Deep Learning on Graphs: A Survey第五章自动编码论文总结
最近老师让我们读的一片论文,已经开组会讲完了,我负责的是第五章,图的自动编码,现在再总结一遍,便于后者研读。因为这篇论文是一篇综述,所以里边有些符号,在这个模型里是一个意思,在另一个模型了,符号又变了。
GRAPH AUTOENCODERS
预备知识:
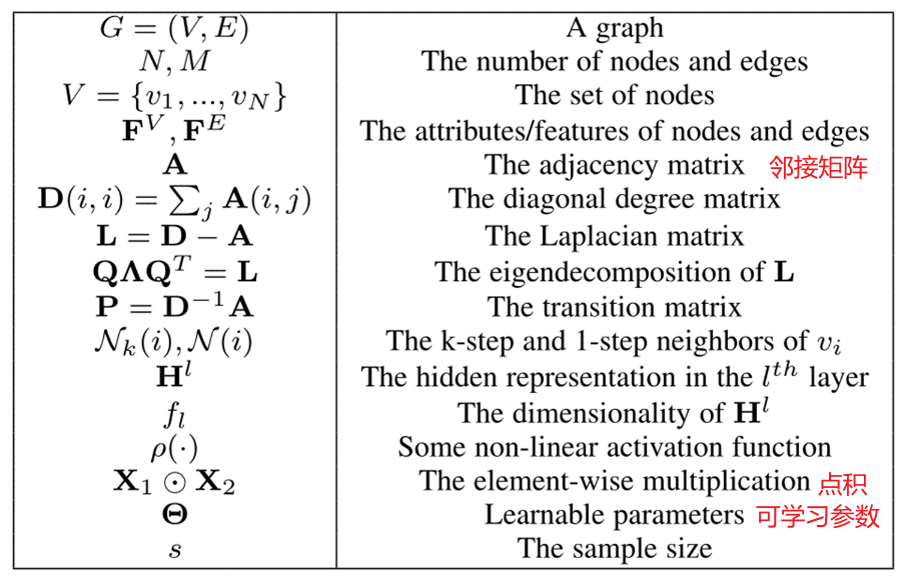
1.论文中符号表解释如下:
2.编码器的通俗解释:
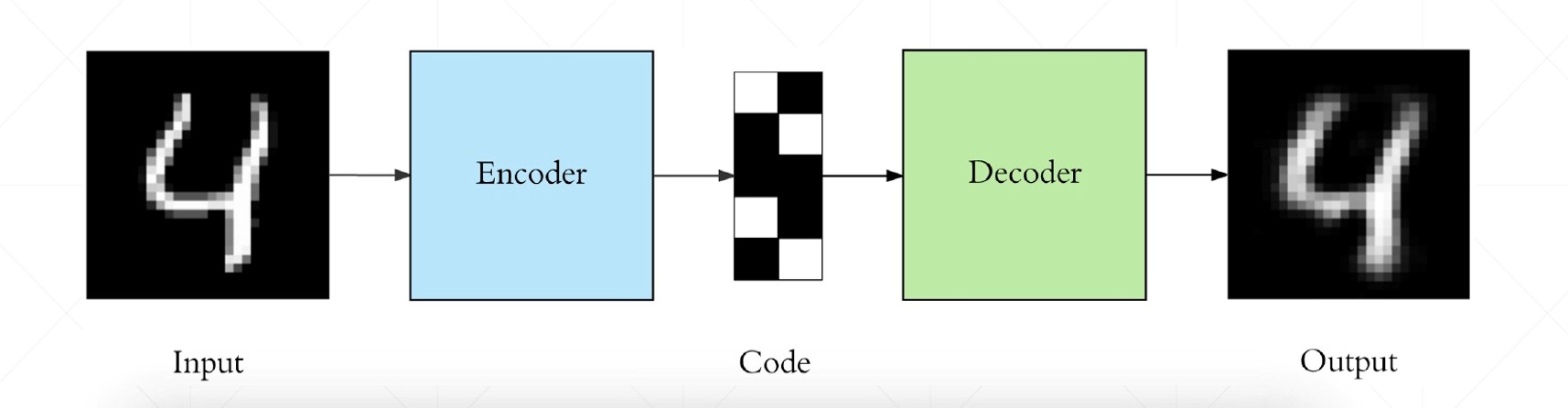
定义:
将输入x通过一个编码器,得到一个低维的向量h表示,然后再通过一个解码器,尽可能的还原最初所输入的特征 。公式的话就是:
x->h->x'目的:
不是为了让输出值等于输入值,而是希望通过训练输出值等于输入值的自编码器,让低维向量h将具有价值属性,让低维向量h可以更好的表示输入x的最重要的特征。
作用:
1.降维,预处理,数据去噪,保存数据中有价值的信息,丢掉一些没用的信息
2.发挥无监督数据的优势(数量大,但是无标签)
3.AE和VAE:
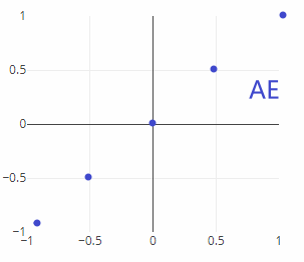
AE:自动编码器,是点对点的输出。例如下图,你输入{0.5},对应的输出就是{0.5},你输入{1},对应的输出就是{1},你如果输入{0.75},编码器就不知道输出什么了,就不会了。
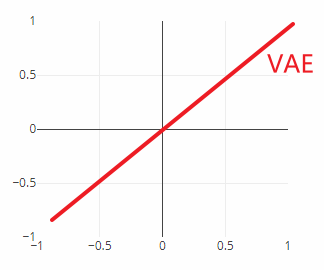
VAE:自动编码器,是线性输出,你的输入数据x通过编码器后,又经历了一个高斯分布的计算。
