《最新出炉》系列初窥篇-Python+Playwright自动化测试-6-元素定位大法-下篇
1.简介
上一篇主要是讲解我们日常工作中在使用Playwright进行元素定位的一些比较常用的定位方法的理论基础知识以及在什么情况下推荐使用。今天这一篇讲解和分享一下,在日常中很少用到或者很少见的定位,但是遇到了我们也要会,俗话说:手里有粮心里不慌。
2.阴影定位-Shadow DOM
在做web自动化的时候,一些元素在shadow-root的节点下,使得playwright中无法通过xpath来定位

上面所看到的shadow-root标签其实就是一个shadowDOM,那么什么是shadowDOM呢?
他是前端的一种页面封装技术,可以将shadowDOM视为“DOM中的DOM”(可以看成一个隐藏的DOM)
他是一个独立的DOM树,具有自己的元素和样式,与原始文档DOM完全隔离。
shadowDOM必须附在一个HTML元素中,存放shadowDOM的元素,我们可以把它称为宿主元素。在HTML5中有很多的标签样式都是通过shadowDOM来实现的。
比如:日期选择框,音频播放标签,视频播放标签都自带了样式;(这种封装对于前端开发来说虽好,但是我们测试人员在做web自动给的时候就会遇到一些问题,shadowDOM中的标签无法定位。)
默认情况下,Playwright 中的所有定位器都使用 Shadow DOM 中的元素。例外情况是:
- 通过 XPath 定位不会刺穿阴影根部。
- 不支持闭合模式影子根。
例如:以下示例和自定义 Web 组件:
<x-details role=button aria-expanded=true aria-controls=inner-details>
<div>Title</div>
#shadow-root
<div id=inner-details>Details</div>
</x-details>
您可以采用与影子根根本不存在相同的方式进行定位。
要单击 :<div>Details</div>
page.get_by_text("Details").click()
要单击 :<x-details>
page.locator("x-details", has_text="Details" ).click()
要确保包含文本“详细信息”,请执行以下操作:<x-details>
expect(page.locator("x-details")).to_contain_text("Details")
3.过滤器定位-Filtering
例如以下 DOM 结构,我们要在其中单击第二个产品卡的购买按钮。我们有几个选项来过滤定位器以获得正确的定位器。

3.1文本过滤
定位器可以使用 locator.filter()方法按文本进行过滤。它将搜索元素内某处的特定字符串,可能在后代元素中,不区分大小写。您还可以传递正则表达式。
1.使用文本
page.get_by_role("listitem").filter(has_text="Product 2").get_by_role(
"button", name="Add to cart"
).click()
2.使用正则表达式
page.get_by_role("listitem").filter(has_text=re.compile("Product 2")).get_by_role(
"button", name="Add to cart"
).click()
3.通过没有文本进行筛选
# 5 in-stock items
expect(page.get_by_role("listitem").filter(has_not_text="Out of stock")).to_have_count(5)
3.2子项/后代过滤
定位器支持仅选择具有或没有与其他定位器匹配的后代的元素的选项。因此,您可以按任何其他定位器进行过滤,例如 locator.get_by_role()、locator.get_by_test_id()、locator.get_by_text() 等。
1.使用子项
page.get_by_role("listitem").filter(
has=page.get_by_role("heading", name="Product 2")
).get_by_role("button", name="Add to cart").click()
2.使用产品卡断言,确保只有一个
expect(
page.get_by_role("listitem").filter(
has=page.get_by_role("heading", name="Product 2")
)
).to_have_count(1)
3.通过内部没有匹配的元素进行过滤
expect(
page.get_by_role("listitem").filter(
has_not=page.get_by_role("heading", name="Product 2")
)
).to_have_count(1)
敲黑板!!!!注意:内部定位器从外部定位器开始匹配,而不是从文档根目录匹配。
3.3匹配其他定位进行过滤
方法 locator.and_() 通过匹配其他定位器来缩小现有定位器的范围。例如,您可以组合 page.get_by_role() 和 page.get_by_title() 以按角色和头衔进行匹配。
button = page.get_by_role("button").and_(page.getByTitle("Subscribe"))
4.链接定位器
您可以链接创建定位器的方法(如 page.get_by_text() 或 locator.get_by_role()),以将搜索范围缩小到页面的特定部分。
在此示例中,我们首先通过定位其角色:listitem 来创建一个名为 product 的定位器。然后我们按文本过滤。我们可以再次使用产品定位器按按钮的角色获取并单击它,然后使用断言来确保只有一个带有文本“产品 2”的产品。
product = page.get_by_role("listitem").filter(has_text="Product 2")
product.get_by_role("button", name="Add to cart").click()
您还可以将两个定位器链接在一起,例如在特定对话框中查找“保存”按钮:
save_button = page.get_by_role("button", name="Save")
