论文解读:ACL2021 NER | 基于模板的BART命名实体识别
摘要:本文是对ACL2021 NER 基于模板的BART命名实体识别这一论文工作进行初步解读。
本文分享自华为云社区《ACL2021 NER | 基于模板的BART命名实体识别》,作者: JuTzungKuei 。
论文:Cui Leyang, Wu Yu, Liu Jian, Yang Sen, Zhang Yue. TemplateBased Named Entity Recognition Using BART [A]. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 [C]. Online: Association for Computational Linguistics, 2021, 1835–1845.
链接:https://aclanthology.org/2021.findings-acl.161.pdf
代码:https://github.com/Nealcly/templateNER

0、摘要
- 小样本NER:源领域数据多,目标领域数据少
- 现有方法:基于相似性的度量
- 缺点:不能利用模型参数中的知识进行迁移
- 提出基于模板的方法
- NER看作一种语言模型排序问题,seq2seq框架
- 原始句子和模板分别作为源序列和模板序列,由候选实体span填充
- 推理:根据相应的模板分数对每个候选span分类
- 数据集
- CoNLL03 富资源
- MIT Movie、MIT Restaurant、ATIS 低资源
1、介绍
- NER:NLP基础任务,识别提及span,并分类
- 神经NER模型:需要大量标注数据,新闻领域很多,但其他领域很少
- 理想情况:富资源 知识迁移到 低资源
- 实际情况:不同领域实体类别不同
- 训练和测试:softmax层和crf层需要一致的标签
- 新领域:输出层必须再调整和训练
- 最近,小样本NER采用距离度量:训练相似性度量函数
- 优:降低了领域适配
- 缺:(1)启发式最近邻搜索,查找最佳超参,未更新网络参数,不能改善跨域实例的神经表示;(2)依赖源域和目标域相似的文本模式
- 提出基于模板的方法
- 利用生成PLM的小样本学习潜力,进行序列标注
- BART由标注实体填充的预定义模板微调
- 实体模板:<candidate_span> is a <entity_type> entity
- 非实体模板:<candidate_span> is not a named entity
- 方法优点:
- 可有效利用标注实例在新领域微调
- 比基于距离的方法更鲁棒,即使源域和目标域在写作风格上有很大的差距
- 可应用任意类别的NER,不改变输出层,可持续学习
- 第一个使用生成PLM解决小样本序列标注问题
- Prompt Learning(提示学习)
2、方法
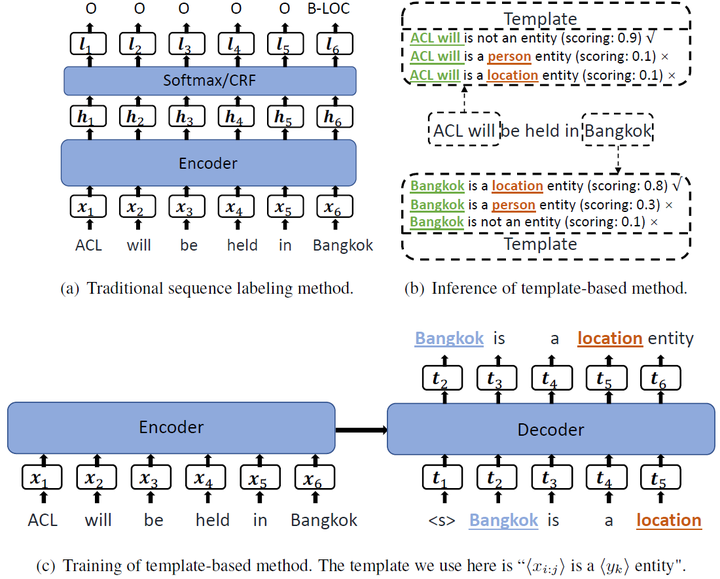
2.1、创建模板
- 将NER任务看作是seq2seq框架下的LM排序问题
- 标签集 entity_type:\mathbf{L}=\{l_1,...,l_{|L|}\}L={l1,...,l∣L∣},即{LOC, PER, ORG, …}
- 自然词:\mathbf{Y}=\{y_1,...,y_{|L|}\}Y={y1,...,y∣L∣},即{location, person, orgazation, …}
- 实体模板:\mathbf{T}^{+}_{y_k}=\text{<candidate\_span> is a location entity.}Tyk+=<candidate_span> is a location entity.
- 非实体模板:\mathbf{T}^{-}=\text{<candidate\_span> is not a named entity.}T−=<candidate_span> is not a named entity.