VAE中加入高斯分布的过程,具体如下图:
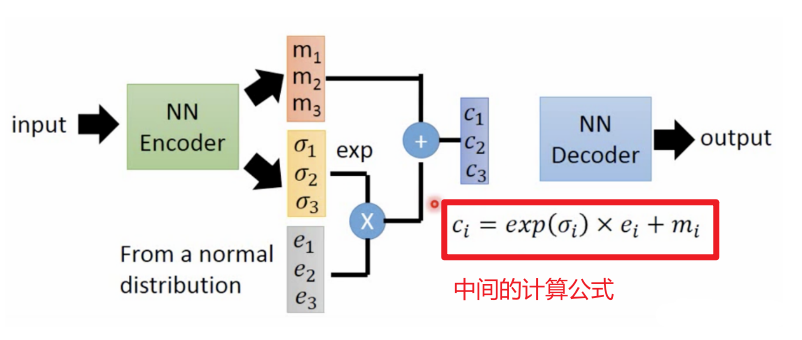
4. L1 loss和L2 loss
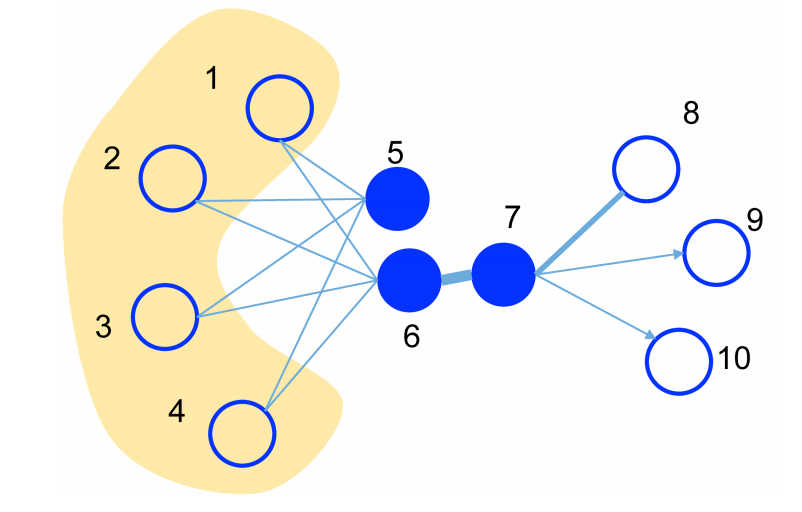
L1 loss(一阶损失):表示是两个顶点的直接相连,反应的是局部的相似性。例如图中的{6,7}节点,它们在输入向量x的时候是直接相连的,就具有很强的相似性,当输入向量x通过编码器后,转化成低维向量h,在h中{6,7}节点,也应该尽可能的距离相近。
L2 loss(二阶损失):表示是两个顶点的间接相连,反应的是全局的相似性。例如图中的{5,6}节点,虽然它们在输入向量x中不是直接相连的,但是它们有很多共同的邻居节点{1,2,3,4},所以它们也有比较强的相似性,当输入向量x通过编码器后,转化成低维向量h,在h中{5,6}节点,也应该尽可能的距离相近。
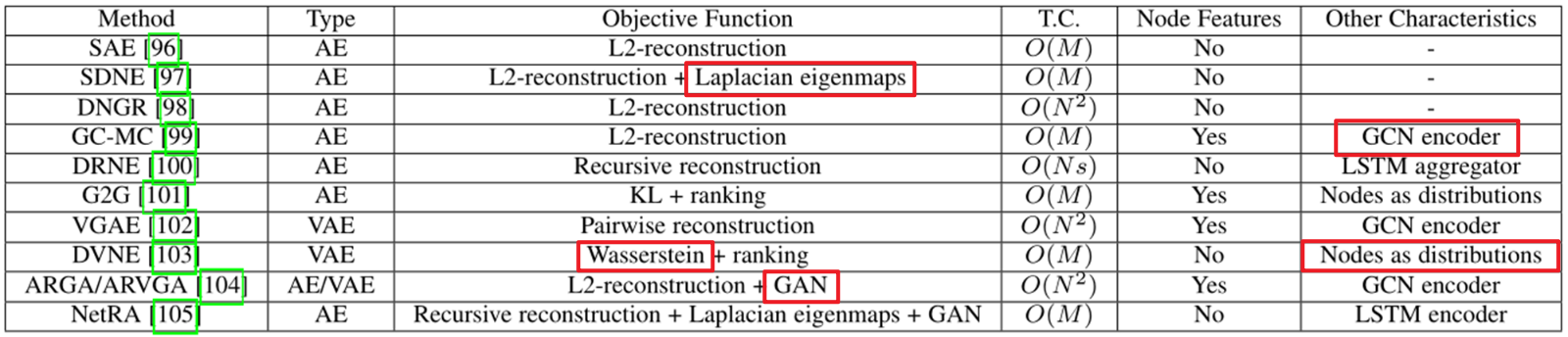
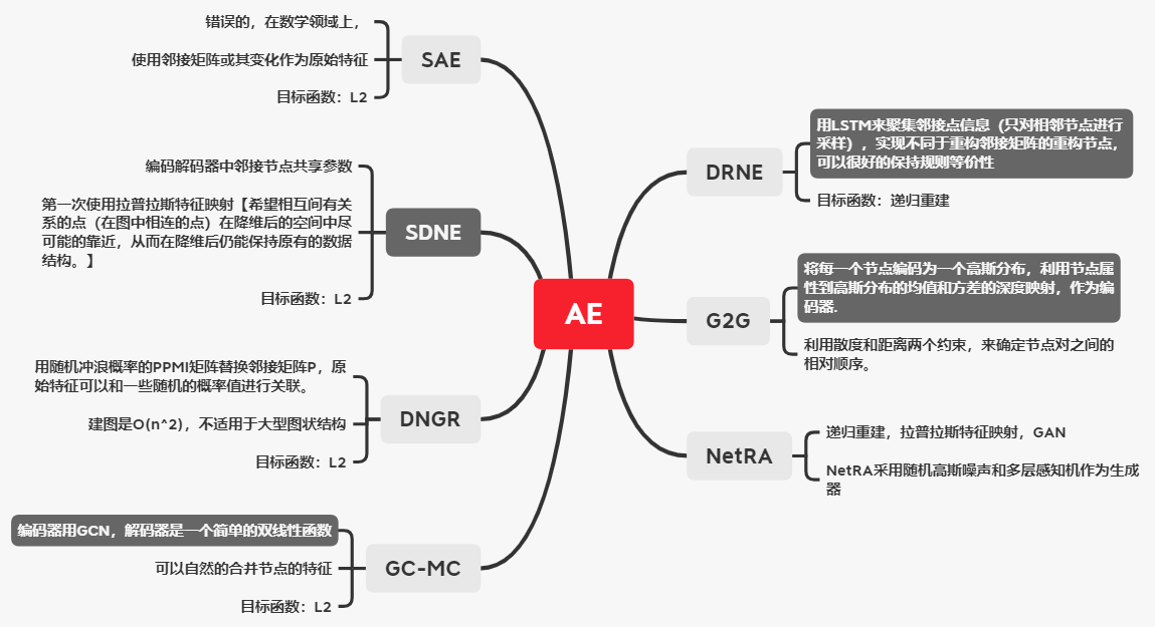
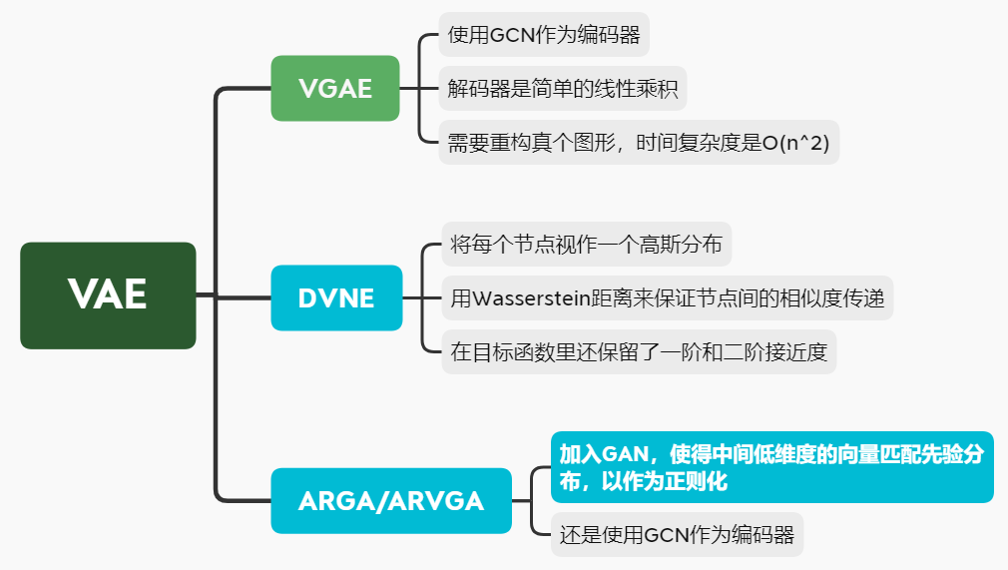
这篇论文,主要是讲了几个模型,然后对每个模型提了几个特征我都总结到下边了,重点将SDNE模型,DVNE模型,ARGA/ARVGA模型的框架图列出来了。
Autoencoders:
SDNE模型,这是一个自动编码器的模型。在这个模型里是
x->y->x',改模型是将邻接矩阵作为输入。
用
