使用memoizee缓存函数提升性能,竟引发了indexOf的性能问题

壹 ❀ 引
公司前端组基本每个月会举行一次前端月会,用于做前端组基础设施以及其它重要信息的同步,会议最后一个环节就会分享本月前端同学在开发中所遇到的奇怪bug,或者一些有趣的问题。在分享的问题中,我发现一个关于缓存库memoizee引发的性能问题还挺有意思,毕竟一个提升性能问题的库居然还能引发其它性能缺陷,经典矛盾文学了,废话不多说,本文开始。
贰 ❀ 使用memoizee提升性能
我们抛开react 17中常用的useMemo类似的缓存函数hook,在react 16版本中,对于一个计算量较大的函数,可能很多同学都会想到借用缓存函数来做结果缓存处理,以达到性能提升的目的,而不同于自己造的轮子,现有的缓存函数库memoizee就是不错的推荐。
说在前面,所有的性能提升无非围绕空间换时间或者时间换空间来展开,而函数缓存就是典型的空间换时间,且思路都是将接受的参数作为key,计算的结果作为value,并形成key-value键值对存入一个对象。当下次再调用这个函数,且参数相同时,我们就能从对象中直接取回结果返回,从而避免重复的复杂的逻辑计算。
一个最简单的函数缓存例子:
// 用于缓存每个key的计算结果
const res = {};
const memoize = (num)=>{
// 假设之前已经计算过了,直接返回
if(res[num]!==undefined){
return res[num];
};
// 新参数?重新计算,并做缓存
const square = num*num;
res[num] = square;
return square;
};
console.log(memoize(2));// 4
console.log(memoize(3));// 9
// 这一次就走了缓存
console.log(memoize(2));// 4
上面这个例子虽然有缓存作用,但本质上是对于参数的缓存,它的功能非常单一,只能用于求数字的平方。那假设我现在要求数字的加法,或者数字的除法,我们岂不是得自己定义很多个这样的缓存函数?所以本质上,我们其实希望有一个函数,能起到一个包装器的作用,我们传入的任意函数都能被这个包装器转成缓存函数,同时在执行时也能对于相同参数做到缓存效果。那么三方库memoizee的作用就是如此。
简单科普下用法,毕竟本文的核心是分享使用memoizee所带来的性能问题,基本用法如下,更多用法请参照文档:
import memoize from 'memoizee'
const o1 = {a:1,b:2};
const o2 = o1;
const o3 = {a:1,b:2};
const fn = function (obj) {
console.log(1);
return obj.a + obj.b;
};
// fn作为参数,得到了一个有缓存效果的fn
const memoizeFn = memoize(fn);
memoizeFn(o1);
// o2与o1是同一个对象,走缓存
memoizeFn(o2);
// o3是一个新对象,不走缓存
memoizeFn(o3);
使用memoizee还有一个好处就是,我们函数的参数不一定都是数字字符串这类的基本类型,有时候还可能是一个对象。比如上述例子我们借用了memoizee生成了一个带有缓存效果函数memoizeFn,它所接收的参数就是对象,我们通过fn内部的console用于检验到底有没有走缓存,效果很明显,console一共执行两次,分别由参数o1与o3触发。所以借用三方库的好处就是,很多的边界场景它都有帮你考虑。
叁 ❀ memoizee引发的性能问题
前面说了,无论是memoizee还是我们自定义的缓存函数,本质上性能的提升都离不开空间换时间,缓存后直接拿结果虽然快,但随着缓存的结果越来越多,一千,一万到数十万,memoizee是否真的能符合我的高性能的预期呢?一个简单的例子来颠覆你的认知:
const fn = function (a) {
return a * a;
};
// 使用缓存
console.time('使用缓存');
const memoizeFn = memoize(fn);
for (let i = 0; i < 100000; i++) {
memoizeFn(i);
}
memoizeFn(90000);
console.timeEnd('使用缓存');
// 不使用缓存
console.time('不使用缓存');
for (let i = 0; i < 100000; i++) {
// 单纯执行,啥也不缓存
fn(i);
}
fn(90000);
console.timeEnd('不使用缓存');

上述代码分为两部分,使用了memoize做缓存,我们模拟了10W次执行,然后再次执行memoizeFn(90000)以达到取缓存的效果。而不使用缓存的部分则是现执行现使用,不走任何缓存。而让人惊讶的时,使用缓存的代码耗时6.5S,而没缓存的部分仅需2.74ms,后者比前者快2442倍!
