数据分析06 /pandas高级操作相关案例:人口案例分析、2012美国大选献金项目数据分析
数据分析06 /pandas高级操作相关案例:人口案例分析、2012美国大选献金项目数据分析
1. 人口分析案例
需求:
- 导入文件,查看原始数据
- 将人口数据和各州简称数据进行合并
- 将合并的数据中重复的abbreviation列进行删除
- 查看存在缺失数据的列
- 找到有哪些state/region使得state的值为NaN,进行去重操作
- 为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN
- 合并各州面积数据areas
- 我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行
- 去除含有缺失数据的行
- 找出2010年的全民人口数据
- 计算各州的人口密度
- 排序,并找出人口密度最高的五个州
代码实现:
1.导入文件,查看原始数据
import pandas as pd # 各州的全称和简称
abb = pd.read_csv('./data/state-abbrevs.csv')
abb.head()
# 各州人口数据
pop = pd.read_csv('./data/state-population.csv')
pop.head()
# 各州面积数据
area = pd.read_csv('./data/state-areas.csv')
area.head()
2.将人口数据和各州简称数据进行合并
abb_pop = pd.merge(abb,pop,left_on='abbreviation',right_on='state/region',how='outer') # how指定称outer,可以保证数据的完整性
abb_pop.head()
3.将合并的数据中重复的abbreviation列进行删除
abb_pop.drop(labels='abbreviation',axis=1,inplace=True)
abb_pop.head()
4.查看存在缺失数据的列
# 方式一:
abb_pop.info()

# 方式二:
abb_pop.isnull().any(axis=0)

5.找到有哪些state/region使得state的值为NaN,进行去重操作
# 找出全称(state)的空值
abb_pop['state'].isnull() # 找出空值对应的行数据(行数据中就有符合条件的简称)
abb_pop.loc[abb_pop['state'].isnull()] # 在空所对应的行数据中取出简称(找到了空对应的简称)
abb_pop.loc[abb_pop['state'].isnull()]['state/region'] # 去重
abb_pop.loc[abb_pop['state'].isnull()]['state/region'].unique() # nunique()统计去重之后结果的个数,n-> num
abb_pop.loc[abb_pop['state'].isnull()]['state/region'].nunique()
6.为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN
思路:将state列中的空值都取出来,然后将其分成两组(PR对应的空值,USA对应的空)
# 根据PR去state中定位空值
abb_pop['state/region'] == 'PR'
# 将PR对应的行数据取出,从行数据中定位空值,定位到的空值就是PR对应的空,空值赋值PR的全程
abb_pop.loc[abb_pop['state/region'] == 'PR'] # 将PR对应的state的空值的行索引获取
indexs = abb_pop.loc[abb_pop['state/region'] == 'PR'].index
indexs # 将indexs对应行中的state列的数据批量赋值成PR的全称
abb_pop.loc[indexs,'state'] = 'Puerto Rico'
# 将USA对应的全称的空值覆盖称United Status
abb_pop['state/region'] == 'USA'
abb_pop.loc[abb_pop['state/region'] == 'USA']
indexs = abb_pop.loc[abb_pop['state/region'] == 'USA'].index
abb_pop.loc[indexs,'state'] = 'United Status'
7.合并各州面积数据areas
abb_pop_area = pd.merge(abb_pop,area,on='state',how='outer')
abb_pop_area.head()
8.我们会发现area(sq.mi)这一列有缺失数据,找出是哪些行
abb_pop_area['area (sq. mi)'].isnull() # 判断area(sq. mi)列中存在的空值有哪些true
abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()] # 将area(sq. mi)的空值对应的行数据取出