拉普拉斯特征映射作为一阶损失的函数,下面是拉普拉斯的公式,意思就是在你输入的向量中{xi,xj}两个节点靠的越相近,也就是公式中蓝框内的值越小,wij的值就越大,因为wij的值比较大,所以所占权重比较大,想要让损失函数变得更小,就要让{yi,yj}越相近。
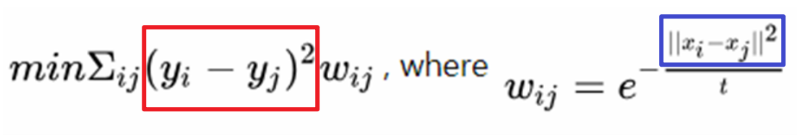
用L2带权损失函数来计算全局损失性,也就是用重构损失,重构损失就是你的输入A(i,:)和通过解码器后的输出g(hi)的损失值。大多数图的网络是稀疏图,点乘bi的目的是为了让在输入中相邻的节点,在重构后变得更相邻。
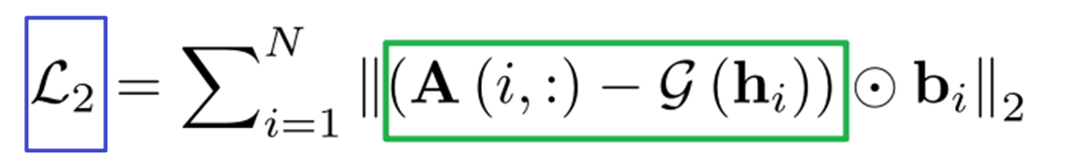

Variational Autoencoders:
DVNE模型,这是一个变分自动编码器的模型。
推土机距离的解释看文章末尾的参考中的文章,这里就不解释了。
用
**Wasserstein距离** (推土机距离),下边是一阶损失函数,公式的意思是:让Eij的值更小,让Eij’的值更大,也就是让i节点和相邻节点j靠的更近,让i节点和不相邻节点j‘里的更远:

Eij代表的是两个分布之间的推土机距离
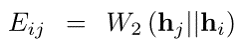
{i,j,k}三个节点,其中i和j是相邻的,i和k是不相邻的,通过下边的这个约束,来控制低维向量上节点之间的关系,下边约束的意思是:i与所有相邻节点的推土机距离,都小于与不相邻节点的推土机距离。
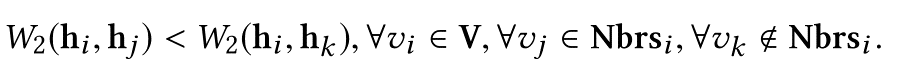
使用重构损失来计算全局损失(这里没搞懂)
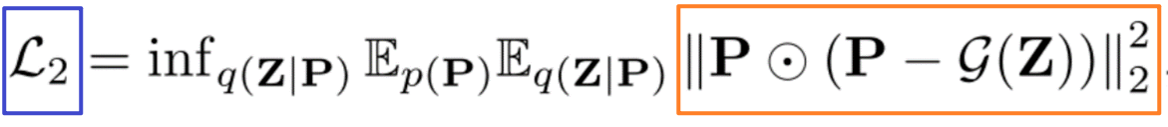
