Spark.ML之PipeLine学习笔记
地址:
#导入向量和模型from pyspark.ml.linalg importVectorsfrom pyspark.ml.classification importLogisticRegression#准备训练数据# Prepare training data from a list of (label, features) tuples.training = spark.createDataFrame([(1.0,Vectors.dense([0.0,1.1,0.1])),(0.0,Vectors.dense([2.0,1.0,-1.0])),(0.0,Vectors.dense([2.0,1.3,1.0])),(1.0,Vectors.dense([0.0,1.2,-0.5]))],["label","features"])#创建回归实例,这个实例是Estimator# Create a LogisticRegression instance. This instance is an Estimator.lr =LogisticRegression(maxIter=10, regParam=0.01)#打印出参数和文档# Print out the parameters, documentation, and any default values.print"LogisticRegression parameters:\n"+ lr.explainParams()+"\n"#使用Ir中的参数训练出Model1# Learn a LogisticRegression model. This uses the parameters stored in lr.model1 = lr.fit(training)# Since model1 is a Model (i.e., a transformer produced by an Estimator),# we can view the parameters it used during fit().# This prints the parameter (name: value) pairs, where names are unique IDs for this# LogisticRegression instance.#查看model1在fit()中使用的参数print"Model 1 was fit using parameters: "print model1.extractParamMap()#修改其中的一个参数# We may alternatively specify parameters using a Python dictionary as a paramMapparamMap ={lr.maxIter:20}#覆盖掉paramMap[lr.maxIter]=30# Specify 1 Param, overwriting the original maxIter.#更新参数对paramMap.update({lr.regParam:0.1, lr.threshold:0.55})# Specify multiple Params.# You can combine paramMaps, which are python dictionaries.#新的参数,合并为两组参数对paramMap2 ={lr.probabilityCol:"myProbability"}# Change output column nameparamMapCombined = paramMap.copy()paramMapCombined.update(paramMap2)#重新得到model2并拿出来参数看看# Now learn a new model using the paramMapCombined parameters.# paramMapCombined overrides all parameters set earlier via lr.set* methods.model2 = lr.fit(training, paramMapCombined)print"Model 2 was fit using parameters: "print model2.extractParamMap()#准备测试的数据# Prepare test datatest = spark.createDataFrame([(1.0,Vectors.dense([-1.0,1.5,1.3])),(0.0,Vectors.dense([3.0,2.0,-0.1])),(1.0,Vectors.dense([0.0,2.2,-1.5]))],["label","features"])# Make predictions on test data using the Transformer.transform() method.# LogisticRegression.transform will only use the 'features' column.# Note that model2.transform() outputs a "myProbability" column instead of the usual# 'probability' column since we renamed the lr.probabilityCol parameter previously.prediction = model2.transform(test)#得到预测的DataFrame打印出预测中的选中列selected = prediction.select("features","label","myProbability","prediction")for row in selected.collect():print row
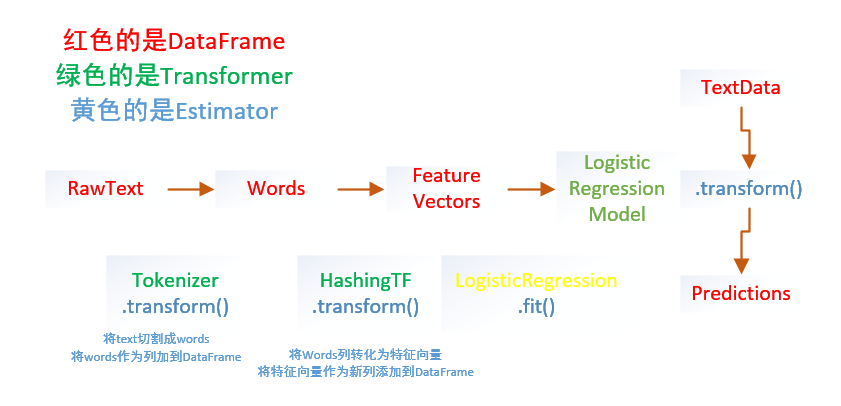
from pyspark.ml importPipelinefrom pyspark.ml.classification importLogisticRegressionfrom pyspark.ml.feature importHashingTF,Tokenizer#准备测试数据# Prepare training documents from a list of (id, text, label) tuples.training = spark.createDataFrame([(0L,"a b c d e spark",1.0),(1L,"b d",0.0),(2L,"spark f g h",1.0),(3L,"hadoop mapreduce",0.0)],["id","text","label"])#构建机器学习流水线# Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr.tokenizer =Tokenizer(inputCol="text", outputCol="words")hashingTF =HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")lr =LogisticRegression(maxIter=10, regParam=0.01)pipeline =Pipeline(stages=[tokenizer, hashingTF, lr])#训练出model# Fit the pipeline to training documents.model = pipeline.fit(training)#测试数据# Prepare test documents, which are unlabeled (id, text) tuples.test = spark.createDataFrame([(4L,"spark i j k"),(5L,"l m n"),(6L,"mapreduce spark"),(7L,"apache hadoop")],["id","text"])#预测,打印出想要的结果# Make predictions on test documents and print columns of interest.prediction = model.transform(test)selected = prediction.select("id","text","prediction")for row in selected.collect():print(row)
Spark.ML之PipeLine学习笔记的更多相关文章
- ML机器学习导论学习笔记
机器学习的定义: 机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论.统计学.逼近论.凸分析.算法复杂度理论等多门学科.专门研究计算机怎样模拟或实现人类的学习行为,以 ...
