JDK源码学习LinkedList
LinkedList是List接口的子类,它底层数据结构是双向循环链表。LinkedList还实现了Deque接口(double-end-queue双端队列,线性collection,支持在两端插入和移除元素).所以LinkedList既可以被当作双向链表,还可以当做栈、队列或双端队列进行操作.文章目录如下:
1.LinkedList的存储实现(jdk 1.7.0_51)
下面我们进入正题,开始学习LinkedList.
LinkedList的存储实现(jdk 1.7.0_51)
我们知道LinkedList的底层数据结构是双向链表,也就是每个节点都持有指向前一个节点和指向后一个节点的指针.存储模型如下图:

理解了双向链表结构,再看源码LinkedList就会觉得很简单了。本质上,LinkedList就是这样一堆节点的集合,这些节点都持有前后节点的引用,所以LinkedList定义了一个内部类LinkedList.Node,源码如下:
private static class Node<E> {
E item;
Node<E> next;//前一个Node的引用
Node<E> prev;//后一个Node的引用
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
接下来,我们看看LinkedList声明的成员变量:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;// 集合中的Node个数
transient Node<E> first;//链表中Header节点的引用
transient Node<E> last;//链表中Last节点的引用
可以看到,LinkedList定义了三个成员变量,size用于保存集合中存放节点的个数,first指向链表的第一个元素,last指向链表的最后一个元素。接下来,我们观察LinkedList的add(E)方法:
public boolean add(E e) {
linkLast(e);//调用linkLast()方法处理
return true;
}
/** 将元素添加到链表的末尾 **/
void linkLast(E e) {
final Node<E> l = last;// 获取链表的最后一个元素
// 创建新节点,新节点的prev指向l节点
final Node<E> newNode = new Node<>(l, e, null);
// 因为新节点在链表的最末尾,last指向新节点
last = newNode;
if (l == null)//该节点添加前,链表为空链表
first = newNode;
else //如果链表中有节点
l.next = newNode;
size++;
modCount++;
}
由上面的代码可以看到,add(E)方法是将e元素添加到链表的末尾,LinkedList还提供了addFirst(E),add(index,E).
/** 添加元素到链表的开始处 **/
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;//获取Header元素
// 创建新节点,newNode.next=f
final Node<E> newNode = new Node<>(null, e, f);
// first指向新节点
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
上面就是addFirst(),该方法将节点存放在链表的第一位.下面来看add(index,E)
/** 指定位置添加节点 **/
public void add(int index, E element) {
checkPositionIndex(index);//index between 0 and size
if (index == size)// 添加节点在链表末尾
linkLast(element);
else //在index处插入新节点,newNode.next=node(index)
linkBefore(element, node(index));
}
/** 获取index处的Node **/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) { index < size/2,从first开始往后找
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { // 从last开始往前找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
/** 在succ节点前插入新节点 **/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
LinkedList是基于双向链表的数据结构实现的,所以它的顺序访问会非常高效,而随机访问的效率会比较低.从node(index)方法中知道,双向链表和索引值是通过计数索引值来实现的.如果index<size/2,则从first节点开始往后查找,反之,则从last节点开始往前查找.
LinkedList的读取实现
LinkedList提供了很多方法去获取集合中的元素,我们知道实现了AbstractSequentialList接口的类都会提供索引访问.所以我们首先来看get(index).
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
get(index)内部就是调用Node(index)处理的,这个方法上面已经讲过了,之前也说过,LinkedList是基于双向链表实现的,所以随机访问并非LinkedList所长.我们来看下LinkedList提供其他访问元素的方法:
/** 获取第一个节点 **/
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
/** 获取末尾节点 **/
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
/** 移除第一个节点,并返回该节点 **/
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
/** 移除末尾节点,并返回移除的节点 **/
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
上面我们说了一些比较简单基础的方法,对LinkedList有了大致的认识,文章前面说过LinkedList还可以当做栈、队列来操作。下面我们来学习一下LinkedList的其他用法。
LinkedList作为FIFO(先进先出)的队列
队列的特性是先进先出,所以新增的节点会存放到链表的末尾,每次取出元素都是取链表第一个元素。
/** 队列添加元素,也可以直接用add(e),addLast(),offerLast()方法实现**/
public boolean offer(E e) {
return add(e);
}
/** 队列取元素并移除元素 ,还可以用remove(),removeFirst()**/
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
LinkedList作为LIFO(后进先出)的栈
栈的特性是:后进先出,新添加的元素添加到链表首位,读取元素也从链表的第一个节点开始.