模型的大体意思是:任意三个节点作为一次输入,然后利用推土机距离来控制节点之间的距离约束,然后进行高斯分布,得到z,再通过解码器得到输出。

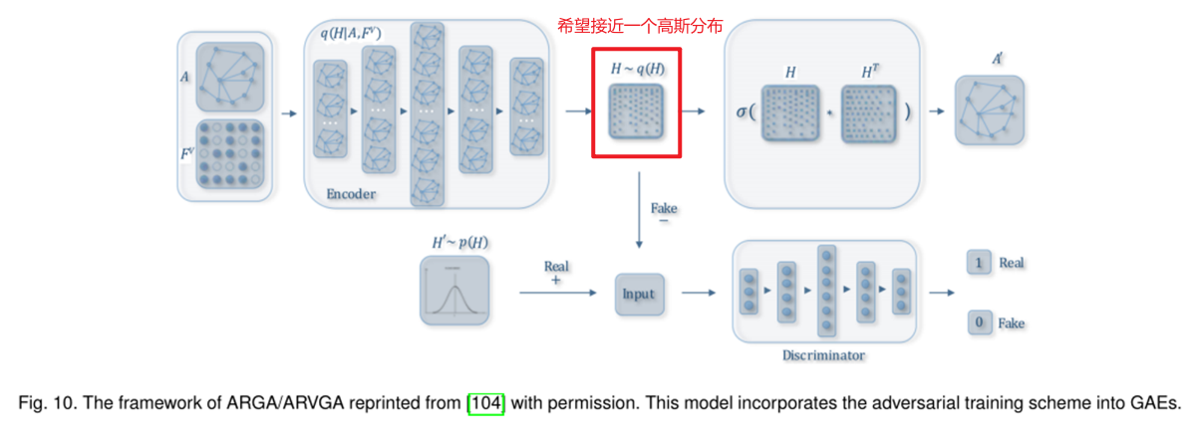
ARGA/ARVGA模型
模型大体意思:为了让低维向量更接近一个高斯分布,就是加入了鉴别器,让鉴别器鉴别编码器生成的低维向量是否复合高斯分布。如果复合的话就返回true,不符合就返回false。
GAN的公式:令下边式子的值为V,则鉴别器的意愿是想让V越大越好,生成器的意愿是让V值越小越好。
- 先看鉴别器,红框和蓝框都有鉴别器,D(h)是一个高斯分布,是真的,D(z)是生成器生成的,是假的。鉴别器就是要让D(h)的值为1,让D(z)的值为0,这样鉴别器才鉴别成功,才能让V值取到最大,一旦其中某一个鉴别错误,也就是假的鉴成了真的,或者真的鉴成了假的,那么V值就成了log 0,成了负无穷。
- 看生成器,只有红框内有生成器,蓝框内就是个常数,不用看,生成器是想要V值越小越好,生成器想要自己生成的称为真的,成为true,也就是想要让D(z)成为1,那么红框内的值就是负无穷了,符合生成器的意愿。
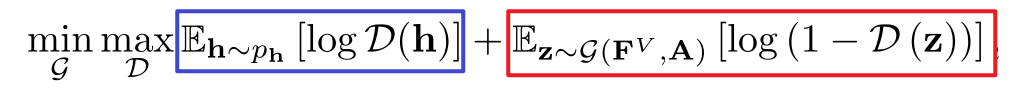
Improvements and Discussions:
1.Adversarial Training
将对抗训练加入总体架构,鉴别器旨在区分潜在表示是来自生成器还是先验分布
2.Inductive Learning
归纳学习,使用GCN+GAE等方式,多个模型结合,达到更好的效果
3.Similarity Measures