我知道你现在心里已经产生了疑惑,我们再来做个更有趣的对比,在文章开头我们写了一个劣质的缓存函数,没关系,我们稍加改造,如下:
console.time('使用自定义的缓存');
const res = {};
const memoizeFn_ = (num)=>{
// 假设之前已经计算过了,直接返回
if(res[num]!==undefined){
return res[num];
};
// 新参数?重新计算,并做缓存
const square = num*num;
res[num] = square;
return square;
};
for (let i = 0; i < 100000; i++) {
// 单纯执行,啥也不缓存
memoizeFn_(i);
}
memoizeFn_(90000);
console.timeEnd('使用自定义的缓存');
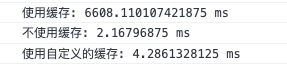
使用自定义缓存毕竟有存储和查询的操作,所以耗时上肯定比不使用缓存要稍微慢一点,但整体耗时只差2ms,到这里我们可以断定memoizee在实现上一定有猫腻,遇事不决读源码,于是我们发现了memoizee中的如下代码:
module.exports = function () {
var lastId = 0, argsMap = [], cache = [];
return {
get: function (args) {
// 注意这一句代码,这里使用了indexOf用来查询之前这个参数有没有执行过
var index = indexOf.call(argsMap, args[0]);
return index === -1 ? null : cache[index];
}
// 删除了部分不相关的代码
};
};
不卖关子,当使用memoizee做缓存,且函数参数只有一个时,memoizee的get查询实现其实借用了indexOf。站在时间复杂度层面,从数组中遍历查询一个元素,最快是O(1),最坏是O(N),这种情况一般以最坏的情况来作为时间复杂度,因此时间复杂度是O(N)。
那为什么上面那个例子耗时这么逆天?那是因为缓存函数本身就是边执行边查询边缓存的操作,打个最简单的比方,假设执行到1000,那么它就要查之前缓存的999有没有缓存过,以我们提供的10W为标准,其实在memoizee中真就执行了10W次indexOf,且越往后面执行查询的代价就越大,耗时这么久自然就好理解了。
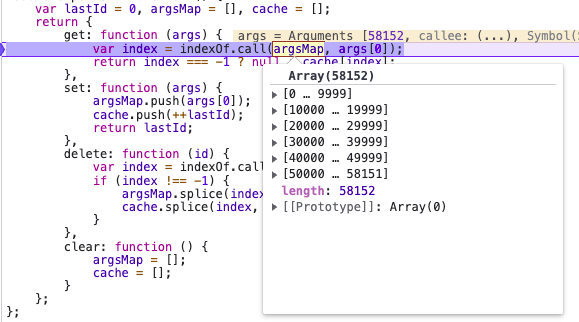
上图就是当参数执行到58152时,需要查之前存的5W多个缓存,你要之后后面还有把这种操作执行4W多次,且缓存还是递增的。
另外,memoizee在一个参数或者多个参数时,get的实现逻辑其实不同,但尴尬的是,不管几个参数,其实都是借用indexOf,下图就是我改为多个参数的代码断点:
get: function (args) {
var index = 0, set = map, i;
while (index < length - 1) {
i = indexOf.call(set[0], args[index]);
if (i === -1) return null;
set = set[1][i];
++index;
}
i = indexOf.call(set[0], args[index]);
if (i === -1) return null;
return set[1][i] || null;
},

叁 ❀ 解决
说到这里,有些同学可能都疑惑了,我使用memoizee本身就是为了提升性能,结果你memoizee自己就有性能问题,那到底用不用?或者说怎么用?
其实我们使用缓存函数本质是为了减少那种特别复杂的逻辑处理,比如上面只是求一个数字的平方的处理就根本没必要使用缓存,不走缓存瞬间快几千倍。
其次,由于memoizee在查询缓存时借用了indexOf,站在量大的数据面前性能问题是无法避免的,而其它同事之所以遇到这个问题,是因为某个客户在项目中对于工作项不同类型定义了多个属性配置,而每个配置下又支持自定义N个工作项属性,在程序经常有根据工作项属性ID去查对应工作项属性的逻辑,所以这一查直接卡爆了。
还记得我们上面三段代码的对比吗?我们自定义的缓存函数之所以快,是因为我们使用的是cache[key],即便你cache存了几十万条数据,通过对象直接读取key的时间复杂度其实是O(1),所以针对项目中的需求,性能优化小组的同学自己定义了一个根据ID查询工作项属性的工具函数:
export const getterCache = (fn) => {
const cache = new Map();
return (...args) => {
const [uuid] = args;
// 这里的时间复杂度是O(1)
let data = cache.get(uuid);
if (data === undefined) {
// 没有缓存
data = fn.apply(this, args); // 执行原函数获取值
cache.set(uuid, data);
}
return data;
};
};
好处就是借用了Map的get方法,相对于indexOf的O(N),脑补一下就知道能快不少了。
重回memoizee,会议结论是,谨慎使用memoizee做函数缓存(不再推荐),若你的函数结果本身就不复杂,那更不要使用了,而对于调用非常庞大的场景,你可能还得手动定义缓存函数,另一点,由于公司react已升到17,所以现在大部分缓存已经使用了useMemo,也暂未发现性能损耗的问题。后续有空再看看useMemo是如何实现的缓存吧,本文到这里结束。
使用memoizee缓存函数提升性能,竟引发了indexOf的性能问题的更多相关文章
- TP5 生成数据库字段 和 路由 缓存来提升性能
关于使用tp5框架如何提升部分性能,框架中很多影响性能的问题在于,很多请求都要重新加载,如果能避免过度加载的问题,就能提升部分性能,所以我们通过缓存来实现这一功能,具体如下. 首先说明 如果是linu ...
