solr&lucene3.6.0源码解析(一)
<properties>
<solr.version>3.6.0</solr.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- SLF4J -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-jdk14</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.geronimo.specs</groupId>
<artifactId>geronimo-stax-api_1.0_spec</artifactId>
<version>1.0.1</version>
</dependency> <dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-core</artifactId>
<version>${solr.version}</version>
</dependency> <dependency>
<groupId>com.***.search</groupId>
<artifactId>IKAnalyzer</artifactId>
<version>2012-u6</version>
</dependency> <dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-dataimporthandler</artifactId>
<version>${solr.version}</version>
</dependency>
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-dataimporthandler-extras</artifactId>
<version>${solr.version}</version>
</dependency> <dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc14</artifactId>
<version>10.2.0.4.0</version>
</dependency> </dependencies>
上面的IKAnalyzer为IK分词器,需要我们手动添加到maven的本地仓库中
然后我们需要解压我们上面下载的${solr-3.6.0}/dist/solr-3.6.0.war文件,将解压的文件复制到我们的web project的WebRoot目录里面
将${solr-3.6.0}/example/resources目录中的log4j.properties文件复制到我们的web project的src目录下
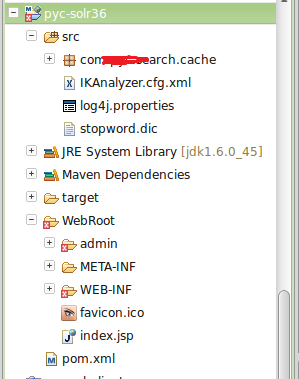
同时IK分词器需要复制相关配置文件到web project的src目录
最后得到的项目结构如下:
下面配置solr.home目录,将${solr-3.6.0}/example/multicore文件夹复制到我们指定的目录,假设为/home/chenying/solr-home
然后修改web project的web.xml文件,指定solr的solr.home
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/home/chenying/solr-home</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
为了使solr支持IK中文分词,我们还需要修改${sole.home}目录中相关core的conf目录中的schemal.xml添加支持IK的fieldType和field
<fieldType name="text_ik" class="solr.TextField" >
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" useSmart ="false"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" useSmart ="false"/>
</analyzer>
</fieldType>
<field name="ik_field" type="text_ik" indexed="true" stored="true" multiValued="false"/>
关于solrconfig.xml文件和schemal.xml文件的详细配置,待后文分解
至此配置完毕,可以在servlet容器(如tomcat)中运行该项目
---------------------------------------------------------------------------
本系列solr&lucene3.6.0源码解析系本人原创
转载请注明出处 博客园 刺猬的温驯
本人邮箱: chenying998179#163.com (#改为@)
本文链接http://www.cnblogs.com/chenying99/p/3440758.html
solr&lucene3.6.0源码解析(一)的更多相关文章
- solr&lucene3.6.0源码解析(四)
本文要描述的是solr的查询插件,该查询插件目的用于生成Lucene的查询Query,类似于查询条件表达式,与solr查询插件相关UML类图如下: 如果我们强行将上面的类图纳入某种设计模式语言的话,本 ...
- solr&lucene3.6.0源码解析(三)
solr索引操作(包括新增 更新 删除 提交 合并等)相关UML图如下 从上面的类图我们可以发现,其中体现了工厂方法模式及责任链模式的运用 UpdateRequestProcessor相当于责任链模式 ...
- solr&lucene3.6.0源码解析(二)
上文描述了solr3.6.0怎么采用maven管理的方式在eclipse中搭建开发环境,在solr中,为了提高搜索性能,采用了缓存机制,这里描述的是LRU缓存,这里用到了 LinkedHashMap类 ...
- Heritrix 3.1.0 源码解析(三十七)
今天有兴趣重新看了一下heritrix3.1.0系统里面的线程池源码,heritrix系统没有采用java的cocurrency包里面的并发框架,而是采用了线程组ThreadGroup类来实现线程池的 ...
- Android事件总线(二)EventBus3.0源码解析
1.构造函数 当我们要调用EventBus的功能时,比如注册或者发送事件,总会调用EventBus.getDefault()来获取EventBus实例: public static EventBus ...
- apache mina2.0源码解析(一)
apache mina是一个基于java nio的网络通信框架,为TCP UDP ARP等协议提供了一致的编程模型:其源码结构展示了优秀的设计案例,可以为我们的编程事业提供参考. 依照惯例,首先搭建a ...
- EventBus3.0源码解析
本文主要介绍EventBus3.0的源码 EventBus是一个Android事件发布/订阅框架,通过解耦发布者和订阅者简化 Android 事件传递. EventBus使用简单,并将事件发布和订阅充 ...
- Retrofit2.0源码解析
欢迎访问我的个人博客 ,原文链接:http://wensibo.net/2017/09/05/retrofit/ ,未经允许不得转载! 今天是九月的第四天了,学校也正式开学,趁着大学最后一年的这大好时 ...
- 【原创】backbone1.1.0源码解析之View
作为MVC框架,M(odel) V(iew) C(ontroler)之间的联系是必不可少的,今天要说的就是View(视图) 通常我们在写逻辑代码也好或者是在ui组件也好,都需要跟dom打交道,我们 ...
随机推荐
- Oracle函数日期转换成秒(时间戳)
SELECT TO_NUMBER(TO_DATE('2015-01-01 05:00:00', 'YYYY-MM-DD HH24:MI:SS') - TO_DATE( * * FROM DUAL; 秒 ...
- Shift Operations on C
The C standard doesn't precisely define which type of right shift should be used. For unsigned data, ...
- C++中的运算符重载练习题
1.RMB类 要求: 定义一个RMB类 Money,包含元.角.分三个数据成员,友元函数重载运算符‘+’(加) 和 ‘-’(减),实现货币的加减运算 例如: 请输入元.角 分: ...
- 随机森林(Random Forest,简称RF)
阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 袋外错误率(oob error) 6 随机森林工作原理解释的一个简单例子 7 随机森林的Pyth ...
- rabbitMQ消息队列1
rabbitmq 消息队列 解耦 异步 优点:解决排队问题 缺点: 不能保证任务被及时的执行 应用场景:去哪儿, 同步 优点:保证任务被及时的执行 缺点:排队问题 大并发 Web nginx 1000 ...
- springboot-shiro chapter02——springboot webmvc jsp
简介:这一节主要涉及spring boot 支持jsp, 由于对spring boot不太熟悉,走了一些弯路. 环境:IDEA15+JDK1.8+Maven3+ 代码: https://git.osc ...
- python操作docx文档(转)
python操作docx文档 关于python操作docx格式文档,我用到了两个python包,一个便是python-docx包,另一个便是python-docx-template;,同时我也用到了很 ...
- FFmpeg库简介
1.FFmpeg基本组成 FFmpeg框架的基本组成包含AVFormat.AVCodec.AVFilter.AVDevice.AVUtils等模块库,如下图所示. libavformat:用于各种音视 ...
- Python格式符说明
格式化输出 例如我想输出 我的名字是xxxx 年龄是xxxx name = "Lucy"age = 17print("我的名字是%s,年龄是%d"%(name, ...
- 【308】Python os.path 模块常用方法
参考:Python os.path 模块 参考:python3中,os.path模块下常用的用法总结 01 abspath 返回一个目录的绝对路径. 02 basename 返回一个目录的基名 ...