相似度衡量的方式,还可以优化,比如L2-reconstruction loss,拉普拉斯特征映射,和Wasserstein距离,选择一个合适的相似度衡量方式很重要。
参考的内容:
AE和VAE:https/blog.csdn.net/sinat_36197913/article/details/93630246
VAE:https/blog.csdn.net/roguesir/article/details/81263442
PCA原理:https/blog.csdn.net/luoluonuoyasuolong/article/details/90711318
一阶相似性和二阶相似性:https/www.cnblogs.com/cx2016/p/12801654.html
SDNE:https/zhuanlan.zhihu.com/p/56637181
https/dl.acm.org/doi/pdf/10.1145/2939672.2939753
DVNE: https/zhuanlan.zhihu.com/p/51766680
https://dl.acm.org/doi/pdf/10.1145/3219819.3220052
Wasserstein距离:https://zhuanlan.zhihu.com/p/84617531
拉普拉斯特征值映射原理如何解读?https/www.zhihu.com/question/326501281/answer/698228215
Deep Learning on Graphs: A Survey第五章自动编码论文总结的更多相关文章
- Geometric deep learning on graphs and manifolds using mixture model CNNs
Monti, Federico, et al. "Geometric deep learning on graphs and manifolds using mixture model CN ...
- How to do Deep Learning on Graphs with Graph Convolutional Networks
翻译: How to do Deep Learning on Graphs with Graph Convolutional Networks 什么是图卷积网络 图卷积网络是一个在图上进行操作的神经网 ...
- Deep Learning深入研究整理学习笔记五
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- 高光谱图像分类简述+《Deep Learning for Hyperspectral Image Classification: An Overview》综述论文笔记
论文题目<Deep Learning for Hyperspectral Image Classification: An Overview> 论文作者:Shutao Li, Weiwei ...
- Deep Learning.ai学习笔记_第五门课_序列模型
目录 第一周 循环序列模型 第二周 自然语言处理与词嵌入 第三周 序列模型和注意力机制 第一周 循环序列模型 在进行语音识别时,给定一个输入音频片段X,并要求输出对应的文字记录Y,这个例子中输入和输出 ...
