SQL Server-聚焦过滤索引提高查询性能(十)
前言
这一节我们还是继续讲讲索引知识,前面我们讲了聚集索引、非聚集索引以及覆盖索引等,在这其中还有一个过滤索引,通过索引过滤我们也能提高查询性能,简短的内容,深入的理解,Always to review the basics。
过滤索引,在查询条件上创建非聚集索引(1)
过滤索引是SQL 2008的新特性,被应用在表中的部分行,所以利用过滤索引能够提高查询,相对于全表扫描它能减少索引维护和索引存储的成本。当我们在索引上应用WHERE条件时就是过滤索引。也就是满足如下格式:
CREATE NONCLUSTERED INDEX <index name>
ON <table> (<columns>)
WHERE <criteria>;
GO
下面我们来看一个简单的查询
USE AdventureWorks2012
GO SELECT SalesOrderDetailID, UnitPrice
FROM Sales.SalesOrderDetail
WHERE UnitPrice >
GO
上述列中未建立任何索引,当然除了SalesOrderDetailID默认创建的聚集索引,这种情况下我们能够猜想到其执行的查询计划必然是主键创建的聚集索引扫描,如下

上述我们已经说过此时未在查询条件上创建索引,所以此时必然走的是主键创建的聚集索引,接下来我们首先在UnitPrice列上创建非聚集索引来提高查询性能,
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_UnitPrice
ON Sales.SalesOrderDetail(UnitPrice)
此时我们再来比较二者查询开销
USE AdventureWorks2012
GO DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERS SELECT SalesOrderDetailID, UnitPrice
FROM AdventureWorks2012.Sales.SalesOrderDetail WITH(INDEX([PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID]))
WHERE UnitPrice >
GO SELECT SalesOrderDetailID, UnitPrice
FROM Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_UnitPrice]))
WHERE UnitPrice >

此时在查询条件上建立了非聚集索引之后,查询开销提升的非常明显,提升达到了90%以上,因为非聚集索引也会引用了主键创建的聚集索引,所以这个时候不会导致Bookmark Lookup或者Key Lookup查找。接下来我们我们再添加一个带有条件的非聚集索引即过滤索引
CREATE NONCLUSTERED INDEX idxwhere_SalesOrderDetail_UnitPrice
ON Sales.SalesOrderDetail(UnitPrice)
WHERE UnitPrice >
此时我们再来看看创建了过滤索引之后和之前非聚集索引性能开销差异:
USE AdventureWorks2012
GO DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERS SELECT SalesOrderDetailID, UnitPrice
FROM AdventureWorks2012.Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_UnitPrice]))
WHERE UnitPrice > SELECT SalesOrderDetailID, UnitPrice
FROM Sales.SalesOrderDetail WITH(INDEX([idxwhere_SalesOrderDetail_UnitPrice]))
WHERE UnitPrice >
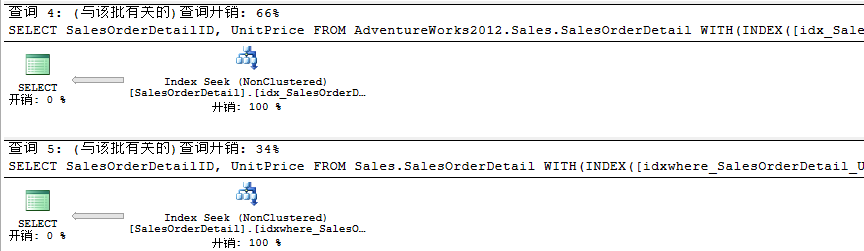
此时我们知道创建的非聚集过滤索引与传统创建的非聚集索引相比,我们的查询接近减少了一半。
唯一过滤索引
唯一过滤索引对于所有列必须唯一且不为空(只允许一个NULL存在)也是非常好的解决方案,所以此时在创建唯一过滤索引时需要将NULL值除外,比如如下:
CREATE UNIQUE NONCLUSTERED INDEX uq_fix_Customers_Email
ON Customers(Email)
WHERE Email IS NOT NULL
GO
过滤索引结合INCLUDE
当我们再添加一个额外列时,使用默认主键创建的聚集索引时,此时会走聚集索引扫描,然后我们在查询条件上创建一个过滤索引,我们强制使用这个过滤索引时,此时由于添加额外列,会导致需要返回到基表中再去获取数据,所以也就造成了Key Lookup查找,如下:
USE AdventureWorks2012
GO SELECT SalesOrderDetailID, UnitPrice, UnitPriceDiscount
FROM Sales.SalesOrderDetail
WHERE UnitPrice >
GO

