关于 MySQL UTF8 编码下生僻字符插入失败/假死问题的分析
原文:http://my.oschina.net/leejun2005/blog/343353
目录[-]
1、问题:mysql 遇到某些中文插入异常
最近有同学反馈了这样一个问题:

上述语句在脚本中 load 入库的时候会 hang 住,web 前端、命令行操作则要么抛出
Incorrect string value: '\xF0\xA1\x8B\xBE\xE5\xA2...' for column 'name',
要么存入MYSQL数据库的内容会被截断或者乱码,而换做其它的中文则一切正常。
嗯,看起来有点奇怪哈,按理说 utf8 编码是覆盖了所有中文的,不应该出现上述问题。
2、原因:此 utf8 非彼 utf8
那我们先来看看插入异常的中文和正常的中文有啥区别:
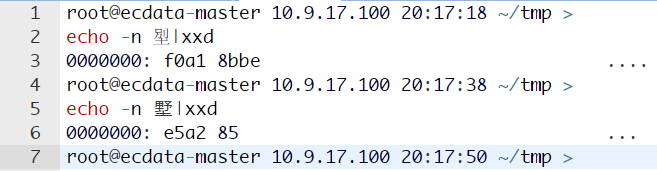
可以看到上面插入异常的文字占了 4 个字节,而我们插入正常的则只占了 3 个字节。但是 utf8 字符编码不就是可变长,支持 1-4 字节的么?会和这个有关?
嗯,看看官方文档就知道了:
10.1.10.6 The utf8mb4 Character Set (4-Byte UTF-8 Unicode Encoding)
The character set named utf8 uses a maximum of three bytes per character and contains only BMP characters. As of MySQL 5.5.3, the utf8mb4 character set uses a maximum of four bytes per character supports supplemental characters:
- For a BMP character, utf8 and utf8mb4 have identical storage characteristics: same code values, same encoding, same length.
- For a supplementary character, utf8 cannot store the character at all, while utf8mb4 requires four bytes to store it. Since utf8 cannot store the character at all, you do not have any supplementary characters in utf8 columns and you need not worry about converting characters or losing data when upgrading utf8 data from older versions of MySQL.
- utf8mb4 is a superset of utf8.
由官方文档可知,mysql 支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多文种平面(BMP)。也就是说,任何不在基本多文本平面的 Unicode字符,都无法使用 Mysql 的 utf8 字符集存储。包括 Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和很多不常用的汉字,以及任何新增的 Unicode 字符等等。
最初的 UTF-8 格式使用一至六个字节,最大能编码 31 位字符。最新的 UTF-8 规范只使用一到四个字节,最大能编码21位,正好能够表示所有的 17个 Unicode 平面。
utf8 是 Mysql 中的一种字符集,只支持最长三个字节的 UTF-8字符,也就是 Unicode 中的基本多文本平面。
Mysql 中的 utf8 为什么只支持持最长三个字节的 UTF-8字符呢?我想了一下,可能是因为 Mysql 刚开始开发那会,Unicode 还没有辅助平面这一说呢。那时候,Unicode 委员会还做着 “65535 个字符足够全世界用了”的美梦。Mysql 中的字符串长度算的是字符数而非字节数,对于 CHAR 数据类型来说,需要为字符串保留足够的长。当使用 utf8 字符集时,需要保留的长度就是 utf8 最长字符长度乘以字符串长度,所以这里理所当然的限制了 utf8 最大长度为 3,比如 CHAR(100) Mysql 会保留 300字节长度。至于后续的版本为什么不对 4 字节长度的 UTF-8 字符提供支持,我想一个是为了向后兼容性的考虑,还有就是基本多文种平面之外的字符确实很少用到。
要在 Mysql 中保存 4 字节长度的 UTF-8 字符,需要使用 utf8mb4 字符集,但只有 5.5.3 版本以后的才支持(查看版本: select version();)。我觉得,为了获取更好的兼容性,应该总是使用 utf8mb4 而非 utf8. 对于 CHAR 类型数据,utf8mb4 会多消耗一些空间,根据 Mysql 官方建议,使用 VARCHAR 替代 CHAR。
3、解决方案
知道原因了,当然得谈谈有哪些方案可以解决开头的问题。
3.1 升级 mysql 版本,并将utf8字符集升级到utf8mb4
升级你的 mysql 到 5.5.3 之后即可,查看当前环境版本:
|
1
|
select version(); |
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8bp4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。
所以好的技术就是,采用对当前而言最好的解决方案,然后再逐步迭代满足新的需求。
3.1.1 直接修改表结构
|
1
2
3
4
5
6
|
