pandas(进阶操作)-- 处理非数值型数据 -- 数据分析三剑客(核心)
开发环境
- anaconda
- 集成环境:集成好了数据分析和机器学习中所需要的全部环境
- 安装目录不可以有中文和特殊符号
- jupyter
- anaconda提供的一个基于浏览器的可视化开发工具
import numpy as np
import pandas as pd
from pandas import DataFrame
替换操作
- 替换操作可以同步作用于Series和DataFrame中
- 单值替换
- 普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
- 按列指定单值替换: to_replace={列标签:替换值} value='value'
- 多值替换
- 列表替换: to_replace=[] value=[]
- 字典替换(推荐) to_replace=
df = DataFrame(data=np.random.randint(0,100,size=(5,6)))
df
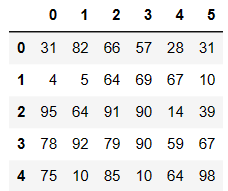
df.replace(to_replace=2,value='Two')
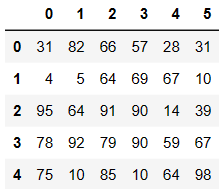
df.replace(to_replace={1:'one'})
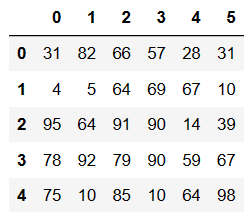
# 将指定列的元素进行替换to_replase={列索引:被替换的值}
df.replace(to_replace={4:5},value='five')
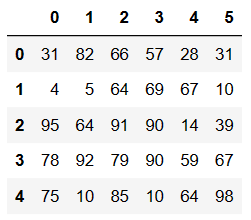
映射操作
- 概念:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定(给一个元素值提供不同的表现形式)
- 创建一个df,两列分别是姓名和薪资,然后给其名字起对应的英文名
dic = {
'name':['张三','李四','张三'],
'salary':[15000,20000,15000]
}
df = DataFrame(data=dic)
df
# 映射关系表
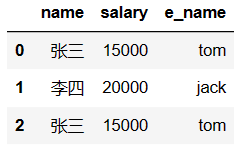
# map是Series的方法,只能被Series调用
dic = {
'张三':'tom',
'李四':'jack'
}
df['e_name'] = df['name'].map(dic)
df
运算工具
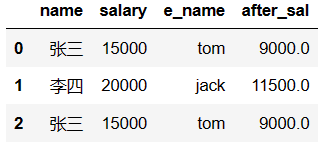
- 超过3000部分的钱缴纳50%的税,计算每个人的税后薪资
# 该函数是我们指定的一个运算法则
def after_sal(s):#计算s对应的税后薪资
return s - (s-3000)*0.5
df['after_sal'] = df['salary'].map(after_sal)#可以将df['salary']这个Series中每一个元素(薪资)作为参数传递给s
df
排序实现的随机抽样
- take()
- np.random.permutation()
df = DataFrame(data=np.random.randint(0,100,size=(100,3)),columns=['A','B','C'])
df

# 生成乱序的随机序列
np.random.permutation(10)
array([8, 9, 6, 2, 5, 3, 1, 0, 7, 4])
# 将原始数据打乱
df.take([2,0,1],axis=1)
df.take(np.random.permutation(3),axis=1)

df.take(np.random.permutation(3),axis=1).take(np.random.permutation(100),axis=0)[0:50]
df.take(np.random.permutation(3),axis=1).take(np.random.permutation(100),axis=0)[0:50].head()
