hive grouping sets 等聚合函数
函数说明:
grouping sets
在一个 group by 查询中,根据不同的维度组合进行聚合,等价于将不同维度的 group by 结果集进行 union all
cube
根据 group by 的维度的所有组合进行聚合
rollup
是 cube 的子集,以最左侧的维度为主,从该维度进行层级聚合。
-- grouping sets
select
order_id,
departure_date,
count(*) as cnt
from ord_test
where order_id=410341346
group by order_id,
departure_date
grouping sets (order_id,(order_id,departure_date))
; ---- 等价于以下
group by order_id
union all
group by order_id,departure_date -- cube
select
order_id,
departure_date,
count(*) as cnt
from ord_test
where order_id=410341346
group by order_id,
departure_date
with cube
; ---- 等价于以下
select count(*) as cnt from ord_test where order_id=410341346
union all
group by order_id
union all
group by departure_date
union all
group by order_id,departure_date -- rollup
select
order_id,
departure_date,
count(*) as cnt
from ord_test
where order_id=410341346
group by order_id,
departure_date
with rollup
; ---- 等价于以下
select count(*) as cnt from ord_test where order_id=410341346
union all
group by order_id
union all
group by order_id,departure_date
结果:grouping_sets, cube, rollup

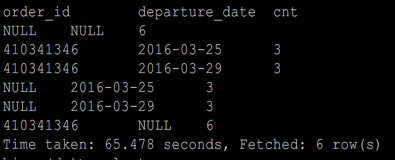
hive grouping sets 等聚合函数的更多相关文章
- hive grouping sets 实现原理
先下结论: 看了hive 1.1.0 grouping sets 实现(从源码及执行计划都可以看出与kylin实现不一样),(前提是可累加,如sum函数)他并没有像kylin一样先按照group by ...
- 9.hive聚合函数,高级聚合,采样数据
本文主要使用实例对Hive内建的一些聚合函数.分析函数以及采样函数进行比较详细的讲解. 一.基本聚合函数 数据聚合是按照特定条件将数据整合并表达出来,以总结出更多的组信息.Hive包含内建的一些基本聚 ...
- 解析数仓OLAP函数:ROLLUP、CUBE、GROUPING SETS
摘要:GaussDB(DWS) ROLLUP,CUBE,GROUPING SETS等OLAP函数的原理解析. 本文分享自华为云社区<GaussDB(DWS) OLAP函数浅析>,作者: D ...
- Hive学习之自己定义聚合函数
Hive支持用户自己定义聚合函数(UDAF),这样的类型的函数提供了更加强大的数据处理功能. Hive支持两种类型的UDAF:简单型和通用型.正如名称所暗示的,简单型UDAF的实现很easy,但因为使 ...
- SQL Server里Grouping Sets的威力
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务).我不是说在生产里使用开发版,也不是说安装盗版SQL Server. 不可能的任务 ...
- SQL Server里Grouping Sets的威力【转】
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务).我不是说在生产里使用开发版,也不是说安装盗版SQL Server. 不可能的任务 ...
- Hive高阶聚合函数 GROUPING SETS、Cube、Rollup
-- GROUPING SETS作为GROUP BY的子句,允许开发人员在GROUP BY语句后面指定多个统计选项,可以简单理解为多条group by语句通过union all把查询结果聚合起来结合起 ...
- Hive高级聚合GROUPING SETS,ROLLUP以及CUBE
scala> import org.apache.spark.sql.hive.HiveContextimport org.apache.spark.sql.hive.HiveContext s ...
- Hive函数:GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
参考:lxw大数据田地:http://lxw1234.com/archives/2015/04/193.htm 数据准备: CREATE EXTERNAL TABLE test_data ( mont ...
随机推荐
- 【HTTP header】【Access-Control-Allow-Credentials】跨域Ajax请求时是否带Cookie的设置
1. 无关Cookie跨域Ajax请求 客户端 以 Jquery 的 ajax 为例: $.ajax({ url : 'http://remote.domain.com/corsrequest', d ...
- postgresql----数据库表约束----FOREIGN KEY
六.FOREIGN KEY ---- 外键约束 外键可以是单个字段,也可以是多个字段.所谓的外键约束就是引用字段必须在被引用字段中存在,除非引用字段部分为NULL或全部为NULL(由MATCH TYP ...
- postgresql----数据库表约束----NOT NULL,DEFAULT,CHECK
数据库表有NOT NULL,DEFAULT,CHECK,UNIQUE,PRIMARY KEY,FOREIGN KEY六种约束. 一.NOT NULL ---- 非空约束 NULL表示没有数据,不表示具 ...
- 170725、Kafka原理与技术
本文转载自:http://www.linkedkeeper.com/detail/blog.action?bid=1016 Kafka的基本介绍 Kafka最初由Linkedin公司开发,是一个分布式 ...
- 各大互联网企业Java面试题汇总,看我如何成功拿到百度的offer
前言 本人Java开发,5年经验,7月初来到帝都,开启面试经历,前后20天左右,主面互联网公司,一二线大公司或者是融资中的创业公司都面试过,拿了一些offer,其中包括奇虎360,最后综合决定还是去百 ...
- Python之numpy基本指令
https://blog.csdn.net/mmm305658979/article/details/78745637 # -*- coding: utf-8 -*- 多加练习才是真 import n ...
- scrapy之定制命令
单爬虫运行 import sys from scrapy.cmdline import execute if __name__ == '__main__': execute(["scrapy ...
- 【我的Android进阶之旅】解决sqlcipher库:java.lang.IllegalStateException: get field slot from row 0 col 0 failed.
一.背景 最近维护公司的大数据SDK,在大数据SDK里面加入了ANR的监控功能,并将ANR的相关信息通过大数据埋点的方式记录到了数据库中,然后大数据上报的时候上报到大数据平台,这样就可以实现ANR性能 ...
- poj1151 Atlantis && cdoj 1600艾尔大停电 矩形面积并
题目: Atlantis Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 23758 Accepted: 8834 Des ...
- uva 1048 最短路的建图 (巧,精品)
大白书 P341这题说的是给了NT种飞机票,给了价钱和整个途径,给了nI条要旅游的路线.使用飞机票都必须从头第一站开始坐,可以再这个路径上的任何一点下飞机一但下飞机了就不能再上飞机,只能重新买票,对于 ...