9.去除含有缺失数据的行
drop_index = abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()].index # 获取行索引
abb_pop_area.drop(labels=drop_index,axis=0,inplace=True) # 根据行索引进行行数据的删除
10.找出2010年的全民人口数据,基于df进行条件查询
abb_pop_area.query('ages == "total" & year == 2010')
11.计算各州的人口密度
abb_pop_area['midu'] = abb_pop_area['population'] / abb_pop_area['area (sq. mi)']
abb_pop_area.head()
12.排序,并找出人口密度最高的五个州,sort_values根据值排序
abb_pop_area.sort_values(by='midu',ascending=False) # ascending表示是升序还是降序
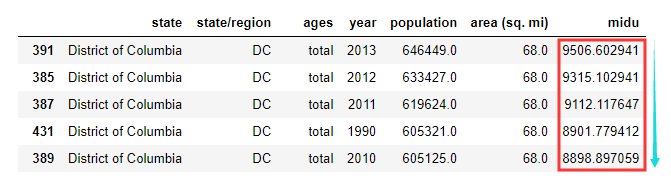
人口分析案例总结:
读取文件:pd.read_csv('文件路径')
查看每一列的详细信息:data.info()
df的条件查询:data.query('ages == "total" & year == 2010')
对某一列数据进行排序:data.sort_values(by='midu',ascending=False)
2. 2012美国大选献金项目数据分析
需求:
加载数据,查看数据的基本信息
指定数据截取,将如下字段的数据进行提取,其他数据舍弃
cand_nm :候选人姓名
contbr_nm : 捐赠人姓名
contbr_st :捐赠人所在州
contbr_employer : 捐赠人所在公司
contbr_occupation : 捐赠人职业
contb_receipt_amt :捐赠数额(美元)
contb_receipt_dt : 捐款的日期
对新数据进行总览df.info(),查看是否存在缺失数据
用统计学指标快速描述数值型属性的概要。df.describe()
空值处理。可能因为忘记填写或者保密等等原因,相关字段出现了空值,将其填充为NOT PROVIDE
异常值处理。将捐款金额<=0的数据删除
新建一列为各个候选人所在党派party
查看party这一列中有哪些不同的元素
统计party列中各个元素出现次数
查看各个党派收到的政治献金总数contb_receipt_amt
查看具体每天各个党派收到的政治献金总数contb_receipt_amt
将表中日期格式转换为'yyyy-mm-dd'
查看老兵(捐献者职业)DISABLED VETERAN主要支持谁
找出各个候选人的捐赠者中,捐赠金额最大的人的职业以及捐献额
代码实现:
1.加载数据,查看数据的基本信息
df = pd.read_csv('./data/usa_election.txt')
df.head()
2.指定数据截取,将如下字段的数据进行提取,其他数据舍弃
df = df[['cand_nm','contbr_nm','contbr_st','contbr_employer','contbr_occupation','contb_receipt_amt','contb_receipt_dt']]

3.对新数据进行总览df.info(),查看是否存在缺失数据
df.info() 数据总览如下:
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 536041 entries, 0 to 536040
Data columns (total 7 columns):
cand_nm 536041 non-null object
contbr_nm 536041 non-null object
contbr_st 536040 non-null object
contbr_employer 525088 non-null object
contbr_occupation 530520 non-null object
contb_receipt_amt 536041 non-null float64
contb_receipt_dt 536041 non-null object
dtypes: float64(1), object(6)
memory usage: 28.6+ MB
"""
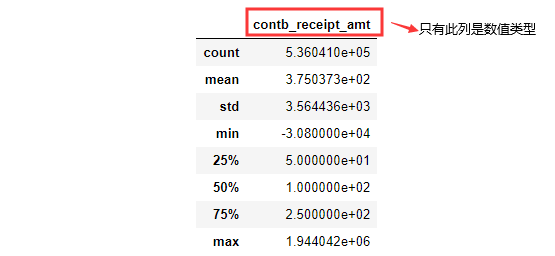
5.用统计学指标快速描述数值型属性的概要。df.describe()
df.describe()
5.空值处理。可能因为忘记填写或者保密等等原因,相关字段出现了空值,将其填充为NOT PROVIDE
# 使用NOT PROVIDE对空值进行填充
df.fillna(value='NOT PROVIDE',inplace=True) # 重新查看列是否有空值
df.info() 数据总览如下:
