网络请求 爬虫学习笔记 一 requsets 模块的使用 get请求和post请求初识别,代理,session 和ssl证书
前情提要:
为了养家糊口,为了爱与正义,为了世界和平,
从新学习一个爬虫技术,做一个爬虫学习博客记录
学习内容来自各大网站,网课,博客.
如果觉得食用不良,你来打我啊

requsets 个人觉得系统自带的库不好用,以前学过自动自带的urblib 和request 库..
想学隔壁转弯自学.学就从这个库开始学习
一:reuqests 库的get 和post请求
知识点:
>:1 想要发送什么请求就调用什么请求的方法
>:2
response 的属性
response.text() # 获取文本
response.content() #以2进制的方式获取,需要docode()成对应编码
response.url() #返回url
response.encoding() #返回编码方式
response.status_code() #返回状态
二:get请求的例子
'''
get请求
'''
import requests
# url ='https://www.baidu.com/'
# response =requests.get(url)
params ={
"wd":'中国'
}
headers ={"User-Agent":"Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"}
response=requests.get('http://www.baidu.com/s?',params=params,headers=headers)
print(response.url) #返回拼接后的url
print(response.content.decode('utf-8')) #content #uncode解码
print(response.status_code)# 返回链接状态码
print(response.encoding) #返回编码方式
#print(response.text) #返回默认按照系统编码的
第16行和第13 行按照个人爱好和网页情况而定
具体步骤:
1b:导包
2b:分析网页,传参
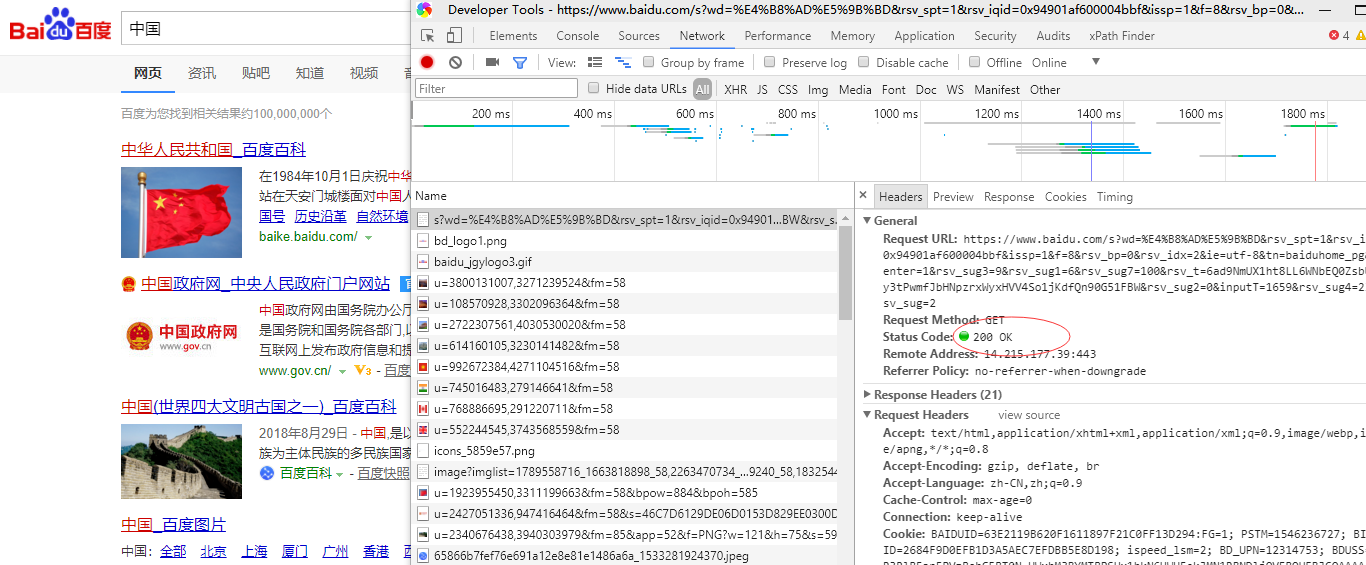
get请求,200响应
3b,输入中国查看网页入参
params={
'wd':'中国'
}
params 是传递参数用的
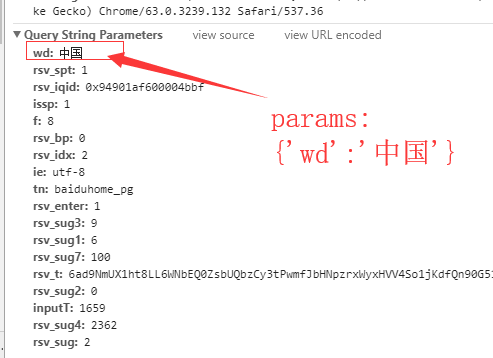
这样就获取到了最基础的get请求内容
三:post请求例子:
post 请求:是输入内容不随这html显示在标题上.是一种安全的请求
例子是拉勾网,..这个网站不把 内容写在html里面,写在post里面..