数据的分类处理
- 数据分类处理的核心:
- groupby()函数
- groups属性查看分组情况
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})
df
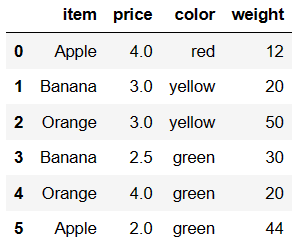
想要对水果的种类进行分析
df.groupby(by='item')
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x00000290D4BAA910>
查看详细的分组情况
df.groupby(by='item').groups
{'Apple': [0, 5], 'Banana': [1, 3], 'Orange': [2, 4]}
分组聚合
计算出每一种水果的平均价格
df.groupby(by='item')['price'].mean()
item
Apple 3.00
Banana 2.75
Orange 3.50
Name: price, dtype: float64
计算每一种颜色对应水果的平均重量
df.groupby(by='color')['weight'].mean()
color
green 31.333333
red 12.000000
yellow 35.000000
Name: weight, dtype: float64
dic = df.groupby(by='color')['weight'].mean().to_dict()
dic
{'green': 31.333333333333332, 'red': 12.0, 'yellow': 35.0}
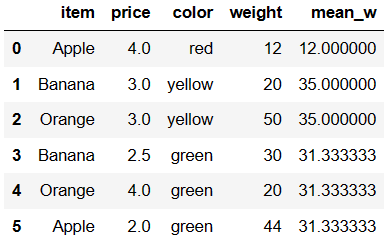
将计算出的平均重量汇总到源数据
df['mean_w'] = df['color'].map(dic)
df
高级数据聚合
- 使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
- df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)
- transform和apply都会进行运算,在transform或者apply中传入函数即可
- transform和apply也可以传入一个lambda表达式
def my_mean(s):
m_sum = 0
for i in s:
m_sum += i
return m_sum / len(s)
df.groupby(by='item')['price'].transform(my_mean)
0 3.00
1 2.75
2 3.50
3 2.75
4 3.50
5 3.00
Name: price, dtype: float64
df.groupby(by='item')['price'].apply(my_mean)
item
Apple 3.00
Banana 2.75
Orange 3.50
Name: price, dtype: float64
数据加载
- 读取type-.txt文件数据
df = pd.read_csv('./data/type-.txt')
df

df.shape
(2, 1)
将文件中每一个词作为元素存放在DataFrame中
pd.read_csv('./data/type-.txt',header=None,sep='-')
读取数据库中的数据
连接数据库,获取连接对象
import sqlite3 as sqlite3
conn = sqlite3.connect('./data/weather_2012.sqlite')
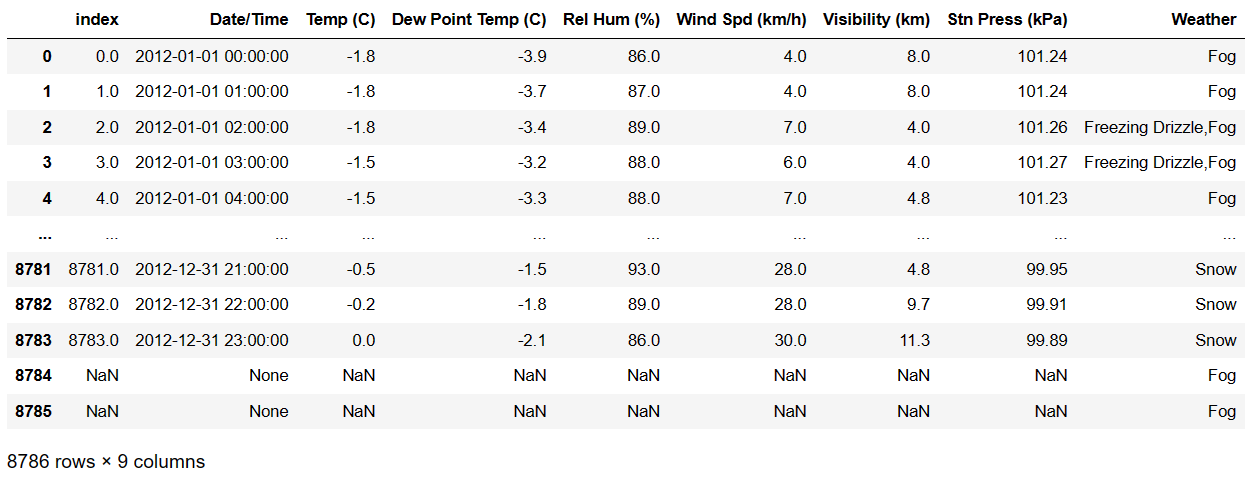
读取库表中的数据值
sql_df=pd.read_sql('select * from weather_2012',conn)
sql_df
将一个df中的数据值写入存储到db
df.to_sql('sql_data456',conn)
2
透视表
- 透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
- 透视表的优点:
