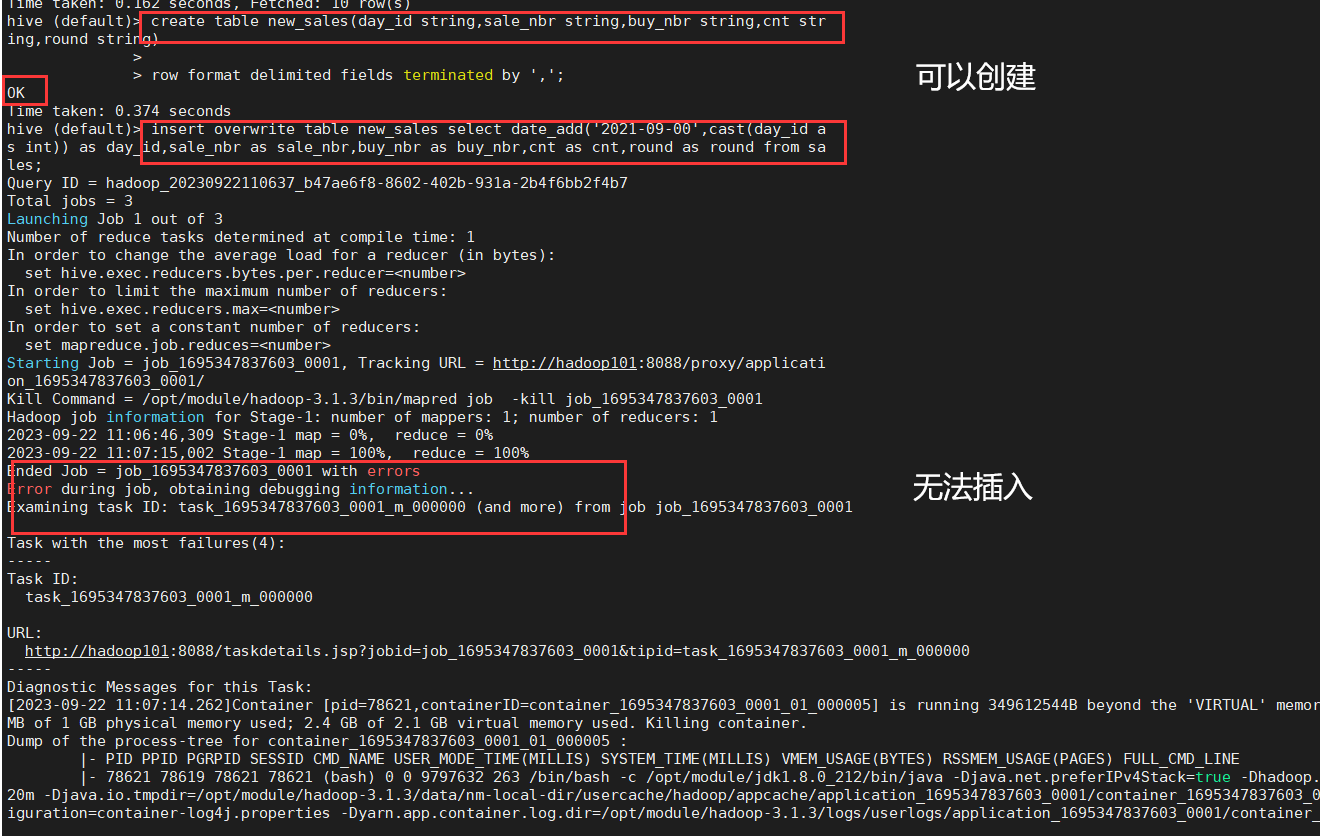
hive报错Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask[已解决]
我的报错信息
Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
解决1(可行):不走yarn走本地模式插入数据:
插入前在hive命令行输入(当前会话生效,退出会话失效,可将配置持久化到hive的配置文件中但不建议):set hive.exec.mode.local.auto=true;
解决2(可行):给yarn增加运行内存,配置如下:
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
解决3(未尝试,理论可行):设置spark引擎
插入前在hive命令行输入(当前会话生效,退出会话失效,可将配置持久化到hive的配置文件中):set hive.execution.engine=spark;
注意:Name node is in safe mode. -> hdfs进入安全模式会导致无法对hdfs进行读写
which: no hbase in (/usr/local/bin:/u
找不到hbase,让他找到就行,进行环境变量的配置
hive报错Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask[已解决]的更多相关文章
- hive报错 Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:For direct MetaStore DB connections,
学习hive 使用mysql作为元数据 hive创建数据库和切换数据库都是可以的 但是创建表就是出问题 百度之后发现 是编码问题 特别记录一下~~~ 1.报错前如图: 2.在mysql数据库中执行如 ...
