批量生成测试数据,再次迎来升级,支持API调用,开发者的好帮手
前端时间发表一篇文章介绍了FabricateData的在线批量生成测试数据的能力,这几天在看,平台不仅添加了本地数据源的概念,还增设了本地API的能力。
FabricateData 网站地址:https://www.fabricatedata.com
本地数据源

这是平台的头部介绍,大概意思是,如果需要在大量的数据中抽取数据,并且一次生成数据时多次用到的话,就用这个本地数据源,一些不太放心流入网络的数据,用这个还能保护隐私,因为它是从本地的数据中加载资源处理并给出结果的。
不过这个功能仅是对【数据源抽取】生成单元的扩展,真正的革新点是本地API能力的出现。
本地API
强烈推荐人群
- 前后端开发
- 测试人员与开发
- IT行业培训老师与学生
- 前端教学时,(想象一下,作为老师,您备课时可以轻松的把数据模型提前配置好,您的学生在学习前端开发时,再也不用为数据发愁了,只专注于页面开发,数据自己就能变化)
官网介绍
在node环境下,可在本地生成一个数据接口服务,该接口服务用于生产测试数据,供您其他本地程序调用。数据结构模型可在FabricateData(https://www.fabricatedata.com)官网中自定义,通过模型分享码导入本地接口服务。
- 数据结构模型需要保存,然后生成分享码。
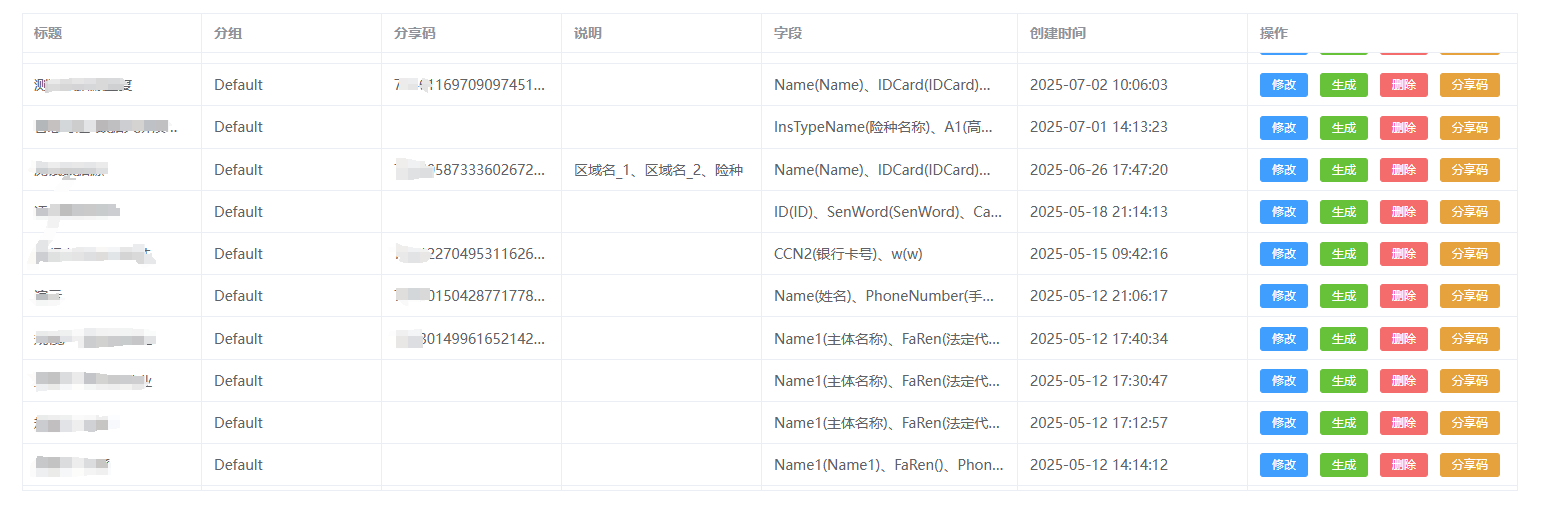
- 导入分享码
(help)> import 7344056933360267785
正在导入数据模型,分享码:7344056933360267785
导入成功!模型为【测试******】
看到导入成功的提示后,就可以通过url调用api,拿到即时生成的测试数据了。
具体使用方法建议查看官方说明,这里面详细的介绍了如何使用本地API,环境搭建、API服务的启动、模型导入、url说明等都有介绍。
不想花时间看教程的可以接着往下看,我简短的总结一下如何才能使用本地API。对于有node和前端开发经验的人才,应该很容易了解下面意思,如果您感觉有不懂的词汇,建议您按照官方的介绍仔细运用。
总结
- 1.注册
FabricateData账号,分享码需要用户保存模型后才能获取,去注册。 - 2.准备node环境,必须安装node(需 >=20.18.0),推荐使用nvm管理node。
- 3.下载好程序包,解压后使用
npm install初始化好程序既可以运行了,去下载。 - 4.使用
本地API,使用命令npm run start或node app.js启动程序,按照提示进行端口设置即可。 - 5.本地API启动后,输入help命令,查看命令帮助
输入命令:
- "help":查看命令列表
- "import 分享码":通过分享码导入数据模型
- "list":查看所有的数据模型
- "model 分享码":查看数据模型详情
- "del 分享码":通过分享码删除数据模型
- "api":查看如何调用接口服务
- "exit":退出程序
再次总结
虽然对于没接触过前端开发和node开发的人理解起来不太容易,但是这个并不要你会,只要把环境搭建起来就好了。
运行起来的API服务,不仅支持get,post方式调用,还能模拟网络延迟,让你开发时能够轻松方便的贴合真实场景,从而写出健壮性的页面响应,或者后端处理逻辑。
批量生成测试数据,再次迎来升级,支持API调用,开发者的好帮手的更多相关文章
- mysql使用存储过程,批量生成测试数据
1.存储过程代码 delimiter $$DROP PROCEDURE IF EXISTS create_service_data$$create procedure create_service_d ...
