第8章 scrapy进阶开发(2)
8-4 selenium集成到scrapy中
其实也没什么好说的直接上代码
这是在middlewares.py中定义的一个class:
from selenium.common.exceptions import TimeoutException
from scrapy.http import HtmlResponse #传递js加载后的源代码,不会返回给download
class JSPageMiddleware(object):
#通过chrome请求动态网页
def process_request(self, request, spider):
if spider.name == "JobBole":
try:
spider.browser.get(request.url)
except TimeoutException:
print('30秒timeout之后,直接结束本页面')
spider.browser.execute_script('window.stop()')
import time
time.sleep(3)
print("访问:{0}".format(request.url)) return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source, encoding="utf-8", request=request)
'''编码默认是unicode'''
spider中的代码:
name = "JobBole"
allowed_domains = ["jobbole.com"]
start_urls = ['http://blog.jobbole.com/all-posts/'] def __init__(self):
'''chrome放在spider中,防止每打开一个url就跳出一个chrome'''
self.browser=webdriver.Chrome(executable_path='E:/chromedriver.exe')
self.browser.set_page_load_timeout(30)
super(JobboleSpider, self).__init__()
dispatcher.connect(self.spider_close,signals.spider_closed) def spider_close(self,spider):
#当爬虫退出的时候关闭Chrome
print("spider closed")
self.browser.quit()
把selenium集成到scrapy中主要改变的就是这两处地方。
以上的在scrapy中嵌入selenium的chrome并不是异步的,所以效率会变差。
这里都是部分代码,完整代码链接:https://github.com/pujinxiao/jobbole_spider
8-5 其余动态网页获取技术介绍-chrome无界面运行、scrapy-splash、selenium-grid, splinter
1.chrome无界面运行
主要是以下代码(不能在windows上运行):
from pyvirtualdisplay import Display
display = Display(visible=0, size=(800, 600))
display.start() browser = webdriver.Chrome()
browser.get()
2.scrapy-splash
Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python实现的,同时使用Twisted和QT。Twisted(QT)用来让服务具有异步处理能力,以发挥webkit的并发能力。
可以在scrapy中处理ajax来抓取动态的数据,没有chrome那么稳定。
更多介绍 传送门
3.selenium-grid(自行百度查看)
4.splinter
8-6 scrapy的暂停与重启
在命令行:scrapy crawl lagou -s JOBDIR=job_info/001
只要按一次 ctrl+c 就会暂停爬虫,重新启动一样的命令再运行一边。
会生成以下文件:
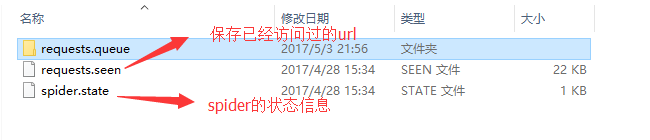
在requests.queue文件中有以下文件:

如果要保存在不同的文件那就修改不同路径就好了,spider会重新从第一个url开始爬取。
8-7 scrapy url去重原理
相关代码都在dupefilter.py中
其实就是做了一个哈希摘要,放在set中,去查新的url是否在set中。
8-8 scrapy telnet服务
详细的介绍在scrapy文档中都有,传送门。
你可以在cmd中监听spider中的变量。先要在控制面板中打开telnet客户端和服务端,在cmd中输入 telnet localhost 6023 即可。
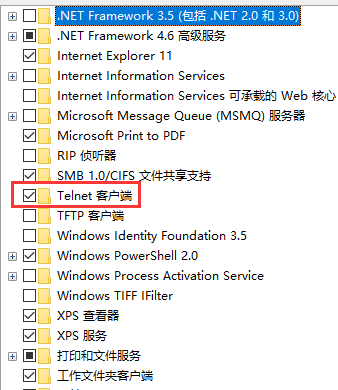