此时我们需要用INCLUDE来包含额外列。
CREATE NONCLUSTERED INDEX [idx_SalesOrderDetail_UnitPrice] ON Sales.SalesOrderDetail(UnitPrice) INCLUDE(UnitPriceDiscount)
我们再创建一个过滤索引同时包括额外列
CREATE NONCLUSTERED INDEX [idxwhere_SalesOrderDetail_UnitPrice] ON Sales.SalesOrderDetail(UnitPrice) INCLUDE(UnitPriceDiscount)
WHERE UnitPrice >
接下来再来执行比较添加过滤索引和未添加过滤索引同时都包括了额外列的性能查询差异。
SELECT SalesOrderDetailID, UnitPrice, UnitPriceDiscount
FROM AdventureWorks2012.Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_UnitPrice]))
WHERE UnitPrice > SELECT SalesOrderDetailID, UnitPrice, UnitPriceDiscount
FROM Sales.SalesOrderDetail WITH(INDEX([idxwhere_SalesOrderDetail_UnitPrice]))
WHERE UnitPrice >

此时性能用INCLUDE来包含额外列性能也得到了一定的改善。
过滤索引,在主键上创建非聚集索引(2)
在第一个案列中,我们可以直接在查询列上创建非聚集索引,因为其类型是数字类型,要是查询条件是字符类型呢?首选现在我们先创建一个测试表
USE TSQL2012
GO CREATE TABLE dbo.TestData
(
RowID integer IDENTITY NOT NULL,
SomeValue VARCHAR(max) NOT NULL,
StartDate date NOT NULL,
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
);
添加10万条测试数据
USE TSQL2012
GO INSERT dbo.TestData WITH (TABLOCKX)
(SomeValue, StartDate)
SELECT
CAST(N.n AS VARCHAR(max)) + 'JeffckyWang',
DATEADD(DAY, (N.n - ) % , '')
FROM dbo.Nums AS N
WHERE
N.n >=
AND N.n < ;
如果我们需要获取表TestData中SomeValue = 'JeffckyWang',此时我们想要在SomeValue上创建一个非聚集索引然后进行过滤,如下
USE TSQL2012
GO CREATE NONCLUSTERED INDEX idx_noncls_somevalue
ON dbo.TestData(SomeValue)
WHERE SomeValue = 'JeffckyWang'

更新
SQL Server对创建索引大小有限制,最大是900字节,上述直接写的VARCHAR(MAX),所以会出错,切记,切记。
此时我们在主键上创建非聚集索引,我们在主键RowID上创建一个过滤索引且SomeValue = 'JeffckyWang',然后返回数据,如下:
CREATE NONCLUSTERED INDEX idxwhere_noncls_somevalue
ON dbo.TestData(RowID)
WHERE SomeValue = 'JeffckyWang'
下面我们来对比建立过滤索引前后查询计划结果:
USE TSQL2012
GO SELECT RowID, SomeValue, StartDate
FROM dbo.TestData WITH(INDEX([idx_pk_rowid]))
WHERE SomeValue = 'JeffckyWang' SELECT RowID, SomeValue, StartDate
FROM dbo.TestData WITH(INDEX([idxwhere_noncls_somevalue]))
WHERE SomeValue = 'JeffckyWang'
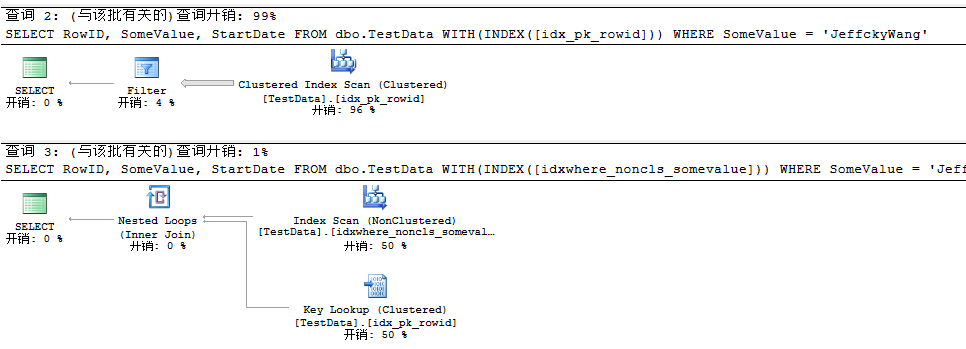
然后结合之前所学,移除Key Lookup,对创建的过滤索引进行INCLUDE。
CREATE NONCLUSTERED INDEX [idxwhere_noncls_somevalue] ON dbo.TestData(RowID) INCLUDE(SomeValue,StartDate)
WHERE SomeValue = 'JeffckyWang'
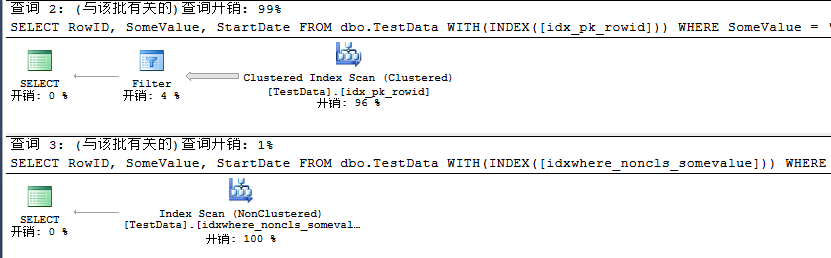
从这里看出,无论是对查询条件创建过滤索引还是对主键创建过滤索引,我们都可以通过结合之前所学来提高查询性能。
我们从开头就一直在讲创建过滤索引,那么创建过滤索引优点的条件到底是什么?
(1)只能通过非聚集索引进行创建。
(2)如果在视图上创建过滤索引,此视图必须是持久化视图。
(3)不能在全文索引上创建过滤索引。
过滤索引的优点
(1)减少索引维护成本:对于增、删、改等操作不会耗费太多的成本,因为一个过滤索引的重建不需要耗时太多时间。
(2)减少存储成本:过滤索引的存储占用空间很小。
(3)更精确的统计:通过在WHERE条件上创建过滤索引比全表统计结果更加精确。
(4)优化查询性能:通过查询计划可以看出其高效性。
讲到这里为止,一直陈述的是过滤索引的好处和优点,已经将其捧上天了,其实其缺点也是显而易见。
过滤索引缺点
最大的缺点则是查询条件的限制。其查询条件仅限于
<filter_predicate> ::=
<conjunct> [ AND <conjunct> ] <conjunct> ::=
<disjunct> | <comparison> <disjunct> ::=
column_name IN (constant ,...n)
过滤条件仅限于AND、|、IN。比较条件仅限于 { IS | IS NOT | = | <> | != | > | >= | !> | < | <= | !< },所以如下利用LIKE不行
CREATE NONCLUSTERED INDEX [idxwhere_noncls_somevalue] ON dbo.TestData(RowID) INCLUDE(SomeValue,StartDate)
WHERE SomeValue LIKE 'JeffckyWang%'