--修改数据库字符集ALTER DATABASE test CHARACTER SET = utf8mb4;--修改表字符集alter table test convert to character set utf8mb4;--修改字符字符集ALTER TABLE `test` CHANGE COLUMN `name` `name` varchar(12) CHARACTER SET utf8mb4; |
3.1.2 修改数据库默认配置
|
1
2
3
4
5
6
7
|
[client]default-character-set = utf8mb4[mysqld]character-set-server=utf8mb4collation-server=utf8mb4_unicode_ci[mysql]default-character-set = utf8mb4 |
P.S. 如果你使用的是java语言,需要将jdbc驱动包升级到 mysql-connector-java-5.1.14.jar。
3.2 强行过滤掉生僻字符串
从业务和技术的角度综合考虑,可以做个折中,将生僻字符串提前过滤掉,因为这类字符串本来就使用的很少,即使存进数据库了,展示、查询的时候也会多少有其它的问题,不如直接过滤掉,mysql 不支持四字节的 utf8 一方面可能是历史包袱,另一方面估计也是为了省空间。
3.2.1 shell 过滤
比如,咱们可以直接先用 sed、awk、python、perl 处理下要 load 入库的脚本,将四字节的生僻字全过滤再入库:
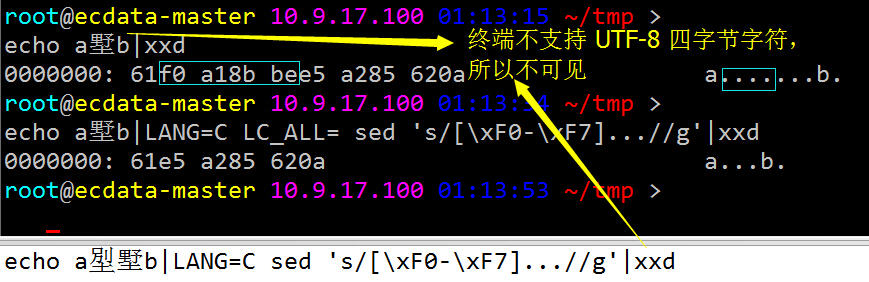
3.2.2 java 中的过滤操作
判断MySql支持Unicode字符的方法,伪码为:
|
1
2
3
4
5
|
for i=1->nint c=str.codePointAt(i);if (c<0x0000||c>0xffff) { return false;} |
稍作修改即可。
3.3 避开客户端乱码:二进制存储与查询
为避免web页面或者终端本身不支持utf8四字节,可以采用二进制的方式来操作
|
1
2
3
4
5
|
create table t1(name varchar(20) charset utf8mb4);insert into t1 values(0xF0A09080);set charset binary;select * from t1; |
4、应用、系统对 utf-8 四字节字符的支持
最后顺便总结下4字节utf8字符的系统支持情况:
- windows xp: 我所测试的xp系统都不支持4字节utf8字符, 浏览器用占位符显示
- windows 7: 支持4字节utf8字符
- mac os x: 支持4字节utf8字符
- iPhone/iPad: 支持4字节utf8字符
- 许多的数据库软件或者shell终端都不支持4字节utf8字符, 比如 Navicat、SecureCRT
以 php 场景为例说明:
- php连接会话设置编码utf8, mysql后端字段为text character set utf8: 写入内容从4字节utf8字符处被截断
- php连接会话设置编码utf8mb4, mysql后端字段为text character set utf8: 内容可以完整写入, 但是4字节utf8字符被替换为问号"?"
- php连接会话设置编码utf8mb4, mysql后端字段为text character set utf8mb4: 完整支持4字节utf8字符
从平台支持上来看, 随着winxp的逐步淘汰, 对4字节utf8字符的支持还是有必要的.
官方手册对utf8mb4字符的说明中指出, utf8mb4是utf8的超集, 因此可放心升级.
5、最后的问题
看到这里,不知道细心的你有没有发现,本文的代码为毛都是图呢?要知道我自己写文章很少把代码搞成图的,那是因为。。。
哇哈哈,真是哪壶不开提哪壶啊。。。。。。。。。

6、Refer:
[1] 谈谈字符集与字符编码
http://my.oschina.net/leejun2005/blog/232732#OSC_h3_4
[2] sed matching any ascii code/hex byte
http://forums.gentoo.org/viewtopic-t-770576-start-0.html
[3] 10.1.10.6 The utf8mb4 Character Set (4-Byte UTF-8 Unicode Encoding)
http://dev.mysql.com/doc/refman/5.5/en/charset-unicode-utf8mb4.html
[4] Mysql 中的 utf8
[5] Mysql中4字节UTF8字符集问题
http://bbs.chinaunix.net/thread-3766853-1-1.html
[6] MySQL,UTF-8和emoji
http://shadyxu.com/mysql_utf8.html
[7] 关于MYSQL截断内容问题解决
http://www.momotime.me/2014/10/mysql-utf8mb4/
[8] MySQL储存4字节字符
http://www.web-tinker.com/article/20643.html
[9] 关于UTF-8编码的MySql抛出incorrect string value的问题
http://blog.csdn.net/tannasu/article/details/8064021
[10] 关于MYSQL截断内容问题解决
http://daiweiyang.com/mysql_data_truncated/
[11] mysql汉字16进制编码转换方法
关于 MySQL UTF8 编码下生僻字符插入失败/假死问题的分析的更多相关文章
- mysql utf8编码
做微信项目,报错 "Incorrect string value: '\\xF0\\x9F\\x98\\x8B' for column 'nickname' at row 1" 原 ...
