.NET使用分布式网络爬虫框架DotnetSpider快速开发爬虫功能
前言
前段时间有同学在微信群里提问,要使用.NET开发一个简单的爬虫功能但是没有做过无从下手。今天给大家推荐一个轻量、灵活、高性能、跨平台的分布式网络爬虫框架(可以帮助 .NET 工程师快速的完成爬虫的开发):DotnetSpider。
注意:为了自身安全请在国家法律允许范围内开发网络爬虫功能。
框架设计图
整个爬虫设计是纯异步的,利用消息队列进行各个组件的解耦,若是只需要单机爬虫则不需要做任何额外的配置,默认使用了一个内存型的消息队列;若是想要实现一个纯分布式爬虫,则需要引入一个消息队列即可,后面会详细介绍如何实现一个分布式爬虫。
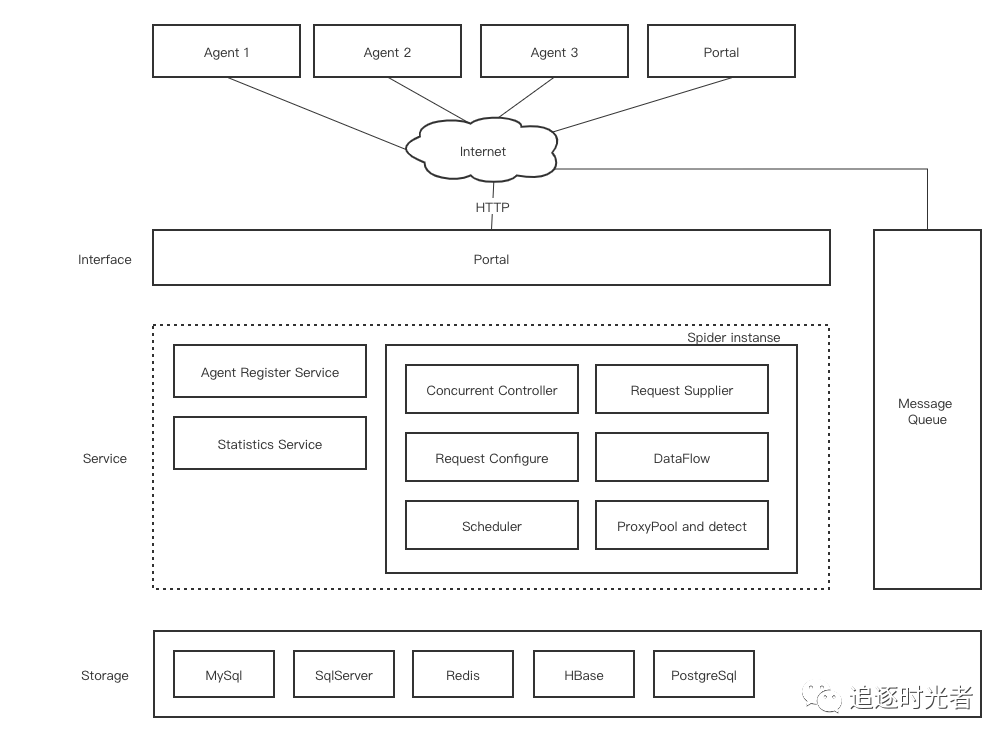
框架源码