/** 压栈 **/
public void push(E e) {
addFirst(e);
}
/** 出栈 **/
public E pop() {
return removeFirst();
}
当然,进栈和出栈都还有很多其他方法实现,实现原理都一样,这里就不一一讨论.总之,LinkedList实现了List接口的Deque接口,既可以当做双向链表,还可以做队列、栈使用.
LinkedList的性能分析
LinkedList底层是基于线性结构的双向链表,其顺序访问的效率很高,随机访问的效率会比较低.所以我们在操作LinkddList时,尽量不要操作使用了索引的方法.基于这个特性,有以下几点:
遍历LinkedList.测试代码如下:
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList list = new LinkedList<Integer>();
for(int i=0;i<100000;++i){
list.add(i);
}
System.out.println("by index :"+printLinkedListByIndex(list)+" ms");
System.out.println("by Foreach :"+printLinkedListByForeach(list)+" ms");
System.out.println("by Iterator :"+printLinkedListByIterator(list)+" ms");
System.out.println("by RemoveFirst :"+printLinkedListByRemoveFirst(list)+" ms");
System.out.println("by RemoveLast :"+printLinkedListByRemoveLast(list)+" ms");
System.out.println("by PollFirst :"+printLinkedListByPollFirst(list)+" ms");
System.out.println("by PollLast:"+printLinkedListByPollLast(list)+" ms");
}
public static long printLinkedListByIndex(LinkedList list){
long startTime = System.currentTimeMillis();
for(int i=0;null!=list && i<list.size();++i){
list.get(i);
}
long endTime = System.currentTimeMillis();
return (endTime-startTime);
}
public static long printLinkedListByForeach(LinkedList<Integer> list){
long startTime = System.currentTimeMillis();
for(Integer i : list);
long endTime = System.currentTimeMillis();
return endTime-startTime;
}
public static long printLinkedListByIterator(LinkedList<Integer> list){
long startTime = System.currentTimeMillis();
Iterator<Integer> iterator = list.iterator();
while(iterator.hasNext()){
iterator.next();
}
long endTime = System.currentTimeMillis();
return endTime-startTime;
}
public static long printLinkedListByRemoveFirst(LinkedList<Integer> list){
long startTime = System.currentTimeMillis();
for(int i =0;null!=list && i<list.size();++i){
list.removeFirst();
}
long endTime = System.currentTimeMillis();
return endTime-startTime;
}
public static long printLinkedListByRemoveLast(LinkedList<Integer> list){
long startTime = System.currentTimeMillis();
for(int i =0;null!=list && i<list.size();++i){
list.removeLast();
}
long endTime = System.currentTimeMillis();
return endTime-startTime;
}
public static long printLinkedListByPollFirst(LinkedList<Integer> list){
long startTime = System.currentTimeMillis();
for(int i =0;null!=list && i<list.size();++i){
list.pollFirst();
}
long endTime = System.currentTimeMillis();
return endTime-startTime;
}
public static long printLinkedListByPollLast(LinkedList<Integer> list){
long startTime = System.currentTimeMillis();
for(int i =0;null!=list && i<list.size();++i){
list.pollLast();
}
long endTime = System.currentTimeMillis();
return endTime-startTime;
}
}
运行结果: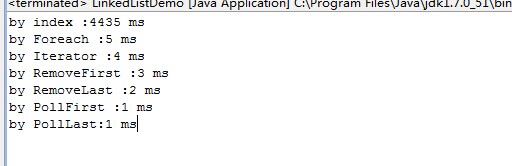
从运行结果可知:LinkedList遍历最高效的方式是移除header/tail元素,如果不要移除元素,则迭代器是最效率最高的方式,一定不能使用随机访问. 也尽量不要调用LinkedList中使用了随机访问方式操作的方法.
曾经看过一篇讲LinkedList性能的文章,文章的作者觉得LinkedList有以下两个应用场景:
- 想实现一个FIFO队列缓冲区,并且很少在队列中间移除元素,因为 LinkedList能快速移除header和tail节点,所以用LinkedList是一个不错的选择。当然,更应该考虑使用ArrayDeque,因为ArrayDeque优化了header和tail元素的操作.
- 基本上不要在LinkedList中间添加或移除节点.因为在LinkedList中间操作节点,可能会需要随机访问LinkedList,LinkedList最大的弊端就在随机访问.
该文的链接:http://java-performance.info/linkedlist-performance/,有兴趣的朋友可以看下.
ok,LinkedList的学习就先讲到这里了,欢迎大家一起交流,当然如果以后的工作和学习中学到了其他知识,随时会有更新.