- 灵活性高,可以随意定制你的分析计算要求
- 脉络清晰易于理解数据
- 操作性强,报表神器
import pandas as pd
import numpy as np
df = pd.read_csv('./data/透视表-篮球赛.csv',encoding='utf8')
df
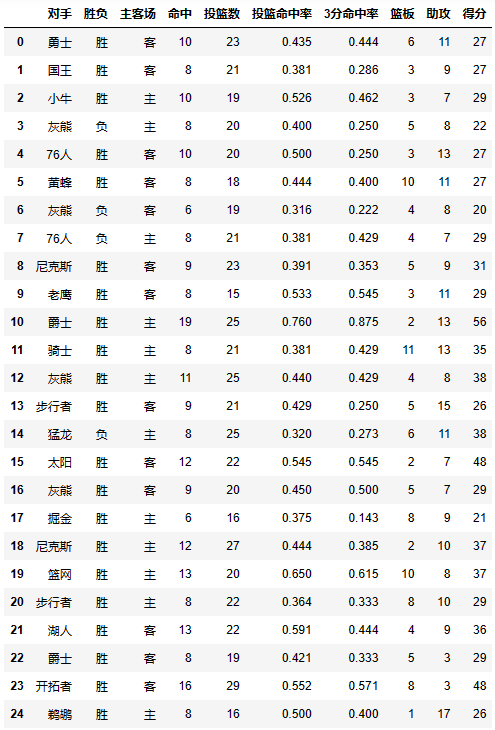
pivot_table有四个最重要的参数index、values、columns、aggfunc
index参数:分类汇总的分类条件
- 每个pivot_table必须拥有一个index。如果想查看哈登对阵每个队伍的得分则需要对每一个队进行分类并计算其各类得分的平均值:
- 想看看哈登对阵同一对手在不同主客场下的数据,分类条件为对手和主客场
df.pivot_table(index=['对手','主客场'])
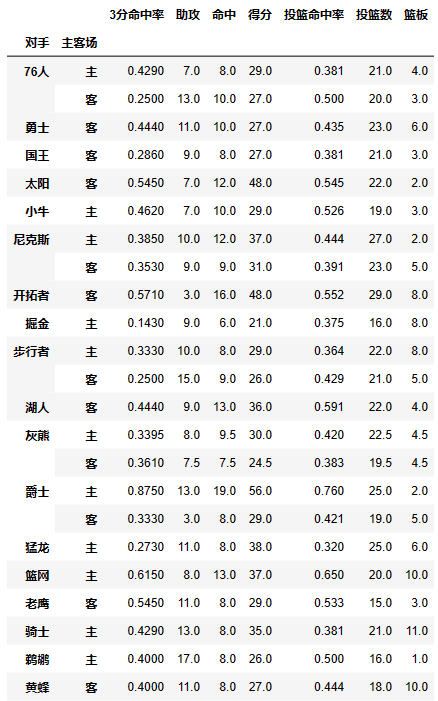
values参数:需要对计算的数据进行筛选
- 如果我们只需要哈登在主客场和不同胜负情况下的得分、篮板与助攻三项数据
df.pivot_table(index=['主客场','胜负'],values=['得分','篮板','助攻'])
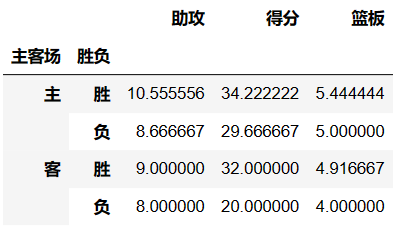
Aggfunc参数:设置我们对数据聚合时进行的函数操作
- 当我们未设置aggfunc时,它默认aggfunc='mean'计算均值。
- 还想获得james harden在主客场和不同胜负情况下的总得分、总篮板、总助攻时
df.pivot_table(index=['主客场','胜负'],values=['得分','篮板','助攻'],aggfunc='sum')
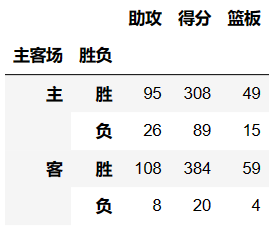
Columns:可以设置列层次字段
- 对values字段进行分类
# 获取所有队主客场的总得分
df.pivot_table(index='主客场',values='得分',aggfunc='sum')

# 获取每个队主客场的总得分(在总得分的基础上又进行了对手的分类)
df.pivot_table(index='主客场',values='得分',columns='对手',aggfunc='sum',fill_value=0)

交叉表
- 是一种用于计算分组的特殊透视图,对数据进行汇总
- pd.crosstab(index,colums)
- index:分组数据,交叉表的行索引
- columns:交叉表的列索引
import pandas as pd
from pandas import DataFrame
df = DataFrame({'sex':['man','man','women','women','man','women','man','women','women'],
'age':[15,23,25,17,35,57,24,31,22],
'smoke':[True,False,False,True,True,False,False,True,False],
'height':[168,179,181,166,173,178,188,190,160]})
df
求出各个性别抽烟的人数
pd.crosstab(df.smoke,df.sex)

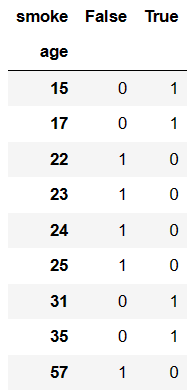
求出各个年龄段抽烟人情况
pd.crosstab(df.age,df.smoke)
pandas(进阶操作)-- 处理非数值型数据 -- 数据分析三剑客(核心)的更多相关文章
- pandas 基础操作 更新
创建一个Series,同时让pandas自动生成索引列 创建一个DataFrame数据框 查看数据 数据的简单统计 数据的排序 选择数据(类似于数据库中sql语句) 另外可以使用标签来选择 通过位置获 ...
- Django之Models进阶操作(字段属性)
字段属性详细介绍 一.字段 AutoField(Field) - int自增列,必须填入参数 primary_key=True BigAutoField(AutoField) - bigint自增列, ...