开发爬虫需求
爬取博客园10天推荐排行第一页的文章标题、文章简介和文章地址,并将其保存到对应的txt文本中。

快速开始
创建SpiderSample控制台

安装DotnetSpider Nuget包
搜索:DotnetSpider
添加Serilog日志组件
搜索:Serilog.AspNetCore
RecommendedRankingModel
public class RecommendedRankingModel
{
/// <summary>
/// 文章标题
/// </summary>
public string ArticleTitle { get; set; }
/// <summary>
/// 文章简介
/// </summary>
public string ArticleSummary { get; set; }
/// <summary>
/// 文章地址
/// </summary>
public string ArticleUrl { get; set; }
}
RecommendedRankingSpider
public class RecommendedRankingSpider : Spider
{
public RecommendedRankingSpider(IOptions<SpiderOptions> options,
DependenceServices services,
ILogger<Spider> logger) : base(options, services, logger)
{
}
public static async Task RunAsync()
{
var builder = Builder.CreateDefaultBuilder<RecommendedRankingSpider>();
builder.UseSerilog();
builder.UseDownloader<HttpClientDownloader>();
builder.UseQueueDistinctBfsScheduler<HashSetDuplicateRemover>();
await builder.Build().RunAsync();
}
protected override async Task InitializeAsync(CancellationToken stoppingToken = default)
{
// 添加自定义解析
AddDataFlow(new Parser());
// 使用控制台存储器
AddDataFlow(new ConsoleStorage());
// 添加采集请求
await AddRequestsAsync(new Request("https://www.cnblogs.com/aggsite/topdiggs")
{
// 请求超时10秒
Timeout = 10000
});
}
class Parser : DataParser
{
public override Task InitializeAsync()
{
return Task.CompletedTask;
}
protected override Task ParseAsync(DataFlowContext context)
{
var recommendedRankingList = new List<RecommendedRankingModel>();
// 网页数据解析
var recommendedList = context.Selectable.SelectList(Selectors.XPath(".//article[@class='post-item']"));
foreach (var news in recommendedList)
{
var articleTitle = news.Select(Selectors.XPath(".//a[@class='post-item-title']"))?.Value;
var articleSummary = news.Select(Selectors.XPath(".//p[@class='post-item-summary']"))?.Value?.Replace("\n", "").Replace(" ", "");
var articleUrl = news.Select(Selectors.XPath(".//a[@class='post-item-title']/@href"))?.Value;
recommendedRankingList.Add(new RecommendedRankingModel
{
ArticleTitle = articleTitle,
ArticleSummary = articleSummary,
ArticleUrl = articleUrl
});
}
using (StreamWriter sw = new StreamWriter("recommendedRanking.txt"))
{
foreach (RecommendedRankingModel model in recommendedRankingList)
{
string line = $"文章标题:{model.ArticleTitle}\r\n文章简介:{model.ArticleSummary}\r\n文章地址:{model.ArticleUrl}";
sw.WriteLine(line+ "\r\n ==========================================================================================");
}
}
return Task.CompletedTask;
}
}
}
Program调用
internal class Program
{
static async Task Main(string[] args)
{
Console.WriteLine("Hello, World!");
await RecommendedRankingSpider.RunAsync();
Console.WriteLine("数据抓取完成");
}
}抓取数据和页面数据对比
抓取数据:

页面数据:

