梯度下降、随机梯度下降、方差减小的梯度下降(matlab实现)
梯度下降代码:
function [ theta, J_history ] = GradinentDecent( X, y, theta, alpha, num_iter )
m = length(y);
J_history = zeros(20, 1);
i = 0;
temp = 0;
for iter = 1:num_iter
temp = temp +1;
theta = theta - alpha / m * X' * (X*theta - y);
if temp>=100
temp = 0;
i = i + 1;
J_history(i) = ComputeCost(X, y, theta);
end
end
end
随机梯度下降代码:
function [ theta,J_history ] = StochasticGD( X, y, theta, alpha, num_iter )
m = length(y);
J_history = zeros(20, 1);
temp = 0;
n = 0;
for iter = 1:num_iter
temp = temp + 1;
index = randi(m);
theta = theta -alpha * (X(index, :) * theta - y(index)) * X(index, :)';
if temp>=100
temp = 0;
n = n + 1;
J_history(n) = ComputeCost(X, y, theta);
end
end
end
方差减小的梯度下降(SVRG):
function [ theta_old, J_history ] = SVRG( X, y, theta, alpha )
theta_old = theta;
n = length(y);
J_history = zeros(20,1);
m = 2 * n;
for i = 1:20
theta_ = theta_old;
Mu = 1/n * X' * (X*theta_ - y);
theta_0 = theta_;
for j = 1:m
index = randi(n);
GD_one = (X(index, :) * theta_0 - y(index)) * X(index, :)';
GD_ = (X(index, :) * theta_ - y(index)) * X(index, :)';
theta_t = theta_0 - alpha * (GD_one - GD_ + Mu);
theta_0 = theta_t;
end
J_history(i) = ComputeCost(X, y, theta_t);
theta_old = theta_t;
end
end
损失函数:
function J = ComputeCost( X, y, theta )
m = length(y);
J = sum((X*theta - y).^2) / (2*m);
end
主程序代码:
%% clean workspace
clc;
clear;
close all;
%% plot data
fprintf('plot data... \n');
X = load('ex2x.dat');
y = load('ex2y.dat');
m = length(y);
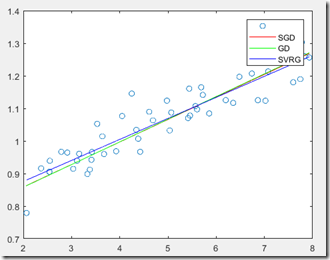
figure;
plot(X,y,'o');
%% gradient decent
fprintf('Runing gradient decent... \n');
X = [ones(m,1),X];
theta_SGD = zeros(2, 1);
theta_GD = zeros(2, 1);
theta_SVRG = zeros(2, 1);Iteration = 2000;
alpha = 0.015;
alpha1 = 0.025;[theta ,J]= StochasticGD(X, y, theta_SGD, alpha, Iteration);
[theta1 ,J1]= GradinentDecent(X, y, theta_GD, alpha, Iteration);
[theta2 ,J2]= SVRG(X, y, theta_SVRG, alpha1);fprintf('SGD: %f %f\n',theta(1),theta(2));
fprintf('GD: %f %f\n',theta1(1),theta1(2));
fprintf('SVRG: %f %f\n',theta2(1),theta2(2));hold on;
plot(X(:, 2), X*theta, 'r-');
plot(X(:, 2), X*theta1, 'g-');
plot(X(:, 2), X*theta2, 'b-');
legend('','SGD','GD','SVRG');x_j = 1:1:20;
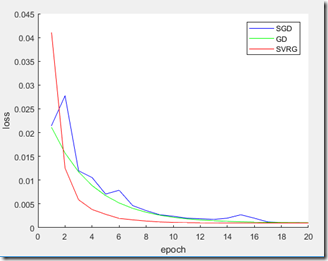
figure;
hold on;
plot(x_j, J, 'b-');
plot(x_j, J1, 'g-');
plot(x_j, J2, 'r-');
legend('SGD','GD','SVRG');
xlabel('epoch')
ylabel('loss')
实验结果:
梯度下降、随机梯度下降、方差减小的梯度下降(matlab实现)的更多相关文章
- 梯度下降算法对比(批量下降/随机下降/mini-batch)
大规模机器学习: 线性回归的梯度下降算法:Batch gradient descent(每次更新使用全部的训练样本) 批量梯度下降算法(Batch gradient descent): 每计算一次梯度 ...