- UTF-8编码下'\u7528\u6237'转换为中文汉字'用户'
UTF-8编码下'\u7528\u6237'转换为中文'用户' 一.前言 有过多次,在开发项目中遇见设置文件编码格式为UTF-8,但是打开该文件出现类似\u7528这样的数据,看也看不懂,也不是平常见 ...
- python利用utf-8编码判断中文字符
下面这个小工具包含了 判断unicode是否是汉字,数字,英文,或者其他字符. 全角符号转半角符号. unicode字符串归一化等工作. 还有一个能处理多音字的汉字转拼音的程序,还在整理中. #!/u ...
- mysql utf8编码设置
1.建立数据库时指定数据库db_test为utf8编码.: create database db_test character set utf8; 修改数据库db_test编码的命令为: alter ...
- PHP怎么把经过UTF-8编码的中文字符转换成正常的中文
问题的场景: html 为utf-8编码<meta http-equiv="Content-Type" content="text/html; charset=UT ...
- jquery ajax到servlet出现中文乱码(utf-8编码下)
个人遇到的该问题有两大类: 第一类很普遍,就是jsp页面编码没有规定,servlet中接收参数没有转码,response没有使用setContentType()和setCharacterEncodin ...
- 解决linux下终端无法输入的假死问题
有时在linux下shell终端中,会突然出现终端应用卡死,无法接受键盘输入, 但是其它分屏, 系统都是正常的.这本来是一个终端的很老的功能, 叫软件流控制(XON/XOFF flow control ...
- UTF-8编码与GBK编码下的字符长度
源码: package lsh.java.charset; import java.nio.charset.Charset; public class LengthOfUTF_8 { public s ...
- mysql utf8字符集下使用DES_ENCRYPT
DES_ENCRYPT() 加密字符串后内容为空 改变字符集latin1 可以保存和解密(DES_DECRYPT)
随机推荐
- 采用libsvm进行mnist训练
#coding:utf8 import cPickle import gzip import numpy as np from sklearn.svm import libsvm class SVM( ...
- 套接字I/O模型-重叠I/O
重叠模型的基本设计原理是让应用程序使用重叠的数据结构,一次投递一个或多个WinsockI/O请求.针对那些提交的请求,在它们完成之后,应用程序可为它们提供服务.模型的总体设计以Windows重叠I/O ...
- sed的实际用法举例
sed:Stream Editor文本流编辑,sed是一个“非交互式的”面向字符流的编辑器.能同时处理多个文件多行的内容,可以不对原文件改动,把整个文件输入到屏幕,可以把只匹配到模式的内容输入到屏幕上 ...
- jQuery easyui datagrid数据绑定
1.绑定json数据 <!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type&qu ...
- 在easyui datagrid中formatter数据后使用linkbutton
http://ntzrj513.blog.163.com/blog/static/2794561220139245411997/ formatter:function(value,rowData,ro ...
- 取得某个数组前key大 PHP实现
<?php function max_key($arr, $key) { $tmp_key = $key; $max_arr = array(); while($tmp_key--) $max_ ...
- 二十四种设计模式:享元模式(Flyweight Pattern)
享元模式(Flyweight Pattern) 介绍运用共享技术有效地支持大量细粒度的对象. 示例有一个Message实体类,某些对象对它的操作有Insert()和Get()方法,现在要运用共享技术支 ...
- DbContextConfiguration 属性
属性 AutoDetectChangesEnabled 获取或设置一个值,该值指示是否通过 DbContext 和相关类的方法自动调用 DetectChanges 方法. 默认值为 true. Ens ...
- JAVA:借用OpenOffice将上传的Word文档转换成Html格式
为什么会想起来将上传的word文档转换成html格式呢?设想,如果一个系统需要发布在页面的文章都是来自word文档,一般会执行下面的流程:使用word打开文档,Ctrl+A,进入发布文章页面,Ctrl ...
- 淘宝PHPSDK2.0 剔除 lotusphp框架---兄弟连教程
淘宝PHPSDK2.0 剔除 lotusphp框架---兄弟连教程. lotusphp是一个国产开源的php框架 由于有个朋友公司是做淘宝客的,还由于不少朋友在开淘宝,于是有必要研究下.尽管个人认为微 ...