但是不知道为什么,win10中没有telnet服务端,而且我打开telnet的后不能输入字母(待解决)
8-9 spider middleware 详解
平时也没怎么用到,理解的也不够透彻。scrapy的中文文档中也写的很详细,传送门,大家可以参考。
主要是这么几个文件:
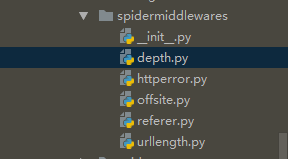
depth.py:爬取深度的设置
httperror.py:状态的设置,比如是不是要把404的也抓取下来,等等。
其他的话自己了解把,需要的时候在深入了解做下笔记。
8-10 scrapy的数据收集 和 8-11 scrapy信号详解
文档说明,数据收集传送门。在工作中没有用到,用到了再细写,这样理解更好。
scrapy信号是非常重要的,之前在selenium中chrome就是用信号量,当spider关闭时,再关闭chrome。信号量详解传送门。
实例就是伯乐在线的例子:
部分代码如下(可以借鉴,其实也包含了8-11信号量的代码):
#收集伯乐在线所有404的url以及404页面数
handle_httpstatus_list = [404] def __init__(self, **kwargs):
self.fail_urls = []
dispatcher.connect(self.handle_spider_closed, signals.spider_closed) def handle_spider_closed(self, spider, reason):
self.crawler.stats.set_value("failed_urls", ",".join(self.fail_urls)) def parse(self, response):
"""
1. 获取文章列表页中的文章url并交给scrapy下载后并进行解析
2. 获取下一页的url并交给scrapy进行下载, 下载完成后交给parse
"""
#解析列表页中的所有文章url并交给scrapy下载后并进行解析
if response.status == 404:
self.fail_urls.append(response.url)
self.crawler.stats.inc_value("failed_url") post_nodes = response.css("#archive .floated-thumb .post-thumb a")
for post_node in post_nodes:
image_url = post_node.css("img::attr(src)").extract_first("")
post_url = post_node.css("::attr(href)").extract_first("")
yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url":image_url}, callback=self.parse_detail)
全部代码移步github:https://github.com/pujinxiao/jobbole_spider/blob/master/bole/spiders/JobBole.py
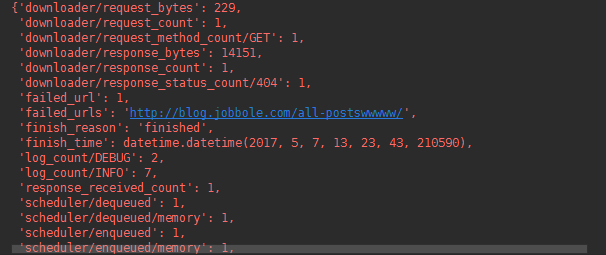
结果: (错误的url也被统计记录下来了)
8-12 scrapy扩展开发
扩展之间看文档,传送门。
作者:今孝
出处:http://www.cnblogs.com/jinxiao-pu/p/6815845.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
觉得好就点个推荐吧!
第8章 scrapy进阶开发(2)的更多相关文章
- 第8章 scrapy进阶开发(1)
8-1 selenium动态网页请求与模拟登录知乎 Ⅰ.介绍selenium 1.什么是selenium:selenium百度百科 2.selenium的构架图: 如果要操作浏览器,还需要一个driv ...
- 【odoo14】第十三章、网站开发(对外服务)
本章我们将介绍一些关于odoo web服务方面的基础知识.进阶的内容,将在第十四章介绍. odoo中的web请求是由python的werkzeug库驱动的.odoo为了操作方便,对werkzeug进行 ...
- 【SharePoint学习笔记】第1章 SharePoint Foundation开发基础
SharePoint Foundation开发基础 第1章 SharePoint Foundation开发基础 SharePoint能做什么 企业信息门户 应用程序工具集(文档库.工作空间.工作流.维 ...
- SharePoint 2010 最佳实践学习总结------第1章 SharePoint Foundation开发基础
----前言 这段时间项目出在验收阶段,不是很忙,就潜心把SharePoint学一下,不求有多深刻,初衷只是先入门再说.后续会发布一系列的学习总结.主要学习的书籍为<SharePoint2010 ...