- hive 字符集问题 报错 Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:For direct MetaStore DB connections,
学习hive 使用mysql作为元数据 hive创建数据库和切换数据库都是可以的 但是创建表就是出问题 百度之后发现 是编码问题 特别记录一下~~~ 1.报错前如图: 2.在mysql数据库中执行如 ...
- hive遇到FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask错误
hive遇到FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask错误 起因 ...
- FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:javax.jdo.JDODataStoreException: An exception was thrown while adding/validating class(es) :
在hive命令行创建表时报错: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. ...
- Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. org/apache/hadoop/hbase/
Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. org/apache/hadoop/hbase/ ...
- hive从本地导入数据时出现「Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask」错误
现象 通过load data local导入本地文件时报无法导入的错误 hive> load data local inpath '/home/hadoop/out/mid_test.txt' ...
- FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(me
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(me ...
- FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. com/mongodb/util/JSON
问题: 将MongoDB数据导入Hive,按照https://blog.csdn.net/thriving_fcl/article/details/51471248文章,在hive建外部表与mongo ...
- Hive的Shell里hive> 执行操作时,出现FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask错误的解决办法(图文详解)
不多说,直接上干货! 这个问题,得非 你的hive和hbase是不是同样都是CDH版本,还是一个是apache版本,一个是CDH版本. 问题详情 [kfk@bigdata-pro01 apache-h ...
- 解决hiveserver2报错:java.io.IOException: Job status not available - Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
用户使用的sql: select count( distinct patient_id ) from argus.table_aa000612_641cd8ce_ceff_4ea0_9b27_0a3a ...
随机推荐
- nlp入门(三)基于贝叶斯算法的拼写错误检测器
源码请到:自然语言处理练习: 学习自然语言处理时候写的一些代码 (gitee.com) 数据来源:norvig.com/big.txt 贝叶斯原理可看这里:机器学习算法学习笔记 - 过客匆匆,沉沉浮浮 ...
- 解决WSL执行systemctl命令报错:Failed to get D-Bus connection
问题描述 笔者通过WSL安装了CentOS7系统,刚开始一切都很顺利.当执行systemctl命令时,却意外报错:Failed to get D-Bus connection: Operation n ...
- [ABC146E] Rem of Sum is Num
2023-02-27 题目 题目传送门 翻译 翻译 难度&重要性(1~10):4 题目来源 AtCoder 题目算法 数学 解题思路 先对整个序列求前缀和 \(sum_k=\sum_{i=1} ...
- java与es8实战之二:实战前的准备工作
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本篇是<java与es8实战>系 ...
- doris单机安装部署
原文出处 doris单机安装部署 下载Doris 环境要求 Linux系统:Centos7.x或Ubantu16.04及以上版本 Java运行环境: JDK8 java -version 在windo ...
- Pytorch构建超分辨率模型——常用模块
Import required libraries: import torch import torch.nn as nn import torch.optim as optim from torch ...
- 图解 LeetCode 算法汇总——回溯
本文首发公众号:小码A梦 回溯算法是一种常见的算法,常见用于解决排列组合.排列问题.搜索问题等算法,在一个搜索空间中寻找所有的可能的解.通过向分支不断尝试获取所有的解,然后找到合适的解,找完一个分支后 ...
- Skynet:Debug Console的扩展
起因 最近上线服务器遇到了一些问题,上个月CPU暴涨的问题,那个经查验是死循环导致endless loop了. 这周又遇到了mem占用达到96%的问题,在debug console里调用了gc之后,跌 ...
- 在Go中如何实现并发
Go语言的并发机制是其强大和流行的一个关键特性之一.Go使用协程(goroutines)和通道(channels)来实现并发编程,这使得编写高效且可维护的并发代码变得相对容易.下面是Go的并发机制的详 ...
- Pandas 读取 Excel 斜着读
读取 Excel 斜着读数据 import pandas as pd def read_sideling(direction, sheet_name, row_start, col_start, ga ...