JDK源码学习LinkedList的更多相关文章
- JDK源码学习系列05----LinkedList
JDK源码学习系列05----LinkedList 1.LinkedList简介 LinkedList是基于双向链表实 ...
- JDK源码学习笔记——LinkedHashMap
HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序,也就是无序. LinkedHashMap保证了元素迭代的顺序.该迭代顺序可以是插入顺序或者是访问顺序.通过维护一个 ...
- JDK源码学习--String篇(二) 关于String采用final修饰的思考
JDK源码学习String篇中,有一处错误,String类用final[不能被改变的]修饰,而我却写成静态的,感谢CTO-淼淼的指正. 风一样的码农提出的String为何采用final的设计,阅读JD ...
- JDK源码学习系列04----ArrayList
JDK源码学习系列04----ArrayList 1. ...
- JDK源码学习系列03----StringBuffer+StringBuilder
JDK源码学习系列03----StringBuffer+StringBuilder 由于前面学习了StringBuffer和StringBuilder的父类A ...
- JDK源码学习系列02----AbstractStringBuilder
JDK源码学习系列02----AbstractStringBuilder 因为看StringBuffer 和 StringBuilder 的源码时发现两者都继承了AbstractStringBuil ...
- JDK源码学习系列01----String
JDK源码学习系列01----String 写在最前面: 这是我JDK源码学习系列的第一篇博文,我知道 ...
- JDK1.8源码学习-LinkedList
JDK1.8源码学习-LinkedList 目录 一.LinkedList简介 LinkedList是一个继承于AbstractSequentialList的双向链表,是可以在任意位置进行插入和移除操 ...
- JDK源码学习笔记——String
1.学习jdk源码,从以下几个方面入手: 类定义(继承,实现接口等) 全局变量 方法 内部类 2.hashCode private int hash; public int hashCode() { ...
随机推荐
- C# 接口的隐式与显示实现及适应场景
通俗的来讲,“显示接口实现”就是使用接口名称作为方法名的前缀;而传统的实现方式称之为:“隐式接口实现”.废话不说,例子如下: interface IAnimal { void Dog(); } cla ...
- JavaScript 正则表达式RegExp 和字符串本身的正则表达式
JavaScript 正则表达式 正则表达式(英语:Regular Expression,在代码中常简写为regex.regexp或RE)使用单个字符串来描述.匹配一系列符合某个句法规则的字符串搜索模 ...
- VMWare开启DHCP和NAT服务(VMWare无法通过NAT上网以及和host主机通信的问题解决)
最近在学习Hadoop,开始做一个集群.由于各个节点的IP地址需要保持不变,我决定在VMWare采用NAT的模式联网. 但是在安装Ubuntu系统的时候,提示我DHCP服务未开启. Your netw ...
- MySQL6:视图
什么是视图 数据库中的视图是一个虚拟表.视图是从一个或者多个表中导出的表,视图的行为与表非常相似,在视图中用户可以使用SELECT语句查询数据,以及使用INSERT.UPDATE和DELETE修改记录 ...
- Ubuntu使用心得
因为开发学习需要,也接触了一些Ubuntu系统,玩崩了两次系统之后,也学到了一些东西. -------------------------------------------------------- ...
- 网络I/O模型--06异步I/O
异步I/O (又称为 AIO )则是采用“订阅一通知”工作模式 : 即应用程序向操作系统注册I/O监听,然后继续做自己的事情.当操作系统发生I/O事件,并且准备好数据后 , 再主动通知应用程序,触发相 ...
- 【Android】RxJava的使用(三)转换——map、flatMap
前两篇Android RxJava的使用(一)基本用法.Android RxJava的使用(二)Action介绍了RxJava的基本用法,对Rxjava还不了解的请先看以上两篇.这篇为大家讲解RxJa ...
- Pwn Heap With Tcache
Pwn Heap With Tcache 前言 glibc 2.26 开始引入了 tcache , 相关的 commit 可以看 这里 .加入 tcache 对性能有比较大的提升,不过由于 tcach ...
- js原生实现轮播
前两天同事面试新人,让现场写”轮播的实现”.我一想这玩意貌似我也没写过啊,就在旁边暗搓搓地拖了一张纸也在那写,同事都纳闷了! 这玩意实现方法有很多种,就看喜欢那种,喜欢怎么写而已.我这里是通过对img ...
- Material适配1 - 入门篇
版权声明: 欢迎转载,但请保留文章原始出处 作者:GavinCT 出处:http://www.cnblogs.com/ct2011/p/4493384.html 随着Material Design的普 ...