如下可以
USE AdventureWorks2012
GO CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_ModifiedDate
ON Sales.SalesOrderDetail(ModifiedDate)
WHERE ModifiedDate >= '2008-01-01' AND ModifiedDate <= '2008-01-07'
GO
如下却不行
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_ModifiedDate
ON Sales.SalesOrderDetail(ModifiedDate)
WHERE ModifiedDate = GETDATE()
GO

变量对过滤索引影响
上述我们创建过滤索引在查询条件上直接定义的字符串,如下:
CREATE NONCLUSTERED INDEX idxwhere_SalesOrderDetail_UnitPrice
ON Sales.SalesOrderDetail(UnitPrice)
WHERE UnitPrice >
如果定义的是变量,利用变量来进行比较会如何呢?首先我们创建一个过滤索引
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_ProductID
ON Sales.SalesOrderDetail (ProductID)
WHERE ProductID =
利用变量来和查询条件比较,强制使用过滤索引(默认情况下走聚集索引)
USE AdventureWorks2012
GO DECLARE @ProductID INT
SET @ProductID = SELECT ProductID
FROM Sales.SalesOrderDetail WITH(INDEX([idx_SalesOrderDetail_ProductID]))
WHERE ProductID = @ProductID

查看查询执行计划结果却出错了,此时我们需要添加OPTION重新编译,如下:
USE AdventureWorks2012
GO DECLARE @ProductID INT
SET @ProductID = SELECT ProductID
FROM Sales.SalesOrderDetail
WHERE ProductID = @ProductID
OPTION(RECOMPILE)