- 吴恩达机器学习笔记6-梯度下降II(Gradient descent intuition)--梯度下降的直观理解
在之前的学习中,我们给出了一个数学上关于梯度下降的定义,本次视频我们更深入研究一下,更直观地感受一下这个算法是做什么的,以及梯度下降算法的更新过程有什么意义.梯度下降算法如下: 描述:对
- 梯度下降&随机梯度下降&批梯度下降
梯度下降法 下面的h(x)是要拟合的函数,J(θ)损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(θ)就出来了.其中m是训练集的记录条数,j是参数的个数. 梯 ...
- 梯度下降优化算法综述与PyTorch实现源码剖析
现代的机器学习系统均利用大量的数据,利用梯度下降算法或者相关的变体进行训练.传统上,最早出现的优化算法是SGD,之后又陆续出现了AdaGrad.RMSprop.ADAM等变体,那么这些算法之间又有哪些 ...
- NN优化方法对照:梯度下降、随机梯度下降和批量梯度下降
1.前言 这几种方法呢都是在求最优解中常常出现的方法,主要是应用迭代的思想来逼近.在梯度下降算法中.都是环绕下面这个式子展开: 当中在上面的式子中hθ(x)代表.输入为x的时候的其当时θ參数下的输出值 ...
- 深度学习必备:随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
- batch、随机、Mini-batch梯度下降
batch梯度下降: 对所有m个训练样本执行一次梯度下降,每一次迭代时间较长: Cost function 总是向减小的方向下降. 随机梯度下降: 对每一个训练样本执行一次梯度下降,但是丢失了向量化带 ...
- L20 梯度下降、随机梯度下降和小批量梯度下降
airfoil4755 下载 链接:https://pan.baidu.com/s/1YEtNjJ0_G9eeH6A6vHXhnA 提取码:dwjq 梯度下降 (Boyd & Vandenbe ...
- [Machine Learning] 梯度下降(BGD)、随机梯度下降(SGD)、Mini-batch Gradient Descent、带Mini-batch的SGD
一.回归函数及目标函数 以均方误差作为目标函数(损失函数),目的是使其值最小化,用于优化上式. 二.优化方式(Gradient Descent) 1.最速梯度下降法 也叫批量梯度下降法Batch Gr ...
随机推荐
- how to drop multiple talbes in oracle use a sigle query
Tool:PL/SQL developer Syntax:SELECT 'DROP TABLE ' || table_name || ';' FROM user_tables; 1.then you ...
- metasploit 渗透测试笔记(基础篇)
0x00 背景 笔记在kali linux(32bit)环境下完成,涵盖了笔者对于metasploit 框架的认识.理解.学习. 这篇为基础篇,并没有太多技巧性的东西,但还是请大家认真看啦. 如果在阅 ...
- Debian9+PHP7+MySQL+Apache2配置Thinkphp运行环境LAMP
因工作需要,配置了一台服务器,运行THINKPHP框架程序,记录配置过程如下: 安装net版Debian9,完成后,如下: 1.配置基本的网络 php install net-tools 安装net- ...
- How Flask Routing Works
@How Flask Routing Works The entire idea of Flask (and the underlying Werkzeug library) is to map UR ...
- DTCoreText 、WKWebView 、UIWebView的比较
DTCoreText .WKWebView .UIWebView的比较 HTML->View 数据解析: WebCore:排版引擎核心,WebCore包含主要以下模块:Loader, Parse ...
- UVa 10735 - Euler Circuit(最大流 + 欧拉回路)
链接: https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...
- apache2 重启、停止、优雅重启、优雅停止
停止或者重新启动Apache有两种发送信号的方法 第一种方法: 直接使用linux的kill命令向运行中的进程发送信号.你也许你会注意到你的系统里运行着很多httpd进程.但你不应该直接对它们中的任何 ...
- [19/04/18-星期四] Java的动态性_动态编译(DynamicCompiler,Dynamic:动态的,Compiler:编译程序)
一.概念 应用场景:如在线评测系统,客户端编写代码,上传到服务器端编译运行:服务器动态加载某些类文件进行编译 /*** * */ package cn.sxt.jvm; import java.io. ...
- Controller如何写的更简化
Controller层相当于MVC中的C,也是安卓或者前端请求的接口. 首先说Controller为什么需要写的更加简化? 第一.Controller是不能复用的: 第二.即便是将Controller ...
- js 日历插件开发
1.HTML完整代码如下: <!DOCTYPE html> <html lang="en"> <head> <meta charset=& ...