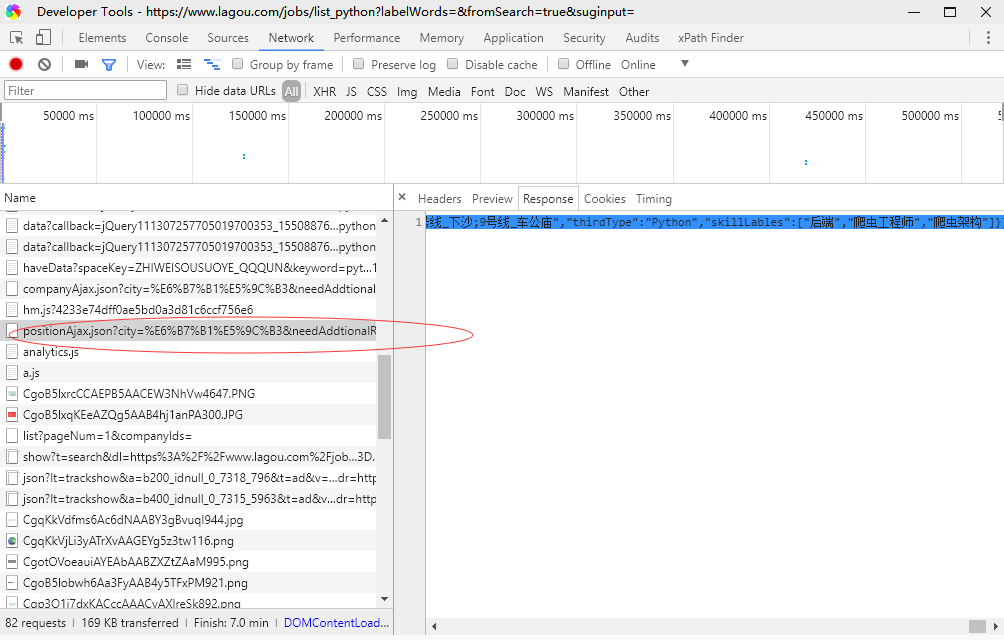
post请求
'''
import requests data ={
"first":"true",
"pn":"1",
"kd":"python" }
proxy={
"https":"221.218.102.146:58208"
}
headers = {
'Origin': 'https://www.lagou.com',
'X-Anit-Forge-Code': '0',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'X-Requested-With': 'XMLHttpRequest',
'Connection': 'keep-alive',
'X-Anit-Forge-Token': 'None',
'Cookie':'_ga=GA1.2.182345315.1550592539; _gid=GA1.2.2105546638.1550592539; user_trace_token=20190220000855-a848d5ea-3460-11e9-95fb-525400f775ce; LGUID=20190220000855-a848ddc6-3460-11e9-95fb-525400f775ce; index_location_city=%E6%B7%B1%E5%9C%B3; JSESSIONID=ABAAABAAAIAACBI9C3F23A9363576FBCAEBE7AC328116CF; WEBTJ-ID=20190220232250-1690b80958d21f-0bc575533ce91d-3c604504-1049088-1690b80958e1ac; _gat=1; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1550592539,1550632242,1550674096,1550676170; LGSID=20190220232250-62a45f5d-3523-11e9-8292-5254005c3644; PRE_UTM=m_cf_cpc_360_pc; PRE_HOST=www.so.com; PRE_SITE=https%3A%2F%2Fwww.so.com%2Fs%3Fie%3Dutf-8%26src%3D360chrome_toolbar_search%26q%3D%25E6%258B%2589%25E9%2592%25A9; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flp%2Fhtml%2Fcommon.html%3Futm_source%3Dm_cf_cpc_360_pc%26m_kw%3D360_cpc_sz_e110f9_265e1f_%25E6%258B%2589%25E9%2592%25A9; TG-TRACK-CODE=index_search; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1550676179; LGRID=20190220232259-67a01432-3523-11e9-8292-5254005c3644; SEARCH_ID=97c647fb59dd46e7a1e492cb426da9cc'
}
response=requests.post('https://www.lagou.com/jobs/positionAjax.json?city=%E6%B7%B1%E5%9C%B3&need',data=data,headers=headers,proxies=proxy)
print(response.content.decode('utf-8'))
# print(response.text)
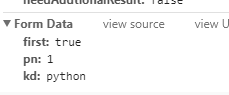
from data是post 请求输入的内容
data ={
"first":"true",
"pn":"1",
"kd":"python"}
模拟输入内容
四:requests的代理问题
知识点:requsests的proxies = 可以输入ip要注意请求方式是http 还是https
}
import requests
url ='https://httpbin.org/ip'
proxy ={
"https":'61.164.39.66:53281'
}
response =requests.get(url,proxies=proxy)
print(response.text)
https://httpbin.org/ip 这个网站可以返回请求者的ip
用于代理ip的网站很多.个人喜欢xici ,kaidaili等,都很多
五:session 的使用
如果想要在多次请求中共享cookies,那么使用session
import requests
# session 是保留登录状态,方便下次直接登录
session= requests.session()
url =你需要登录的网站
data =输入内容
headers =请求头
session.post(url,data=data,headers=headers)
response =session.get(url)
# 登录后用session保持登录请求和原来的requests 一样
六 :处理ssl不认证网站
'''
有些网站不没有合法的ssl 证书
只需要requests 请求中将 verify =False就可以了
'''
网络请求 爬虫学习笔记 一 requsets 模块的使用 get请求和post请求初识别,代理,session 和ssl证书的更多相关文章
- [爬虫学习笔记]Url过滤模块UrlFilter
Url Filter则是对提取出来的URL再进行一次筛选.不同的应用筛选的标准是不一样的,比如对于baidu/google的搜索,一般不进行筛选,但是对于垂直搜索或者定向抓取的应用,那 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Python3学习笔记(urllib模块的使用)转http://www.cnblogs.com/Lands-ljk/p/5447127.html
Python3学习笔记(urllib模块的使用) 1.基本方法 urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, ...