- Python调用百度地图API实现批量经纬度转换为实际省市地点(api调用,json解析,excel读取与写入)
1.获取秘钥 调用百度地图API实现得申请百度账号或者登陆百度账号,然后申请自己的ak秘钥.链接如下:http://lbsyun.baidu.com/apiconsole/key?applicatio ...
- 稳定好用的短连接生成平台,支持API批量生成
https://www.5w.fit/ 01 安全:快码拥有两种模式:防封模式和极速模式,防封模式使短链更加安全! 02 无流量劫持:快码短链绝不劫持流量! 03 极速:专属大量服务器,支持高并发 ...
- Spark2.2+ES6.4.2(三十一):Spark下生成测试数据,并在Spark环境下使用BulkProcessor将测试数据入库到ES
Spark下生成2000w测试数据(每条记录150列) 使用spark生成大量数据过程中遇到问题,如果sc.parallelize(fukeData, 64);的记录数特别大比如500w,1000w时 ...
- 性能测试学习第四天-----loadrunner:jdbc批量制造测试数据 & controller应用
Javavuser协议 1.过程概述:在eclipse中用java编写sql执行脚本,复制到lr中,调整后通过参数化迭代批量制造测试数据: 2.步骤: 1).在eclipse中新建java proje ...
- 将表里的数据批量生成INSERT语句的存储过程 增强版
将表里的数据批量生成INSERT语句的存储过程 增强版 有时候,我们需要将某个表里的数据全部或者根据查询条件导出来,迁移到另一个相同结构的库中 目前SQL Server里面是没有相关的工具根据查询条件 ...
- RandomUser – 生成随机用户 JSON 数据的 API
RandomUser 是一个 API,它为您提供了一个或者一批随机生成的用户.这些用户可以在 Web 应用程序原型中用作占位符,将节省您创建自己的占位符信息的时间.您可以使用 AJAX 或其他方法来调 ...
- 批量生成sqlldr文件,高速卸载数据
SQL*Loader 是用于将外部数据进行批量高速加载的数据库的最高效工具,可用于将多种平面格式文件加载到Oracle数据库.SQL*Loader支持传统路径模式以及直接路径这两种加载模式.关于SQL ...
- C# 程序自动批量生成 google maps 的KML文件
原文:C# 程序自动批量生成 google maps 的KML文件 google maps 的 KML 文件可以用于静态的地图标注,在某些应用中,我们手上往往有成百上千个地址,我们需要把这些地址和描述 ...
- SQL Server中生成测试数据
原文:SQL Server中生成测试数据 简介 在实际的开发过程中.很多情况下我们都需要在数据库中插入大量测试数据来对程序的功能进行测试.而生成的测试数据往往需要符合特定规则.虽然可以自己写 ...
随机推荐
- Electron35-DeepSeek桌面端AI系统|vue3.5+electron+arco客户端ai模板
2025跨平台ai实战electron35+vite6+arco仿DeepSeek/豆包ai流式打字聊天助手. electron-deepseek-chat:实战ai大模型对话,基于vue3.5+el ...
- <HarmonyOS第一课12>Web组件和WebView #鸿蒙课程##鸿蒙生态#
课程介绍 <HarmonyOS第一课:Web组件和WebView>是一门专为HarmonyOS开发者设计的课程,旨在掌握如何在应用中集成Web内容.课程首先介绍了基于Web技术的Web组件 ...
- 【记录】MATLAB矩阵的批量元素修改方式,与Python的NumPy对比
文章目录 二维矩阵 操作 1. 将数组大于0的数全部加1 2. 删除元素 ①删除单个元素 ②删除一列元素 3. 添加一行或多行 ①添加一行 ②添加多行 4. 获取行/列数 5. 格式化输出数组 结构数 ...
- django笔记补充
安装 pip install django环境变量: C:\Program Files\Anaconda3\Scriptsdjango-admin startproject mysite 创建djan ...
- pytorch中的剪枝操作
深度学习技术依赖于过参数化模型,这是不利于部署的,相反,生物神经网络是使用高效的稀疏连接的. 通过减少模型中的参数数量来压缩模型的技术非常重要,为减少内存.电池和硬件的消耗,而牺牲准确性,实现在设备上 ...
- codeup之比较奇偶数个数
Description 第一行输入一个数,为n,第二行输入n个数,这n个数中,如果偶数比奇数多,输出NO,否则输出YES. Input 输入有多组数据. 每组输入n,然后输入n个整数(1<=n& ...
- 阅读类元服务开发笔记---week1
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- VcXsrv鼠标不显示问题解决方法
问题描述 在windows10上通过WSL2安装了ubuntu22.04的系统,在通过VcXsrv使用界面显示的时候,显示界面不显示鼠标指针. 我是通过步骤四直接解决的. 解决方法 1. 检查VcXs ...
- 【2020.11.19提高组模拟】倍数区间interval 题解
[2020.11.19提高组模拟]倍数区间interval 题解 题目描述 定义在序列\(a_1,a_2,\dots,a_n\)上的合法区间\([L,R]\)为满足\(\exists k\in [L, ...
- 二叉排序树BST及CRUD操作
摘要 构造一颗二叉排序树(也叫二叉搜索树,BST,Binary Search Tree)十分简单.一般来讲,大于根节点的放在根节点的右子树上,小于根节点的放在根节点的左子树上(如果等于根节点,则可视情 ...