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 536041 entries, 0 to 536040
Data columns (total 7 columns):
cand_nm 536041 non-null object
contbr_nm 536041 non-null object
contbr_st 536041 non-null object
contbr_employer 536041 non-null object
contbr_occupation 536041 non-null object
contb_receipt_amt 536041 non-null float64
contb_receipt_dt 536041 non-null object
dtypes: float64(1), object(6)
memory usage: 28.6+ MB
"""
6.异常值处理。将捐款金额<=0的数据删除
df = df.loc[~(df['contb_receipt_amt'] <= 0)]
7.新建一列为各个候选人所在党派party
# 不同候选人党派对应表
parties = {
'Bachmann, Michelle': 'Republican',
'Romney, Mitt': 'Republican',
'Obama, Barack': 'Democrat',
"Roemer, Charles E. 'Buddy' III": 'Reform',
'Pawlenty, Timothy': 'Republican',
'Johnson, Gary Earl': 'Libertarian',
'Paul, Ron': 'Republican',
'Santorum, Rick': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'McCotter, Thaddeus G': 'Republican',
'Huntsman, Jon': 'Republican',
'Perry, Rick': 'Republican'
}
# 先查看共有多少个不同的候选人
df['cand_nm'].unique() # 查看候选人的个数
df['cand_nm'].nunique() # 利用映射为每个候选人添加党派信息
df['party'] = df['cand_nm'].map(parties)
df.head()
8.查看party这一列中有哪些不同的元素
df['party'].unique()
9.统计party列中各个元素出现次数
df['party'].value_counts() # value_counts()统计Series中不同元素出现的次数
10.查看各个党派收到的政治献金总数contb_receipt_amt
# 应用分组
df.groupby(by='party')['contb_receipt_amt'].sum()
11.查看具体每天各个党派收到的政治献金总数contb_receipt_amt
df.groupby(by=['contb_receipt_dt','party'])['contb_receipt_amt'].sum()
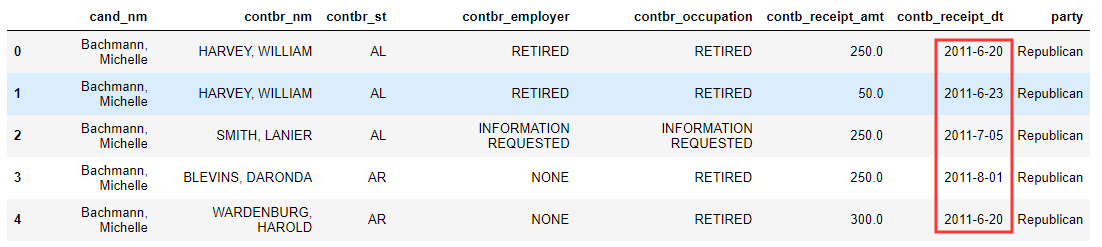
12.将表中日期格式转换为'yyyy-mm-dd'
# 应用运算工具
def transform_date(d):
day,month,year = d.split('-')
month = months[month]
return '20'+year+'-'+str(month)+'-'+day df['contb_receipt_dt'] = df['contb_receipt_dt'].map(transform_date)
df.head()
13.查看老兵(捐献者职业)DISABLED VETERAN主要支持谁
# 1.取出老兵这个职业对应的行数据
old_bing_df = df.loc[df['contbr_occupation'] == 'DISABLED VETERAN'] # 2.根据竞选者分组
old_bing_df.groupby(by='cand_nm')['contb_receipt_amt'].sum()
14.找出各个候选人的捐赠者中,捐赠金额最大的人的职业以及捐献额
df.groupby(by='cand_nm')['contb_receipt_amt'].max() # 此方法有不能满足要求,待更新
2012美国大选献金项目数据分析案例总结:
- 用统计学指标快速描述数值型属性的概要:df.describe()
- 统计Series中不同元素出现的次数:Series_obj.value_counts()
数据分析06 /pandas高级操作相关案例:人口案例分析、2012美国大选献金项目数据分析的更多相关文章
- pandas高级操作
pandas高级操作 import numpy as np import pandas as pd from pandas import DataFrame,Series 替换操作 替换操作可以同步作 ...