上述利用变量来查询最后通过OPTION重新编译在SQL Server 2012中测试好使,至于其他版本未知,参考资料【The Pains of Filtered Indexes】。
总结
本节我们学习了通过过滤索引来提高查询性能,同时也给出了其不同的场景以及其使用优点和明显的缺点。简短的内容,深入的理解,我们下节再会,good night。
SQL Server-聚焦过滤索引提高查询性能(十)的更多相关文章
- SQL Server-聚焦过滤索引提高查询性能
前言 这一节我们还是继续讲讲索引知识,前面我们讲了聚集索引.非聚集索引以及覆盖索引等,在这其中还有一个过滤索引,通过索引过滤我们也能提高查询性能,简短的内容,深入的理解,Always to revie ...
- SQL Server 百万级数据提高查询速度的方法
1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描. 2.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉 ...
- SQL Server 百万级数据提高查询速度的方法(转)
1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描.2.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及 ...
- T-SQL查询高级--理解SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤
写在前面:这是第一篇T-SQL查询高级系列文章.但是T-SQL查询进阶系列还远远没有写完.这个主题放到高级我想是因为这个主题需要一些进阶的知识作为基础..如果文章中有错误的地方请不吝指正.本篇文章 ...
- 【SQL Server性能优化】运用SQL Server的全文检索来提高模糊匹配的效率
原文:[SQL Server性能优化]运用SQL Server的全文检索来提高模糊匹配的效率 今天去面试,这个公司的业务需要模糊查询数据,之前他们通过mongodb来存储数据,但他们说会有丢数据的问题 ...
- SQL Server优化技巧——如何避免查询条件OR引起的性能问题
原文:SQL Server优化技巧--如何避免查询条件OR引起的性能问题 之前写过一篇博客"SQL SERVER中关于OR会导致索引扫描或全表扫描的浅析",里面介绍了OR可能会引起 ...
- SQL Server 列存储索引强化
SQL Server 列存储索引强化 SQL Server 列存储索引强化 1. 概述 2.背景 2.1 索引存储 2.2 缓存和I/O 2.3 Batch处理方式 3 聚集索引 3.1 提高索引创建 ...
- SQL查询优化:详解SQL Server非聚集索引(转载)
本文是转载,原文地址 http://tech.it168.com/a2011/1228/1295/000001295176.shtml 在SQL SERVER中,非聚集索引其实可以看作是一个含有聚集索 ...
- SQL Server 列存储索引 第二篇:设计
列存储索引可以是聚集的,也可以是非聚集的,用户可以在表上创建聚集的列存储索引(Clustered Columnstore Index)或非聚集的列存储索引(Nonclustered Columnsto ...
随机推荐
- 【探索】机器指令翻译成 JavaScript
前言 前些时候研究脚本混淆时,打算先学一些「程序流程」相关的概念.为了不因太枯燥而放弃,决定想一个有趣的案例,可以边探索边学. 于是想了一个话题:尝试将机器指令 1:1 翻译 成 JavaScript ...
- InnoDB关键特性学习笔记
插入缓存 Insert Buffer Insert Buffer是InnoDB存储引擎关键特性中最令人激动与兴奋的一个功能.不过这个名字可能会让人认为插入缓冲是缓冲池中的一个组成部分.其实不然,Inn ...
- Android Notification 详解——基本操作
Android Notification 详解 版权声明:本文为博主原创文章,未经博主允许不得转载. 前几天项目中有用到 Android 通知相关的内容,索性把 Android Notificatio ...
- 深入理解 JavaScript,以及 Linux 下的开发调试工具
前言 JavaScript 是我接触到的第二门编程语言,第一门是 C 语言.然后才是 C++.Java 还有其它一些什么.所以我对 JavaScript 是非常有感情的,毕竟使用它有十多年了.早就想写 ...
- SQL Server2008R2 在windows8上安装,出现“兼容性”和 “执行未经授权的操作”的错误!
本人是windows8.1的操作系统,亲测安装成功 解决方法如下: 1.卸载干净sql Server2008r2,包括注册表内容,删除c盘下的安装路径! 2.关闭防火墙(这步很重要) 3.断开网络连接 ...
- H3 BPM让天下没有难用的流程之产品概述
一.产品简介 BPM(Business Process Management),是指根据业务环境的变化,推进人与人之间.人与系统之间以及系统与系统之间的整合及调整的经营方法与解决方案的IT工具. H3 ...
- Java集合类--温习笔记
最近面试发现自己的知识框架有好多问题.明明脑子里知道这个知识点,流程原理也都明白,可就是说不好,不知道是自己表达技能没点,还是确实是自己基础有问题.不管了,再巩固下基础知识总是没错的,反正最近空闲时间 ...
- FineReport关于tomcat集群部署的方案
多台服务器集群后,配置权限.数据连接.模板.定时调度等,只能每台服务器一个个配置,不会自动同步到所有服务器. 针对上述情况,在FineReport中提供新集群部署插件,将xml配置文件.finedb/ ...
- 换个角度看微信小程序[推荐]
去年参加几次技术沙龙时,我注意到一个有意思的现象:与之前大家统一接受的换名片不同,有些人并不愿意被添加微信好友--"不好意思,不熟的人不加微信". 这个现象之所以有意思,是因为名片 ...
- iOS开发系列--数据存取
概览 在iOS开发中数据存储的方式可以归纳为两类:一类是存储为文件,另一类是存储到数据库.例如前面IOS开发系列-Objective-C之Foundation框架的文章中提到归档.plist文件存储, ...