- [原创]Scala学习:数组的基本操作,数组进阶操作,多维数组
1.Scala中提供了一种数据结构-数组,其中存储相同类型的元素的固定大小的连续集合.数组用于存储数据的集合,但它往往是更加有用认为数组作为相同类型的变量的集合 2 声明数组变量: 要使用的程序的数组 ...
- Django 之models进阶操作
到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞: 创建数据库,设计表结构和字段 使用 MySQLdb 来连接数据库,并编写数据访问层代码 业务逻辑层去调用数据访问层执行数据库操作 ...
- python数据分析三剑客之: pandas操作
pandas的操作 pandas的拼接操作 # pandas的拼接操作 级联 pd.concat , pd.append 合并 pd.merge , pd.join 一丶pd.concat()级联 # ...
- web框架-(七)Django补充---models进阶操作及modelform操作
通过之前的课程我们可以对于Django的models进行简单的操作,今天了解下进阶操作和modelform: 1. Models进阶操作 1.1 字段操作 AutoField(Field) - int ...
- js非数值的比较
/** * 非数值的比较: * 1.对于非数值的比较时,会将其转换成数字然后再比较 * 2.如果符号两端是字符串的值进行比较时,不会将其转换为数字进行比较,而是 * 分别比较字符串中的字符的 unic ...
- 用Python的pandas框架操作Excel文件中的数据教程
用Python的pandas框架操作Excel文件中的数据教程 本文的目的,是向您展示如何使用pandas 来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其 ...
- 数据分析06 /pandas高级操作相关案例:人口案例分析、2012美国大选献金项目数据分析
数据分析06 /pandas高级操作相关案例:人口案例分析.2012美国大选献金项目数据分析 目录 数据分析06 /pandas高级操作相关案例:人口案例分析.2012美国大选献金项目数据分析 1. ...
- pandas神器操作excel表格大全(数据分析数据预处理)
使用pandas库操作excel,csv表格操作大全 关注公众号"轻松学编程"了解更多,文末有公众号二维码,可以扫码关注哦. 前言 准备三份csv表格做演示: 成绩表.csv su ...
随机推荐
- 【了解LLM】——LoRA
本文地址:https://www.cnblogs.com/wanger-sjtu/p/17470327.html 论文链接:link code: github 什么是LoRA LoRA,英文全称Low ...
- IcedID恶意文档钓鱼手法剖析
析 利用oletools静态分析,提取宏代码,如图: Function contents() With ActiveDocument.Content.Find loveDoor = .Execute( ...
- Python Flask - 快速构建Web应用详解
本文将详细探讨Python Flask Web服务.我将首先简单介绍Flask,然后将逐步进入Flask中的路由.模板.表单处理以及数据库集成等高级概念,目标是能够让大家了解并掌握使用Flask来创建 ...
- 一个跨平台的`ChatGPT`悬浮窗工具
一个跨平台的ChatGPT悬浮窗工具 使用avalonia实现的ChatGPT的工具,设计成悬浮窗,并且支持插件. 如何实现悬浮窗? 在使用avalonia实现悬浮窗也是非常的简单的. 实现我们需要将 ...
- WakaTime Readme Stats-开源项目翻译
寻找不同语言和地区的翻译 #23 Readme中添加了功能标志的开发指标 眼前一亮的Readme统计数据 你是早起的还是夜间的? 你一天中什么时候工作效率最高? 你用什么语言编写代码? 让我们在你的个 ...
- 【活动回顾】WebRTC服务端工程实践和优化探索
11月7日,即构和上海GDG技术社区联合举办了实时音视频技术云上技术分享专场,来自即构科技和Bilibili的资深技术专家进行了深度分享.大会吸引了众多开发人员交流.观看,并在活动过程中与分享嘉宾进行 ...
- 利用Aspose.Word对Word文件添加印章处理以及实现业务数据的替换处理
有时候,我们在处理大量文档的时候,需要批量给Word文档添加印章处理,方便打印操作,本篇随笔介绍利用Aspose.Word对Word文件添加印章处理以及实现业务数据的替换处理. 1.利用Aspose. ...
- MyBatis(log4j)
log4j介绍 Log4j是Apache的一个开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台.文件.GUI组件,甚至是套接口服务器.NT的事件记录器.UNIX Syslog守护 ...
- 正交实例二(不规则数据的测试:也就是因子数和水平数不是正好满足正交表)allpairs的使用即下载
allpairs工具的使用 作用可以针对不规则的数据生成用例 下载地址: 链接:https://pan.baidu.com/s/1SgvciN427z_WRzA5QG5eJg ** 提取码:52yj* ...
- Llama 2 来袭 - 在 Hugging Face 上玩转它
引言 今天,Meta 发布了 Llama 2,其包含了一系列最先进的开放大语言模型,我们很高兴能够将其全面集成入 Hugging Face,并全力支持其发布. Llama 2 的社区许可证相当宽松,且 ...