- (2020行人再识别综述)Person Re-Identification using Deep Learning Networks: A Systematic Review
目录 1.引言 2.研究方法 2.1本次综述的贡献 2.2综述方法 2.3与现有综述的比较 3.行人再识别基准数据集 3.1基于图像的再识别数据集 3.2基于视频的再识别数据集 4.基于图像的深度再识 ...
- Deep Learning综述[上]
Deep-Learning-Papers-Reading-Roadmap: [1] LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Dee ...
- 《Neural Network and Deep Learning》_chapter4
<Neural Network and Deep Learning>_chapter4: A visual proof that neural nets can compute any f ...
- why deep learning works
https://medium.com/towards-data-science/deep-learning-for-object-detection-a-comprehensive-review-73 ...
- deep learning书的阅读
最近坚持读书,虽然大多数读的都是一些闲书,传记.历史或者散文之类的书籍,但是也读了点专业书.闲书是散时间读的,放车里,有时间就拿起来读读,专业书则更多的靠得是专注.因为我给自己的规定是一定时间内读完几 ...
随机推荐
- kafka的简单架构
定义 Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue) , 主要应用于大数据实时处理领域. 1) Producer : 消息生产者,就是向 kafka broker ...
- vscode中输入``自动将光标后面一个单词选中,左右加入<w>和</w>标签 - snippets 的命令调用
需求 vscode中输入``自动将光标后面一个单词选中,左右加入和标签 步骤0 准备需要安装插件 vim - 这里的点击两次按键激活的快捷键,这个插件可以设置 macros - 一次执行多个命令的插件 ...
- 基于python的固定间隔时间执行实例解析
一 概念 datetime的用法如下: import datetime. # 打印当前时间 time1 = datetime.datetime.now() print(time1) # 打印按指定格式 ...
- 恒玄科技BES250解决方案之双耳链接调试总结和源码分析
一 前言 bes2500芯片在tws耳机应用十分广泛,该芯片有着资源强大,音质好,大厂背书等特色.吸引了不少粉丝跟随. 最近在调试该芯片的tws配对流程,花费了一些时间,踩了一些坑,这里做一个总结和备 ...
- python中bytes转int的实例(bytearray to short int in python)
python很多数据都是bytes格式的,经常需要转换成int或者short,笔者实际项目有需求,这里就做个笔记吧. 实例一: bytes转short:(无符号类型) import struct ba ...
- 【stars-one】JetBrains产品试用重置工具
原文[stars-one]JetBrains产品试用重置工具 | Stars-One的杂货小窝 一款可重置JetBrains全家桶产品的试用时间的小工具,与其全网去找激活码,还不如每个月自己手动重置试 ...
- 逆向通达信Level-2 续十 (trace脱壳)
本篇演示两图 1. trace 脱壳,你看到了几成指令是混淆的. 2. trace 脱壳过程中帮助 ida 定位脱壳代码片段. ida 不能定位的代码片段,通过trace来发现. 逆向通达信Level ...
- 自己想到的几道Java面试题
1.在抽象类中能否写main方法,为什么? 2.在接口中能否写main方法,为什么? 3.Java能否使用静态局部变量,为什么? 4.Java类变量,实例变量,局部变量在多线程环境下是否线程安全,为什 ...
- 🚀🚀🚀Elasticsearch 主副分片切换过程中对业务写入有影响吗
先说下结论,只要集群中的工作节点过半,有候选的master节点,挂掉的节点中不同时包含索引的主分片和副分片,那么ES是可以做到让业务无感知的进行主副分片切换的. 蓝胖子会先讲解下ES集群写入文档的原理 ...
- npm ERR! code ENOENT npm ERR! syscall open npm ERR! path C:\Users\shuzi\Desktop\保密文件项目\test-ui/package.json npm ERR! errno -4058
打开一个新的项目,因为当前项目文件夹下没有npm,"dev": "npm run start:dev",所以所以没有展示对应的运行图,如下图: 打开一个新的前端 ...