读取excel(表格)详解 安装: pip install xlrd 官网地址: https://xlrd.readthedocs.io/ 介绍: 为开发人员提供一个库,用于从M ...
- 高性能队列Disruptor
背景 Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级).基于Disruptor开发的系统单线程能 ...
- 【Netty】(3)—源码NioEventLoopGroup
netty(3)-源码NioEventLoopGroup 一.概念 NioEventLoopGroup对象可以理解为一个线程池,内部维护了一组线程,每个线程负责处理多个Channel上的事件,而一个C ...
- 项目PMP之十一项目风险管理
项目PMP之十一--项目风险管理 一.定义:削弱负面风险,增强正面风险,将风险敞口保持在可接受的范围,扩大项目实现的概率 非事件类风险:变异性风险,已规划的不确定性(通过蒙特卡洛分析,缩小结果区间 ...
- 一文搞懂SaaS架构建设流程:业务战略设计、架构蓝图设计、领域系统架构设计、架构治理与实施
大家好,我是汤师爷~ SaaS架构建设是一项复杂的系统工程,不仅需要技术层面的实现,更要从业务战略.架构设计.治理与实施等多个维度进行全面规划. 一个成功的SaaS架构可以帮助企业降低IT成本.提升业 ...
- 为什么使用ROS的remap标签不起作用?
1. remap的作用 remap可以让ROS节点订阅发布的topic名字更换为另外一个名字.例如 <remap from="/old_topic" to="/ne ...
- 语音处理 开源项目 EchoSharp
开源项目 EchoSharp(https://github.com/sandrohanea/echosharp),专为近乎实时的音频处理而设计,可为各种音频分析范围无缝编排不同的 AI 模型.Echo ...