- 模板集合:\mathbf{T}=[\mathbf{T}^{+}_{y_1},...,\mathbf{T}^{+}_{y_{|L|}},\mathbf{T}^{-}]T=[Ty1+,...,Ty∣L∣+,T−]
2.2、推理
- 枚举所有的span,限制n-grams的数量1~8,每个句子有8n个模板
- 模板打分:\mathbf{T}_{{y_k},x_{i:j}}=\{t_1,...,t_m\}Tyk,xi:j={t1,...,tm}
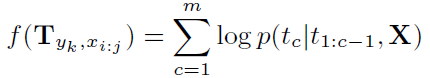
- x_{i:j}xi:j实体得分最高
- 如果存在嵌套实体,选择得分较高的一个
2.3、训练
- 金标实体用于创建模板
- 实体x_{i:j}xi:j的类型为y_kyk,其模板为:\mathbf{T}^{+}_{y_k,x_{i:j}}Tyk,xi:j+
- 非实体x_{i:j}xi:j,其模板为:\mathbf{T}^{-}_{x_{i:j}}Txi:j−
- 构建训练集:
- 正例:(\mathbf{X}, \mathbf{T}^+)(X,T+)
- 负例:(\mathbf{X}, \mathbf{T}^-)(X,T−),随机采样,数量是正例的1.5倍
- 编码:\mathbf{h}^{enc}=\text{ENCODER}(x_{1:n})henc=ENCODER(x1:n)
- 解码:\mathbf{h}_c^{dec}=\text{DECODER}(h^{enc}, t_{1:c-1})hcdec=DECODER(henc,t1:c−1)
- 词t_ctc的条件概率:p(t_c|t_{1:c-1},\mathbf{X})=\text{SOFTMAX}(\mathbf{h}_c^{dec}\mathbf{W}_{lm}+\mathbf{b}_{lm})p(tc∣t1:c−1,X)=SOFTMAX(hcdecWlm+blm)
- \mathbf{W}_{lm} \in \mathbb{R}^{d_h\times |V|}Wlm∈Rdh×∣V∣
- 交叉熵loss
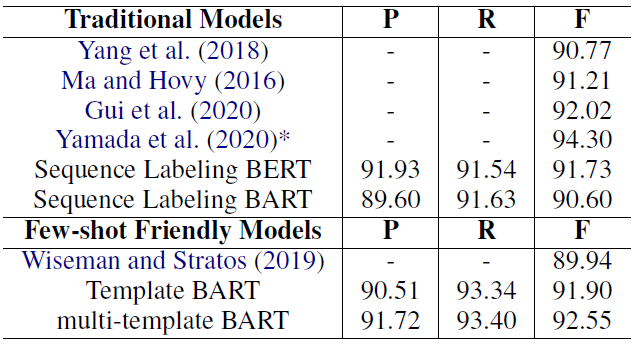
3、结果
- 不同模板类型的测试结果
- 选择前三个模板,分别训练三个模型

- 实验结果
- 最后一行是三模型融合,实体级投票
号外号外:想了解更多的AI技术干货,欢迎上华为云的AI专区,目前有AI编程Python等六大实战营供大家免费学习。
论文解读:ACL2021 NER | 基于模板的BART命名实体识别的更多相关文章
- DL4NLP —— 序列标注:BiLSTM-CRF模型做基于字的中文命名实体识别
三个月之前 NLP 课程结课,我们做的是命名实体识别的实验.在MSRA的简体中文NER语料(我是从这里下载的,非官方出品,可能不是SIGHAN 2006 Bakeoff-3评测所使用的原版语料)上训练 ...
- PyTorch 高级实战教程:基于 BI-LSTM CRF 实现命名实体识别和中文分词
前言:译者实测 PyTorch 代码非常简洁易懂,只需要将中文分词的数据集预处理成作者提到的格式,即可很快的就迁移了这个代码到中文分词中,相关的代码后续将会分享. 具体的数据格式,这种方式并不适合处理 ...
- 抛弃模板,一种Prompt Learning用于命名实体识别任务的新范式
原创作者 | 王翔 论文名称: Template-free Prompt Tuning for Few-shot NER 文献链接: https://arxiv.org/abs/2109.13532 ...
- 【NER】对命名实体识别(槽位填充)的一些认识
命名实体识别 1. 问题定义 广义的命名实体识别是指识别出待处理文本中三大类(实体类.时间类和数字类).七小类(人名.机构名.地名.日期.货币和百分比)命名实体.但实际应用中不只是识别上述所说的实体类 ...
