php爬虫入门
本篇文章介绍PHP抓取网页内容技术,利用PHP cURL扩展获取网页内容,还可以抓取网页头部,设置cookie,处理302跳转。
一、cURL安装
采用源码安装PHP时,需要在configure时添加配置项,
cd php
./configure --with-curl
安装完毕,可以利用php -m命令查看,是否已经支持cURL扩展。
php -m | grep curl
也可以利用phpinfo查看,是否已经支持cURL扩展。

二、获取网页内容
cURL支持很多网络协议,如HTTP、HTTPS、FTP等。普通网页采用HTTP协议,一些安全性高的网页采用HTTPS(HTTPS协议采用数据加密技术,通过公钥技术交换密钥,加密传输内容。因此采用HTTPS协议的网页,在整个链路上传输的都是加密后的数据。例如Baidu采用HTTPS协议,你输入的关键字被网络传输协议加密,即使是运营商可以获得全部数据,也无法获得数据的内容。HTTPS协议也有缺点,就是加解密需要耗费计算时间,因此HTTPS网站会慢一些,而大多数网站都是采用HTTP协议)。HTTP协议中,定义了两种方法GET和POST。POST方法通常用于表单提交,能够提交文件等大数据。GET方法用来获取网页数据,也可以提交少量数据。本文主要介绍利用GET协议获取网页数据,将来再详细讲解cURL POST技术。
我们先看一些浏览器是怎么工作的,打开chrome浏览器,F12进入开发者模式,将工具栏切换到network,如下图,利用chrome工具可以查看每个文件的传输信息。
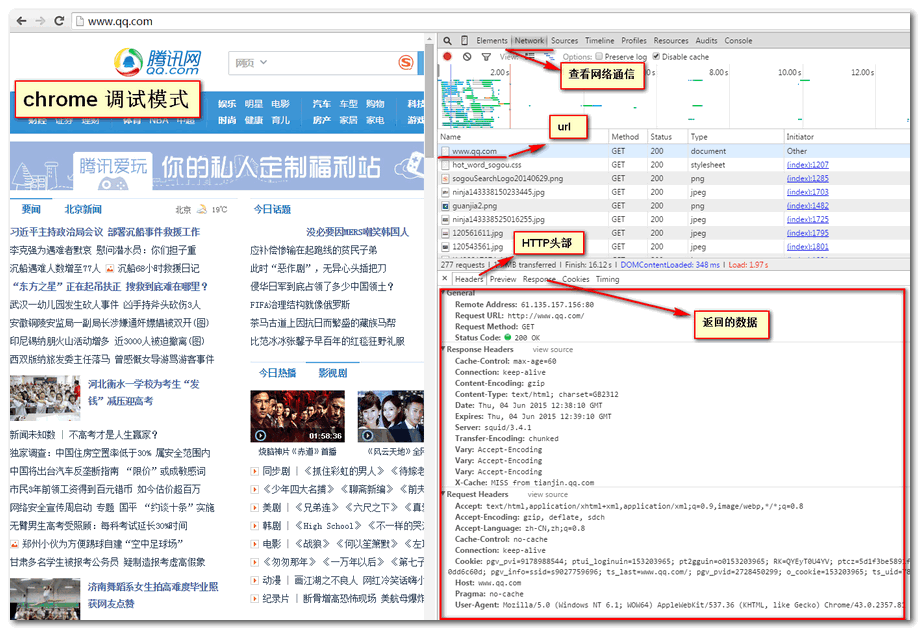
浏览器要加载一个网页,首先下载html文件,再下载js、css、图片等资源文件再进行渲染加载。通常数据抓取只需要抓取html文件,下图是chrome工具显示下载http文件的内容。

三、PHP实现

<?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "www.qq.com");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
$html = curl_exec($ch);
curl_close($ch);
var_dump($html);
?>
基本设置,返回网页内容。
四、获得HTTP头部设置cookie
有些网站,会采用cookie技术。当采集程序没带有相关cookie时,很容易被网站认定是“机器人”,拒绝对其服务。通过chrome调试www.sogou.com,发现cookie是包含在网页头信息中的。因此,我们需要两个步骤(1)HTTP头信息中获取cookie(2)发送请求时添加cookie。
头信息包含设置cookie,
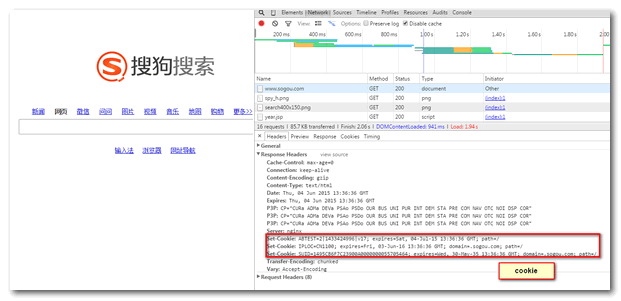
刷新网页,查看头信息,请求包含cookie信息
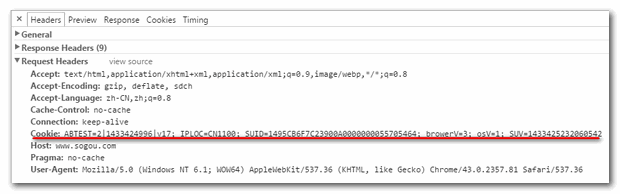
获取cookie
<?php
$url = "www.sogou.com";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_NOBODY, true);
curl_setopt($ch, CURLOPT_HEADERFUNCTION, function ($ch, $str) use(&$setcookie) {
// 第一个参数是curl资源,第二个参数是每一行独立的header!
list ($name, $value) = array_map('trim', explode(':', $str, 2));
$name = strtolower($name);
if('set-cookie'==$name)
{
$setcookie[]=$value;
}
return strlen($str);
});
curl_exec($ch);
curl_close($ch);
$cookie = array();
foreach($setcookie as $c)
{
$tmp = explode(";",$c);
$cookie[] = $tmp[0];
}
$cookiestr = "Cookie:".implode(";", $cookie);
echo $cookiestr;
?>
返回结果