- pandas高级操作总结
1.pandas中的列的分位数 # 查看列的分位数 import pandas as pd # set columns type my_df['col'] = my_df['col'].astype( ...
- 数据分析05 /pandas的高级操作
数据分析05 /pandas的高级操作 目录 数据分析05 /pandas的高级操作 1. 替换操作 2. 映射操作 3. 运算工具 4. 映射索引 / 更改之前索引 5. 排序实现的随机抽样/打乱表 ...
- 数据分析之Pandas操作
Pandas pandas需要导入 import pandas as pd from pandas import Series,DataFrame import numpy as np 1 Serie ...
- pandas神器操作excel表格大全(数据分析数据预处理)
使用pandas库操作excel,csv表格操作大全 关注公众号"轻松学编程"了解更多,文末有公众号二维码,可以扫码关注哦. 前言 准备三份csv表格做演示: 成绩表.csv su ...
- 数据分析之Pandas
一.Pandas介绍 1.介绍 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具. ...
- 【Python自动化Excel】Python与pandas字符串操作
Python之所以能够成为流行的数据分析语言,有一部分原因在于其简洁易用的字符串处理能力. Python的字符串对象封装了很多开箱即用的内置方法,处理单个字符串时十分方便:对于Excel.csv等表格 ...
- Python数据分析库pandas基本操作
Python数据分析库pandas基本操作2017年02月20日 17:09:06 birdlove1987 阅读数:22631 标签: python 数据分析 pandas 更多 个人分类: Pyt ...
- DataGridView控件使用大全说明-各种常用操作与高级操作
DataGridView控件 DataGridView是用于Windows Froms 2.0的新网格控件.它可以取代先前版本中DataGrid控件,它易于使用并高度可定制,支持很多我们的用户需要的特 ...
随机推荐
- DML_Data Modification_DELETE
DML_Data Modification_Delete删除记录比较简单,但是需要特别注意,一不小心,就变成了 “从删库到跑路“ 就掉的大了 /* Microsoft SQL Server 2008 ...
- TensorFlow从0到1之TensorFlow实现简单线性回归(15)
本节将针对波士顿房价数据集的房间数量(RM)采用简单线性回归,目标是预测在最后一列(MEDV)给出的房价. 波士顿房价数据集可从http://lib.stat.cmu.edu/datasets/bos ...
- 研华advantech-凌华ADLINK板卡运动控制卡
研华advantech:6路独立D/A输出12位分辨率双缓冲D/A转换器多种电压范围:+/-10V,+/-5V,0—+5V,0—+10V和4—20mA电流环(汇)16路数字量输入及16路数字量输出 P ...
- MFC_VC++_时间获取与保存列表控件内容到文件操作方法
MFC_VC++_时间获取与保存列表控件内容到excel文件操作方法 void CDataView::OnBnClickedBtnExporttoexcel() { CTime time = CTim ...
- Eplan PLC连接点-两两相连接方法
Eplan PLC连接点-两两相连接方法. 1.插入->符号连接->T节点(向右). 2.如图 3.如图 然后再.插入->符号连接->T节点(向左). 重复2,3.即可完成两两 ...
- 【hdoj】哈希表题hdoj1425
hdoj1425 github链接 #include<cstdio> #include<cstring> using namespace std; const int offs ...
- Netty源码分析之自定义编解码器
在日常的网络开发当中,协议解析都是必须的工作内容,Netty中虽然内置了基于长度.分隔符的编解码器,但在大部分场景中我们使用的都是自定义协议,所以Netty提供了 MessageToByteEnco ...
- @PathVariable @RequestParam@RequestBody
@PathVariable 当使用@RequestMapping URI template 样式映射时, 即 someUrl/{paramId}, 这时的paramId可通过 @Pathvariabl ...
- Jenkins入门教程之linux下安装配置jenkins(一)
https://blog.csdn.net/zjh_746140129/article/details/80835866
- Spring 面试详解
SpringSpring就像是整个项目中装配bean的大工厂,在配置文件中可以指定使用特定的参数去调用实体类的构造方法来实例化对象.Spring的核心思想是IoC(控制反转),即不再需要程序员去显式地 ...