# ...
dialog = page.get_by_test_id("settings-dialog")
dialog.locator(save_button).click()
5.列表
5.1对列表中的项目进行计数
可以断言定位器以对列表中的项目进行计数。例如:一下DOM结构

使用计数断言确保列表包含 3 个项目。
expect(page.get_by_role("listitem")).to_have_count(3)
5.2断言列表中所有文本
可以断言定位器以查找列表中的所有文本。使用 expect(定位器).to_have_text() 确保列表包含文本“苹果”、“香蕉”和“橙色”。
expect(page.get_by_role("listitem")).to_have_text(["apple", "banana", "orange"])
5.3定位特定项目
有许多方法可以在列表中定位特定项目。
5.3.1通过文本定位
使用 page.get_by_text() 方法通过文本内容在列表中查找元素,然后单击它。

通过文本内容找到项目并单击它。
page.get_by_text("orange").click()
5.3.2通过文本过滤定位
使用 locator.filter() 在列表中查找特定项目。按“列表项”的角色找到一个项目,然后按“橙色”的文本进行筛选,然后单击它。
page.get_by_role("listitem").filter(has_text="orange").click()
5.3.3通过测试id定位
使用 page.get_by_test_id() 方法在列表中查找元素。如果您还没有测试 ID,则可能需要修改 html 并添加测试 ID。

通过测试ID“橙色”找到项目,然后单击它。
page.get_by_test_id("orange").click()
5.3.4通过第n项定位
如果你有一个相同元素的列表,并且区分它们的唯一方法是顺序,你可以从带有 locator.first、locator.last 或 locator.nth() 的列表中选择一个特定的元素。
banana = page.get_by_role("listitem").nth(1)
但是,请谨慎使用此方法。通常,页面可能会更改,并且定位器将指向与预期完全不同的元素。相反,尝试提出一个通过严格标准的独特定位器。
5.4链接过滤器
当您有各种相似性的元素时,可以使用 locator.filter()方法选择正确的元素。您还可以链接多个筛选器以缩小选择范围。
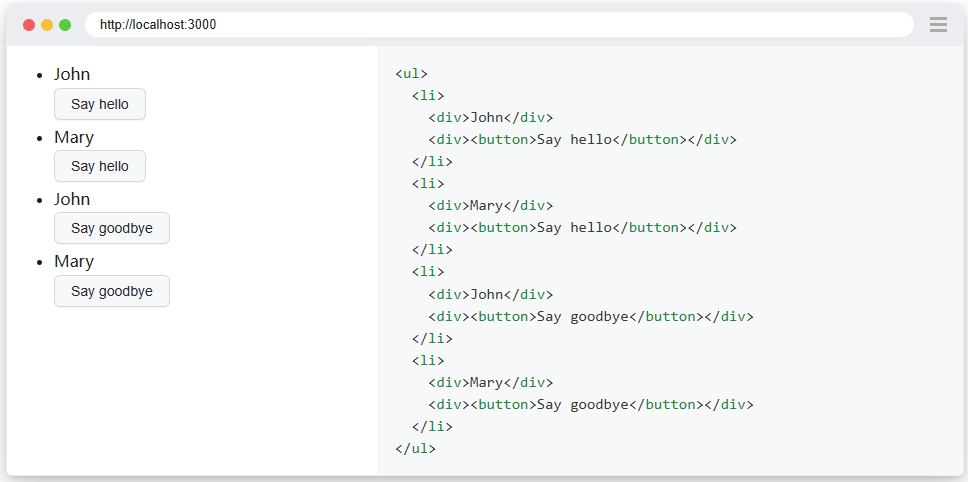
要截取带有“Mary”和“Say goodbye”的行的屏幕截图:
row_locator = page.get_by_role("listitem")
row_locator
.filter(has_text="Mary")
.filter(has=page.get_by_role("button", name="Say goodbye"))
.screenshot(path="screenshot.png")
5.5罕见例子
5.5.1对列表中每个元素执行操作
迭代元素
for row in page.get_by_role("listitem").all():
print(row.text_content())
使用常规 for 循环进行迭代:
rows = page.get_by_role("listitem")
count = rows.count()
for i in range(count):
print(rows.nth(i).text_content())
5.5.2在页面中评估
locator.evaluate_all()中的代码在页面中运行,您可以在那里调用任何 DOM API。
rows = page.get_by_role("listitem")