Cookie:ABTEST=0|1433425917|v17;IPLOC=CN1100;SUID=3295CB6F1220920A00000000557057FD
设置cookie
<?php $url = "www.sogou.com"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE); $headers[] = $cookie; curl_setopt($ci, CURLOPT_HTTPHEADER, $headers); $html = curl_exec($ch); curl_close($ch); var_dump($html); ?>
五、抓取302跳转
在Baidu中搜索关键词,返回的结果链接是一个Baidu加密过的链接,通过二次跳转才是真正的网址。(Baidu为了防止360抓取,把结果都加密了)。
我们可以抓取头部中的location信息找到真实地址,
<?php
$url = "https://www.baidu.com/link?url=b34APzBjz-cGLoxsG4-nviHmtVS0tCvEftS6ApCAsojT1a0h9oFFPprwK4JpNYgGaQE29QPUtRdPUeu3lIz2M7GW7dqLMi5ytlHLOVa3v_VY23dOoRiUSyV9zr_cI8Rg&wd=&eqid=c89cf372000002cc0000000255705961&ie=utf-8";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_NOBODY, true);
curl_setopt($ch, CURLOPT_HEADERFUNCTION, function ($ch, $str) use(&$location) {
// 第一个参数是curl资源,第二个参数是每一行独立的header!
list ($name, $value) = array_map('trim', explode(':', $str, 2));
$name = strtolower($name);
if('location'==$name)
{
$location = $value;
return 0;
}
return strlen($str);
});
curl_exec($ch);
curl_close($ch);
echo $location;
?>
抓取302跳转还有另外一种方式,利用ob重定向流的方式,并且设置允许curl跳转到新地址。代码如下
<?php
function getContents($url){
$header = array("Referer: http://www.baidu.com/");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_TIMEOUT, 30);
curl_setopt($ch, CURLOPT_HTTPHEADER,$header);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION,1); //能无法 抓取跳转后的页面
ob_start();
curl_exec($ch);
$contents = ob_get_contents();
ob_end_clean();
curl_close($ch);
return $contents;
}
$url = "https://www.baidu.com/link?url=b34APzBjz-cGLoxsG4-nviHmtVS0tCvEftS6ApCAsojT1a0h9oFFPprwK4JpNYgGaQE29QPUtRdPUeu3lIz2M7GW7dqLMi5ytlHLOVa3v_VY23dOoRiUSyV9zr_cI8Rg&wd=&eqid=c89cf372000002cc0000000255705961&ie=utf-8";
$contents = getContents($url);
echo $contents;
?>
php爬虫入门的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- 爬虫入门系列(二):优雅的HTTP库requests
在系列文章的第一篇中介绍了 HTTP 协议,Python 提供了很多模块来基于 HTTP 协议的网络编程,urllib.urllib2.urllib3.httplib.httplib2,都是和 HTT ...