- 第一章 搭建Qt开发环境
第一章 搭建Qt开发环境 1.到http://download.qt-project.org/archive/上下载Qt的源码包.我下载的是qt-everywhere-opensource-src-4 ...
- 编写高质量代码:改善Java程序的151个建议(第一章:JAVA开发中通用的方法和准则)
编写高质量代码:改善Java程序的151个建议(第一章:JAVA开发中通用的方法和准则) 目录 建议1: 不要在常量和变量中出现易混淆的字母 建议2: 莫让常量蜕变成变量 建议3: 三元操作符的类型务 ...
- Android群英传笔记——第二章:Android开发工具新接触
Android群英传笔记--第二章:Android开发工具新接触 其实这一章并没什么可讲的,前面的安装Android studio的我们可以直接跳过,如果有兴趣的,可以去看看Google主推-Andr ...
- 【STM32H7教程】第2章 STM32H7的开发环境搭建
完整教程下载地址:http://forum.armfly.com/forum.php?mod=viewthread&tid=86980 第2章 STM32H7的开发环境搭建 本章主要为大 ...
- 第三百九十四节,Django+Xadmin打造上线标准的在线教育平台—Xadmin后台进阶开发配置2,以及目录结构说明
第三百九十四节,Django+Xadmin打造上线标准的在线教育平台—Xadmin后台进阶开发配置2,以及目录结构说明 设置后台列表页面可以直接修改字段内容 在当前APP里的adminx.py文件里的 ...
随机推荐
- ceph 存储池PG查看和PG存放OSD位置
1. 查看PG (ceph-mon)[root@controller /]# ceph pg stat 512 pgs: 512 active+clean; 0 bytes data, 1936 MB ...
- Neutron FWaaS 原理
理解概念 Firewall as a Service(FWaaS)是 Neutron 的一个高级服务.用户可以用它来创建和管理防火墙,在 subnet 的边界上对 layer 3 和 layer 4 ...
- 2018-2019-2 网络对抗技术 20165219 Exp3 免杀原理与实践
2018-2019-2 网络对抗技术 20165219 Exp3 免杀原理与实践 实验任务 1 正确使用msf编码器,msfvenom生成如jar之类的其他文件,veil-evasion,自己利用sh ...
- Codechef:Fibonacci Number/FN(二次剩余+bsgs)
题面 传送门 前置芝士 \(bsgs\),\(Cipolla\) 题解 因为题目保证\(p\bmod 10\)是完全平方数,也就是说\(p\bmod 5\)等于\(1\)或\(-1\),即\(5\)是 ...
- AsyncTask的工作原理
AsyncTask是Android本身提供的一种轻量级的异步任务类.它可以在线程池中执行后台任务,然后把执行的进度和最终的结果传递给主线程更新UI.实际上,AsyncTask内部是封装了Thread和 ...
- Jquery选择器 选择一个不存在的元素 为什么不会返回 false
不管找没找到,$()函数都会返回一个jquery对象,这个jquery对象有个length属性,表示找到多少个匹配的DOM元素,为0就是没找到.
- isUserAMonkey? android真逗
QA报了个问题,说是无线热点下面的开关都没了,看了看代码,原来这是android的保护机制. 在涉及到用户信息的功能上,android会通过ActivityManagerNative.isUserAM ...
- opencv 将视频分解成图片和使用本地图片合成视频
代码如下: // cvTest.cpp : Defines the entry point for the console application. #include "stdafx.h&q ...
- SSAS Tabular模式中关系设置不支持直接设置多对多?
在网上文档发现一篇文章 微软BI 之SSAS 系列 - 多维数据集维度用法之一 引用维度 Referenced Dimension 有涉及到SSAS模型的关系设置 但是本人的基于表格模型的 没有关系可 ...
- [转] 如何在 CentOS7 中使用阿里云的yum源
[From] https://www.cnblogs.com/lpbottle/p/7875400.html 1. 备份原来的yum源 mv /etc/yum.repos.d/CentOS-Base. ...