texts = rows.evaluate_all("list => list.map(element => element.textContent)")
6.小结
定位器是非常严格。这意味着,如果多个元素匹配,则对定位器执行暗示某些目标 DOM 元素的所有操作都将引发异常。例如,如果 DOM 中有多个按钮,则会引发以下调用:
如果有多个button,则引发错误
page.get_by_role("button").click()
另一方面,Playwright 了解何时执行多元素操作,因此当定位器解析为多个元素时,以下调用工作正常。
适用于多个元素
page.get_by_role("button").count()
您可以通过 locator.first、locator.last 和 locator.nth() 告诉 Playwright 在多个元素匹配时使用哪个元素来明确选择退出严格性检查。不建议使用这些方法,因为当您的页面更改时,Playwright 可能会单击您不想要的元素。相反,请按照上述最佳实践创建唯一标识目标元素的定位器。
6.1其他定位器
对于不太常用的定位器,请查看官网的其他定位器指南。由于时间关系,宏哥就不在这里对其进行展开介绍和讲解了。好了时间不早了,关于元素定位大法今天就分享到这里!!!仅供大家学习参考,感谢您耐心的阅读。
《最新出炉》系列初窥篇-Python+Playwright自动化测试-6-元素定位大法-下篇的更多相关文章
- 《手把手教你》系列技巧篇(十五)-java+ selenium自动化测试-元素定位大法之By xpath中卷(详细教程)
1.简介 按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍定位倒数二个方法:By xpath.xpath 的定位方法, 非常强大. 使用这种方法几乎可以定位到页面上的任意元素. ...
- 《手把手教你》系列技巧篇(八)-java+ selenium自动化测试-元素定位大法之By id(详细教程)
1.简介 从这篇文章开始,要介绍web自动化核心的内容,也是最困难的部分了,就是:定位元素,并去对定位到的元素进行一系列相关的操作.想要对元素进行操作,第一步,也是最重要的一步,就是要找到这个元素,如 ...
- 《手把手教你》系列技巧篇(十)-java+ selenium自动化测试-元素定位大法之By class name(详细教程)
1.简介 按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍By ClassName.看到ID,NAME这些方法的讲解,小伙伴们和童鞋们应该知道,要做好Web自动化测试,最好是需要了 ...
- 《手把手教你》系列技巧篇(十四)-java+ selenium自动化测试-元素定位大法之By xpath上卷(详细教程)
1.简介 按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍定位倒数二个方法:By xpath.xpath 的定位方法, 非常强大. 使用这种方法几乎可以定位到页面上的任意元素. ...
- 《手把手教你》系列技巧篇(十六)-java+ selenium自动化测试-元素定位大法之By xpath下卷(详细教程)
1.简介 按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍定位倒数二个方法:By xpath.xpath 的定位方法, 非常强大. 使用这种方法几乎可以定位到页面上的任意元素. ...
- 《手把手教你》系列技巧篇(十七)-java+ selenium自动化测试-元素定位大法之By css上卷(详细教程)
1.简介 CSS定位方式和xpath定位方式基本相同,只是CSS定位表达式有其自己的格式.CSS定位方式拥有比xpath定位速度快,且比CSS稳定的特性.下面详细介绍CSS定位方式的使用方法.xpat ...