- 爬虫入门系列(三):用 requests 构建知乎 API
爬虫入门系列目录: 爬虫入门系列(一):快速理解HTTP协议 爬虫入门系列(二):优雅的HTTP库requests 爬虫入门系列(三):用 requests 构建知乎 API 在爬虫系列文章 优雅的H ...
- 【爬虫入门01】我第一只由Reuests和BeautifulSoup4供养的Spider
[爬虫入门01]我第一只由Reuests和BeautifulSoup4供养的Spider 广东职业技术学院 欧浩源 1.引言 网络爬虫可以完成传统搜索引擎不能做的事情,利用爬虫程序在网络上取得数据 ...
- 【网络爬虫入门02】HTTP客户端库Requests的基本原理与基础应用
[网络爬虫入门02]HTTP客户端库Requests的基本原理与基础应用 广东职业技术学院 欧浩源 1.引言 实现网络爬虫的第一步就是要建立网络连接并向服务器或网页等网络资源发起请求.urllib是 ...
- 【爬虫入门手记03】爬虫解析利器beautifulSoup模块的基本应用
[爬虫入门手记03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.Bea ...
- 【网络爬虫入门04】彻底掌握BeautifulSoup的CSS选择器
[网络爬虫入门04]彻底掌握BeautifulSoup的CSS选择器 广东职业技术学院 欧浩源 2017-10-21 1.引言 目前,除了官方文档之外,市面上及网络详细介绍BeautifulSoup ...
随机推荐
- ExtJs5的基本理论概念
概述 理解ExtJs里面的一些基本关键字的概念是使用ExtJs搭建MMVC框架的基础,在ExtJs中,我们通常遇到ExtJs的配置和启动项Ext.application(),该方法是ExtJs程序初始 ...
- Javascript 精简语法介绍
1. 取整同时转成数值型: '10.567890'|0 结果: 10 '10.567890'^0 结果: 10 -2.23456789|0 结果: -2 ~~-2.23456789 结果: -2 2. ...
- SQL反模式学习笔记6 支持可变属性【实体-属性-值】
目标:支持可变属性 反模式:使用泛型属性表.这种设计成为实体-属性-值(EAV),也可叫做开放架构.名-值对. 优点:通过增加一张额外的表,可以有以下好处 (1)表中的列很少: (2)新增属性时,不需 ...
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 牛顿二项式与 e 级数
复习一下数学, 找一下回忆. 先是从二项式平方开始: 其实展开是这样的: 再看立方: 通过排列组合的方式标记, 于是: 通过数学归纳法可以拓展: 使用求和简写可得: e 级数 数学常数 e (The ...
- rsyslog 移植与配置方案介绍
rsyslog介绍 rsyslog是一个 syslogd 的多线程增强版.它提供高性能.极好的安全功能和模块化设计.虽然它基于常规的 syslogd,但 rsyslog 已经演变成了一个强大的工具,可 ...
- Chapter 2 Basic Elements of JAVA
elaborate:详细说明 Data TypesJava categorizes data into different types, and only certain operationscan ...
- Java 多线程 sleep()方法与yield()方法的区别
sleep()方法与yield()方法的区别如下: 1 是否考虑线程的优先级不同 sleep()方法给其他线程运行机会时不考虑线程的优先级,也就是说,它会给低优先级的线程运行的机会.而yield()方 ...
- 小甲鱼Python第二十讲课后习题---021
笔记: 1.lambda表达式的作用: 1)Python写一些执行脚本时,使用lambda就可以省下定义函数的过程,比如说我们只是需要写一个简单的脚本来管理服务器时间,我们就不需要专门定义一个函数然后 ...
- C++调用C语言的库函数
在项目中,使用C语言编写了一个socket后台程序tkcofferd,并且为方便客户端的使用,提供了动态库,其中包含socket接口. 现在的需求是使用qt做一个前端界面,用来展示tkcofferd的 ...