- KTL 一个支持C++14编辑公式的K线技术工具平台 - 第四版,稳定支持Qt5编程,zqt5语法升级,MA函数提升性能1000%,更多公式算法的内置优化实现。
K,K线,Candle蜡烛图. T,技术分析,工具平台 L,公式Language语言使用c++14,Lite小巧简易. 项目仓库:https://github.com/bbqz007/KTL 国内仓库 ...
- [NewLife.XCode]实体列表缓存(最土的方法实现百万级性能)
NewLife.XCode是一个有10多年历史的开源数据中间件,支持nfx/netcore,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode. 整个系列教程会大量结合示例代码和 ...
- 深入理解js的变量提升和函数提升
一.变量提升 在ES6之前,JavaScript没有块级作用域(一对花括号{}即为一个块级作用域),只有全局作用域和函数作用域.变量提升即将变量声明提升到它所在作用域的最开始的部分.上个简历的例子如: ...
- JavaScript系列文章:变量提升和函数提升
第一篇文章中提到了变量的提升,所以今天就来介绍一下变量提升和函数提升.这个知识点可谓是老生常谈了,不过其中有些细节方面博主很想借此机会,好好总结一下. 今天主要介绍以下几点: 1. 变量提升 2. 函 ...
- js 变量提升和函数提升原理
关于js的变量,开始的时候我们都会被告知,变量声明应该在引用该变量之前.关于为什么要这样做呢,开始的时候本着会用就行的目的,也没去深究.不过后来经常会发现一些让人很费解的..姑且称为现象吧.先看一段代 ...
- js 函数提升和变量提升
总结: 函数提升比变量提升优先级高! 词法分析 词法分析方法: js运行前有一个类似编译的过程即词法分析,词法分析主要有三个步骤: 分析参数 再分析变量的声明 分析函数说明 具体步骤如下: 函数在运行 ...
- 使用 HTTP 缓存机制提升系统性能
摘要 HTTP缓存机制定义在HTTP协议标准中,被现代浏览器广泛支持,同时也是一个用于提升基于Web的系统性能的广泛使用的工具.本文讨论如何使用HTTP缓存机制提升基于Web的系统,以及如何避免误用. ...
- 一个用于每一天JavaScript示例-使用缓存计算(memoization)为了提高应用程序性能
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content ...
- 写一个根据id字段查找记录的缓存函数(javascript)
前不久在参加面试的时候遇到了这样一道题,"写一个根据id字段查找记录的缓存函数,如果之前查过,则直接返回之前查找过的对象,而无须重新查找".当时由于时间较短加上时间比较紧张,考虑并 ...
随机推荐
- 设备共享分配:虚拟化和 SRIOV
SRIOV 简介 OpenStack 自 Juno 版本开始引入 SRIOV,SRIOV(Single Root I/O Virtualization) 是将 PCIe(PCI) 设备虚拟化成虚拟 P ...
- 深入理解Kafka核心设计及原理(六):Controller选举机制,分区副本leader选举机制,再均衡机制
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/15026824.html 目录: 6.1.Kafka核心总控制器Controller 6.2.Controlle ...
- idea侧边栏commit消失
1.问题 在使用Clion中想要查看提交的相关信息,发现侧边栏commit消失 2.解决方法 打开设置,选择会用非模式提交界面即可
- 2023年度总结,互联网寒冬是躺平OR寻找风口
一.前言 又到了年底,这一年过的真的好快,犹如白驹过隙. 身体快跃过去了,灵魂还没有. 拿起键盘却迟迟无法下手,经过三天终于完成了! 这是很颓很丧的一年,很难看到自己的成长,就像登山卡在半山腰,开车堵 ...
- Android——SQLiteOpenHelper
使用步骤: 新建一个继承自SQLiteOpenHelper的数据库操作类,提示重写onCreate和OnUpgraed两个方法.其中,onCreate方法只在第一次打开数据库时执行,在此可进行表结构创 ...
- Go-数据类型-函数
函数类型 函数声明本质上是定义了函数类型的变量 package main import "fmt" // 定义了函数,本质上是在全局作用域中声明了一个函数类型的变量 info 其类 ...
- springboot封装统一返回
springboot返回统一的标准格式 定义注解 package com.yaoling.annotation; import java.lang.annotation.*; @Target({Ele ...
- [转帖]OutOfMemory JVM参数一览
https://www.cnblogs.com/kuroro/p/11707951.html JVM提供了有用的参数来处理OutOfMemoryError.在本文中,我们要强调那些JVM参数.在对Ou ...
- [转帖]windows10彻底关闭Windows Defender的4种方法
https://zhuanlan.zhihu.com/p/495107049 Windows Defender是windows10系统自带的杀毒软件.默认情况下它处于打开的状态.大多数第三方的杀毒软件 ...
- [转帖]Oracle 性能优化 之 游标及 SQL
https://www.cnblogs.com/augus007/articles/9273236.html 一.游标 我们要先说一下游标这个概念. 从 Oracle 数据库管理员的角度上说,游标是对 ...