- Spark ML下实现的多分类adaboost+naivebayes算法在文本分类上的应用
1. Naive Bayes算法 朴素贝叶斯算法算是生成模型中一个最经典的分类算法之一了,常用的有Bernoulli和Multinomial两种.在文本分类上经常会用到这两种方法.在词袋模型中,对于一 ...
- spark ML pipeline 学习
一.pipeline 一个典型的机器学习过程从数据收集开始,要经历多个步骤,才能得到需要的输出.这非常类似于流水线式工作,即通常会包含源数据ETL(抽取.转化.加载),数据预处理,指标提取,模型训练与 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- 使用spark ml pipeline进行机器学习
一.关于spark ml pipeline与机器学习 一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的 ...
- Spark ML Pipeline简介
Spark ML Pipeline基于DataFrame构建了一套High-level API,我们可以使用MLPipeline构建机器学习应用,它能够将一个机器学习应用的多个处理过程组织起来,通过在 ...
- 机器学习框架ML.NET学习笔记【6】TensorFlow图片分类
一.概述 通过之前两篇文章的学习,我们应该已经了解了多元分类的工作原理,图片的分类其流程和之前完全一致,其中最核心的问题就是特征的提取,只要完成特征提取,分类算法就很好处理了,具体流程如下: 之前介绍 ...
- 机器学习框架ML.NET学习笔记【7】人物图片颜值判断
一.概述 这次要解决的问题是输入一张照片,输出人物的颜值数据. 学习样本来源于华南理工大学发布的SCUT-FBP5500数据集,数据集包括 5500 人,每人按颜值魅力打分,分值在 1 到 5 分之间 ...
随机推荐
- Qt实现停靠功能
- 打开开源项目总得.md文件
google了一些: 78 Tools for Writing and Previewing Markdown http://mashable.com/2013/06/24/markdown-too ...
- C#:WPF绘制问题
1.问题描述:切换画笔后,鼠标呈现画笔,但绘制界面需要点击后才能绘制,体验比较差 注:如果将切换为画笔或橡皮擦的功能放在二级菜单中则无次问题 解决方法(大体如此): 1)在第三方中,先创建完绘制画面和 ...
- postgresql压力测试工具用法以及参数解读
pgbench是PostgreSQL自带的一个数据库压力测试工具, 支持TPC-B测试模型, 或自定义测试模型. 自定义测试模型支持元命令, 调用shell脚本, 设置随机数, 变量等等. 支持3种异 ...
- ASP.NET数据验证控件的常用的属性
一.非空验证 RequiredFieldValidator ControlToValidate 所验证的控件ID Text 出错时的提示的文本 ErrorMessage 提交给Validati ...
- hdwiki 软件包结构
HDWiki软件包结构转载自http://www.chinabaike.com/z/shenghuo/pc/2011/0414/814308.html 根目录下的PHP文件 ...
- [HTML]DIV+CSS 文字垂直居中
在说到这个问题的时候,也许有人会问CSS中不是有vertical-align属性来设置垂直居中的吗?即使是某些浏览器不支持我只需做少许的CSS Hack技术就可以啊!所以在这里我还要啰嗦两句,CSS中 ...
- 《Effective C++》读书摘要
http://www.cnblogs.com/fanzhidongyzby/archive/2012/11/18/2775603.html 1.让自己习惯C++ 条款01:视C++为一个语言联邦 条款 ...
- mongoDB Replica集群配置(1主+1从+1仲裁)
1.mongoDB节点介绍 主节点(Primary) 在复制集中,主节点是唯一能够接收写请求的节点.MongoDB在主节点进行写操作,并将这些操作记录到主节点的oplog中.而从节点将会从oplog复 ...
- 关于Filter的配置
配置代码: <filter> <display-name>OneFilter</display-name> <filter-name>OneFilte ...