- JavaWeb请求-响应学习笔记
先来看一个流程图: 服务器处理请求的流程: (1)服务器每次收到请求时,都会为这个请求开辟一个新的线程. (2)服务器会把客户端的请求数据封装到request对象中,request就是请求数据的载 ...
- 爬虫学习笔记2requests库和beautifulsoup4库学习笔记
目录 1.requests库 1.1 安装 2.beautifulsoup4 2.1 常用方法 2.2 bs4 中四大对象种类 2.3 遍历文档树 2.4 搜索文档树 查询id=head的Tag 查询 ...
- iOS开发网络篇—GET请求和POST请求
iOS开发网络篇—GET请求和POST请求 一.GET请求和POST请求简单说明 创建GET请求 // 1.设置请求路径 NSString *urlStr=[NSString stringWithFo ...
- 二:网络--GET请求和POST请求
一.GET请求和POST请求简单说明 GET - 从指定的服务器中获取数据 POST - 提交数据给指定的服务器处理 GET方法: 使用GET方法时,查询字符串(键值对)被附加在URL地址后面一起发送 ...
- iOS开发网络篇—GET请求和POST请求(转)
一.GET请求和POST请求简单说明 创建GET请求 1 // 1.设置请求路径 2 NSString *urlStr=[NSString stringWithFormat:@"http:/ ...
- iOS开发网络篇—GET请求和POST请求的说明与比较
1.GET请求和POST请求简单说明 1.1 创建GET请求 // 1.设置请求路径 NSString *urlStr = [NSString stringWithFormat:@"http ...
随机推荐
- Java中的内存划分
Java程序在运行时,需要在内存中分配空间.为了提高运行效率,就对数据进行了不同的空间划分.因为每一片区域都有特定的数据处理方式和内存管理方式. 具体分为5种内存空间: 程序计数器:保证线程切换后能恢 ...
- Android framework层实现实现wifi无缝切换AP
http://www.linuxidc.com/Linux/2013-12/93476.htm Android市场上有一款叫Wifijumper的软件,实现相同ssid的多个AP之间根据wifi信号的 ...
- 何时开始phonics学习及配套阅读训练zz
引子:自从11月份俱乐部第一批孩子开始英文阅读,到现在三.四个月的时间过去了.很多孩子从不知道怎么读绘本甚至排斥英语,到现在能很投入地看原版书, 有些甚至主动地去寻找拼读规律.我家小宝目前也从前期的阅 ...
- 2018.09.17 atcoder Tak and Cards(背包)
传送门 背包经典题. 直接f[i][j]f[i][j]f[i][j]表示选i张牌和为j的方案数. 最后统计答案就行了. 代码: #include<bits/stdc++.h> #defin ...
- 【Unity】1.0 第1章 Unity—3D游戏开发和虚拟现实应用开发的首选
分类:Unity.C#.VS2015 创建日期:2016-03-23 一.简介 Unity是跨平台2D.3D游戏和虚拟现实高级应用程序的专业开发引擎,是由Unity Technologies公司研制的 ...
- time & datetime 模块
在平常的代码中,我们常常需要与时间打交道.在Python中,与时间处理有关的模块就包括:time,datetime,calendar(很少用,不讲),下面分别来介绍. 在开始之前,首先要说明几点: 一 ...
- 使用vbs给PPT(包括公式)去背景
在 视图—>宏 内新建宏 '终极版 Sub ReColor() Dim sld As Slide Dim sh As Shape For Each sld In ActivePresentati ...
- (连通图 模板题 无向图求割点)Network --UVA--315(POJ--1144)
链接: https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...
- CentOS 7 x64部署tomcat
1.jdk1.7 官网地址:jdk下载地址 下载地址:jdk下载地址 2.tomcat 没啥可说,wget 去下载 3.开放端口 firewall-cmd --zone=/tcp --permane ...
- Android ListView setOnItemClickListener/setOnItemSelectedListener,无效
在Android 开发中,有时候我们在设置,LIstview,GridView,这些View的时候,再给他们设置:setOnItemClickListener/setOnItemSelectedLis ...