项目源码地址
更多项目实用功能和特性欢迎前往项目开源地址查看,别忘了给项目一个Star支持。
GitHub源码地址:https://github.com/dotnetcore/DotnetSpider
GitHub wiki:https://github.com/dotnetcore/DotnetSpider/wiki
优秀项目和框架精选
该项目已收录到C#/.NET/.NET Core优秀项目和框架精选中,关注优秀项目和框架精选能让你及时了解C#、.NET和.NET Core领域的最新动态和最佳实践,提高开发工作效率和质量。坑已挖,欢迎大家踊跃提交PR推荐或自荐(让优秀的项目和框架不被埋没)。
https://github.com/YSGStudyHards/DotNetGuide/blob/main/docs/DotNet/DotNetProjectPicks.md
DotNetGuide技术社区交流群
- DotNetGuide技术社区是一个面向.NET开发者的开源技术社区,旨在为开发者们提供全面的C#/.NET/.NET Core相关学习资料、技术分享和咨询、项目推荐、招聘资讯和解决问题的平台。
- 在这个社区中,开发者们可以分享自己的技术文章、项目经验、遇到的疑难技术问题以及解决方案,并且还有机会结识志同道合的开发者。
- 我们致力于构建一个积极向上、和谐友善的.NET技术交流平台,为广大.NET开发者带来更多的价值和成长机会。
.NET使用分布式网络爬虫框架DotnetSpider快速开发爬虫功能的更多相关文章
- 爬虫框架: DotnetSpider
[开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计 一 ,为什么要造轮子 有兴趣的同学可以去各大招聘网站看一下爬虫工程师的要求,大多是JAVA,PYTH ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 为什么要造轮子 同学们可以去各大招聘网站查看一下爬虫工程师的要求,大多是招JA ...
- [开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 五.如何做全站采集 为什么要造轮子 同学们可以去各大招聘网站查看一下爬虫工程师 ...
- java SSM框架 代码生成器 快速开发平台 websocket即时通讯 shiro redis
A代码编辑器,在线模版编辑,仿开发工具编辑器,pdf在线预览,文件转换编码 B 集成代码生成器 [正反双向](单表.主表.明细表.树形表,快速开发利器)+快速表单构建器 freemaker模版技术 , ...
- JAVA爬虫实践(实践三:爬虫框架webMagic和csdnBlog爬虫)
WebMagic WebMagic是一个简单灵活的Java爬虫框架.基于WebMagic,你可以快速开发出一个高效.易维护的爬虫. 采用HttpClient可以实现定向的爬虫,也可以自己编写算法逻辑来 ...
- 十个Python爬虫武器库示例,十个爬虫框架,十种实现爬虫的方法!
一般比价小型的爬虫需求,我是直接使用requests库 + bs4就解决了,再麻烦点就使用selenium解决js的异步 加载问题.相对比较大型的需求才使用框架,主要是便于管理以及扩展等. 1.Scr ...
- C# 爬虫框架实现 流程_爬虫结构/原理
目录链接:C# 爬虫框架实现 概述 首先需要讲的是,爬虫的原理.其实在我看来,爬虫只是用来解决以下四个问题的工具: 提取哪些网页 提取网页上的哪些内容 存储到哪里(推荐数据库/开源类/Console) ...
- 干货!JNPF快速开发平台功能一览
JNPF,采用主流的两大技术Java/.Net开发,是一套低代码开发平台,可视化开发环境,有拖拽式的代码生成器,灵活的权限配置.SaaS服务,强大的接口对接,随心可变的工作流引擎,一站式开发多端使 ...
- JavaWeb_(Hibernate框架)使用Hibernate开发用户注册功能
使用Hibernate开发用户注册功能: 用户在register.jsp表单成功后,页面跳转到login.html,数据库中会存放用户注册的信息 <%@ page language=" ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [二] 基本使用
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 使用环境 Visual Studio 2015 or later .NET 4 ...
随机推荐
- 微信小程序预览时显示有图片未上传
最近在做小程序项目,在项目里面加了几个图片.在预览调试时出现弹窗显示"文件未上传",但是在左侧的模拟器上却是能正常显示的. 解决思路: 图片在本地和模拟器上显示正常,表示图片本身没 ...
- Django+anaconda(spyder)
一.搭建django虚拟环境 打开anaconda prompt 输入:conda create -n mydjango_env 判断(y/n):y 查看虚拟环境 conda env list *号表 ...
- [信友队图灵杯中级组-D]基础循环结构练习题
2023-5-13 题目 题目传送门 难度&重要性(1~10):6.5 题目来源 信友队图灵杯 题目算法 构造 解题思路 我们可以知道,在一开始我们得到的 \(a\) 数组是 \(1,2,3, ...
- 从头到尾说一次 Spring 事务管理(器)
事务管理,一个被说烂的也被看烂的话题,还是八股文中的基础股之一. 本文会从设计角度,一步步的剖析 Spring 事务管理的设计思路(都会设计事务管理器了,还能玩不转?) 为什么需要事务管理? 先看看 ...
- Vs2022安装.Net4.5程序包
因为VS2022将不再支持.NET4.5,即使在Visual Studio Installer中也找不到.NET4.5的选项 我们可以在NuGet包中下载.NET 4.5的工具包 找到程序包管理器控制 ...
- [Mysql] 存储过程简单理解
什么是存储过程 简单的说, 就是一组SQL语句集, 功能强大, 可以实现一些比较复杂的逻辑功能. 其实就和编程语言的面向过程函数一样. ps: 存储过程与触发器类似, 但存储过程是主动调用, 触发器是 ...
- FastGPT 接入飞书(不用写一行代码)
FastGPT V4 版本已经发布,可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景,例如联网谷歌搜索,操作数据库等等,功能非常强大,还没用过的同学赶紧去试试吧. 飞书相比同类产品算是 ...
- MOOC慕课课表
8. 教育法学,共11单元---课件全开放状态,可以1次全学完开课时间: 2020年08月17日 ~ 2020年12月16日进行至第1周,共18周学时安排: 3-5小时每周 9. 教师职业道德与教育政 ...
- tunm二进制协议在python上的实现
tunm二进制协议在python上的实现 tunm是一种对标JSON的二进制协议, 支持JSON的所有类型的动态组合 支持的数据类型 基本支持的类型 "u8", "i8& ...
- Net 高级调试之三:类型元数据介绍(同步块表、类型句柄、方法描述符等)
一.简介 今天是<Net 高级调试>的第三篇文章,压力还是不小的.上一篇文章,我们浅浅的谈了谈 CLR 和 Windows 加载器是如何加载 Net 程序集的,如何找到程序的入口点的,有了 ...