- 神经网络结构在命名实体识别(NER)中的应用
神经网络结构在命名实体识别(NER)中的应用 近年来,基于神经网络的深度学习方法在自然语言处理领域已经取得了不少进展.作为NLP领域的基础任务-命名实体识别(Named Entity Recognit ...
- 2. 知识图谱-命名实体识别(NER)详解
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 在解了知识图谱的全貌之后,我们现在慢慢的开始深入的学习知识 ...
- 基于bert的命名实体识别,pytorch实现,支持中文/英文【源学计划】
声明:为了帮助初学者快速入门和上手,开始源学计划,即通过源代码进行学习.该计划收取少量费用,提供有质量保证的源码,以及详细的使用说明. 第一个项目是基于bert的命名实体识别(name entity ...
- 基于keras实现的中文实体识别
1.简介 NER(Named Entity Recognition,命名实体识别)又称作专名识别,是自然语言处理中常见的一项任务,使用的范围非常广.命名实体通常指的是文本中具有特别意义或者指代性非常强 ...
- 【神经网络】神经网络结构在命名实体识别(NER)中的应用
命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型,如下图.它是NLP领域中一些复杂任务(例如关系抽取,信息检索等)的 ...
- 命名实体识别(NER)
一.任务 Named Entity Recognition,简称NER.主要用于提取时间.地点.人物.组织机构名. 二.应用 知识图谱.情感分析.机器翻译.对话问答系统都有应用.比如,需要利用命名实体 ...
随机推荐
- LAMP搭建流程与应用
LAMP搭建流程 1.环境准备 [root@localhost opt]# systemctl stop firewalld.service [root@localhost opt]# seten ...
- 【re】[NISACTF 2022]string --linux下的随机数
附件下载,查壳 发现是ELF程序,64位,ida打开分析 flag函数点进去 前面一堆代码其实都不重要,直接看主要代码: puts("The length of flag is 13&qu ...
- Python 利用pandas和matplotlib绘制柱状折线图
创建数据可视化图表:柱状图与折线图结合 在数据分析和展示中,经常需要将数据可视化呈现,以便更直观地理解数据背后的趋势和关联关系.本篇文章将介绍如何使用 Python 中的 Pandas 和 Matpl ...
- Johnson 最短路算法
Johnson 算法 全源最短路径求解其实是单源最短路径的推广,求解单源最短路径的两种算法时间复杂度分别为: Dijkstra 单源最短路径算法:时间复杂度为 \(O(E + VlogV)\),要求权 ...
- L2-028 秀恩爱分得快
90行,调了俩小时,大约有以下坑点. 1.每个数字都可能正负出现,比如-0 0,-1 1,一开始以为一个数的正负只会出现一个. 2.当俩人都不出现在照片中,那么输出俩人就行 3.当其中一个人不在照片里 ...
- 生成伪随机数 rand;srand函数
1 相关内容来自鱼c论坛https://fishc.com.cn/forum.php?mod=viewthread&tid=84363&extra=page%3D1%26filter% ...
- Codeforces Round #706 (Div. 2) A-D题解
写在前边 链接:Codeforces Round #706 (Div. 2) \(A,B,C,D\),这场有点简单,不过由于A写炸了后边题连看都没看就溜了,就从上大分变成了掉大分 A. Split i ...
- [Flink] Flink(CDC/SQL)Job在启动时,报“ConnectException: Error reading MySQL variables: Access denied for user 'xxxx '@'xxxx' (using password: YES)”(1个空格引发的"乌龙")
1 问题描述 1.1 基本信息 所属环境:CN-PT 问题时间:2023-11-21 所属程序: Flink Job(XXXPT_dimDeviceLogEventRi) 作业类型: Flink SQ ...
- 【开源项目推荐】通用SQL数据血缘分析工具——Sqllineage
大家好,我是独孤风,从本周开始,争取每周为大家带来一个优秀的开源项目推荐. 开源项目不仅促进了技术的发展和普及,还为全球范围内的开发者和用户社区建立了一个共享知识.协作和创新的平台.站在巨人的肩膀上才 ...
- Nginx根据Origin配置禁止跨域访问策略
产品需要通过某所的安全测评扫描,其中提出一个关于跨域策略配置不当的问题,如下: 这个需要根据客户端传递的请求头中的Origin值,进行安全的跨站策略配置,目的是对非法的origin直接返回403错误页 ...