- 《手把手教你》系列技巧篇(十八)-java+ selenium自动化测试-元素定位大法之By css中卷(详细教程)
1.简介 按计划今天宏哥继续讲解倚天剑-css的定位元素的方法:ID属性值定位.其他属性值定位和使用属性值的一部分定位(这个类似xpath的模糊定位). 2.常用定位方法(8种) (1)id(2)na ...
- 《手把手教你》系列技巧篇(十九)-java+ selenium自动化测试-元素定位大法之By css下卷(详细教程)
1.简介 按计划今天宏哥继续讲解css的定位元素的方法.但是今天最后一种宏哥介绍给大家,了解就可以了,因为实际中很少用. 2.常用定位方法(8种) (1)id(2)name(3)class name( ...
- 《手把手教你》系列技巧篇(十一)-java+ selenium自动化测试-元素定位大法之By tag name(详细教程)
1.简介 按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍By ClassName.看到ID,NAME这些方法的讲解,小伙伴们和童鞋们应该知道,要做好Web自动化测试,最好是需要了 ...
- [python爬虫] Selenium常见元素定位方法和操作的学习介绍(转载)
转载地址:[python爬虫] Selenium常见元素定位方法和操作的学习介绍 一. 定位元素方法 官网地址:http://selenium-python.readthedocs.org/locat ...
随机推荐
- django模糊查询排序
class Book(models.Model): """ 列名 """ class Meta: db_table = 'book' nam ...
- Arrays.asList() 示例
1 package Test.others; 2 3 import java.util.Arrays; 4 import java.util.Collections; 5 import java.ut ...
- springboot升级过程中踩坑定位分析记录 | 京东云技术团队
作者:京东零售 李文龙 1.背景 " 俗话说:为了修复一个小bug而引入了一个更大bug " 因所负责的系统使用的spring框架版本5.1.5.RELEASE在线上出过一个偶发的 ...
- 张量(Tensor)、标量(scalar)、向量(vector)、矩阵(matrix)
张量(Tensor):Tensor = multi-dimensional array of numbers 张量是一个多维数组,它是标量,向量,矩阵的高维扩展 ,是一个数据容器,张量是矩阵向任意维度 ...
- 推荐一个.Net Core开发的Websocket群聊、私聊的开源项目
今天给大家推荐一个使用Websocket协议实现的.高性能即时聊天组件,可用于群聊.好友聊天.游戏直播等场景. 项目简介 这是一个基于.Net Core开发的.简单.高性能的通讯组件,支持点对点发送. ...
- 2022-11-14:rust语言,请使用过程宏给结构体AAA生成结构体AAABuilder和创建AAABuilder实例的方法。 宏使用如下: #[derive(Builder)] pub stru
2022-11-14:rust语言,请使用过程宏给结构体AAA生成结构体AAABuilder和创建AAABuilder实例的方法. 宏使用如下: #[derive(Builder)] pub stru ...
- 2022-05-06:给你一个整数数组 arr,请你将该数组分隔为长度最多为 k 的一些(连续)子数组。分隔完成后,每个子数组的中的所有值都会变为该子数组中的最大值。 返回将数组分隔变换后能够得到的元
2022-05-06:给你一个整数数组 arr,请你将该数组分隔为长度最多为 k 的一些(连续)子数组.分隔完成后,每个子数组的中的所有值都会变为该子数组中的最大值. 返回将数组分隔变换后能够得到的元 ...
- pycharm eslint should be on a new line
修改前: "vue/max-attributes-per-line": [2, { "singleline": 10, "multiline" ...
- 【GiraKoo】Java Native Interface(JNI)的空间(引用)管理
Java Native Interface(JNI)的空间(引用)管理 Java是通过垃圾回收机制回收内存,C/C++是通过malloc,free,new,delete手动管理空间.那么在JNI层,同 ...
- 机器学习数据顺序随机打乱:Python实现
本文介绍基于Python语言,实现机器学习.深度学习等模型训练时,数据集打乱的具体操作. 1 为什么要打乱数据集 在机器学习中,如果不进行数据集的打乱,则可能导致模型在训练过程中出现具有&qu ...