《大数据日知录》读书笔记-ch15机器学习:范型与架构
机器学习算法特点:迭代运算
损失函数最小化训练过程中,在巨大参数空间中迭代寻找最优解
比如:主题模型、回归、矩阵分解、SVM、深度学习
分布式机器学习的挑战:
- 网络通信效率
- 不同节点执行速度不同:加快慢任务
- 容错性

机器学习简介:




数据并行vs模型并行:

数据并行

模型并行
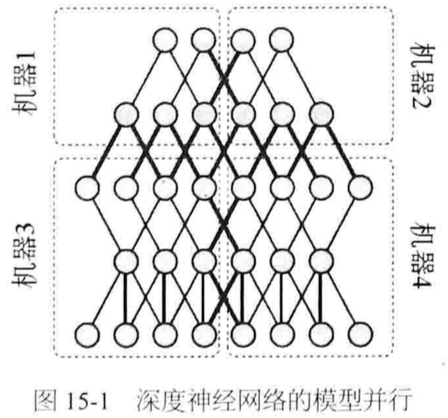
分布式机器学习范型:
其他情形
MPI:容错性差、集群规模小、扩展性低
GPU:目前处理规模中等(6-10GB)
1. 同步范型(严格情形每轮迭代进行数据同步)
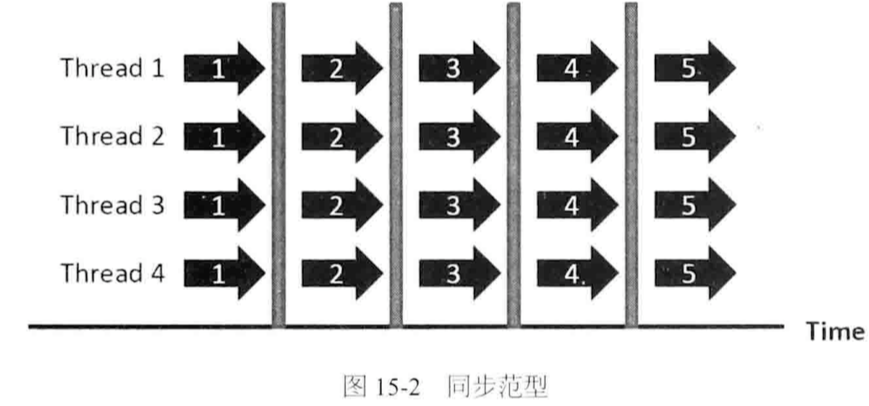
快等慢,计算资源浪费;网络通信多
eg:MapReduce迭代计算、BSP模型属于严格同步范型
2. 异步范型(任意时刻读取更新全局参数)
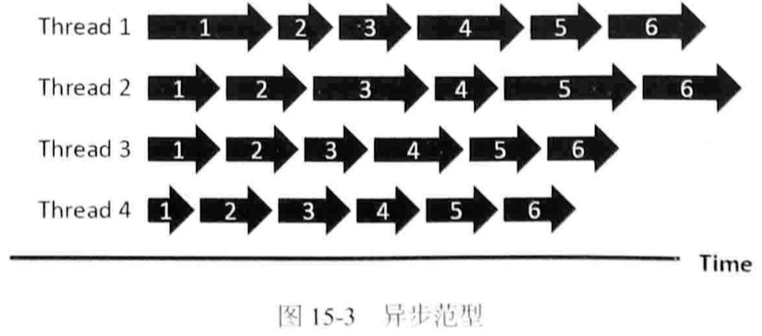
若部分任务迭代严重落后会拉低效果
3. 部分同步范型(主要研究方向)
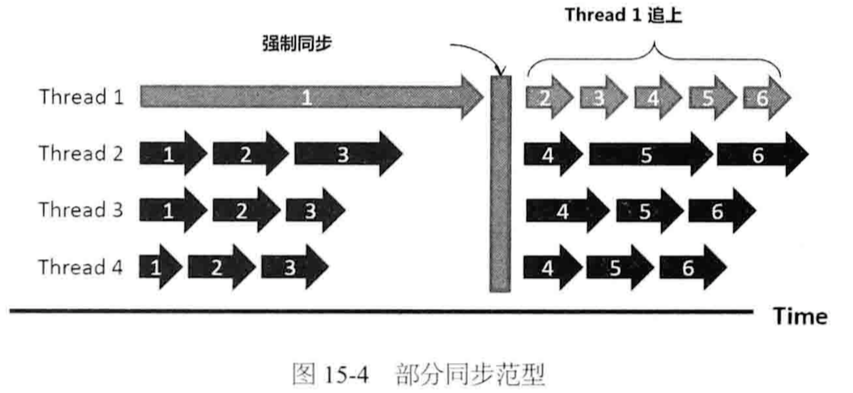
eg:SSP模型
MapReduce迭代计算模型

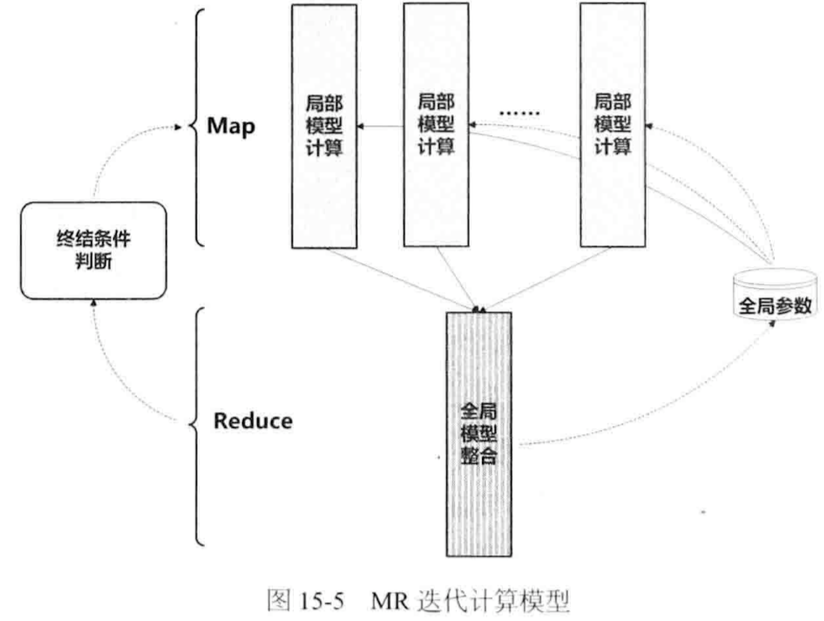

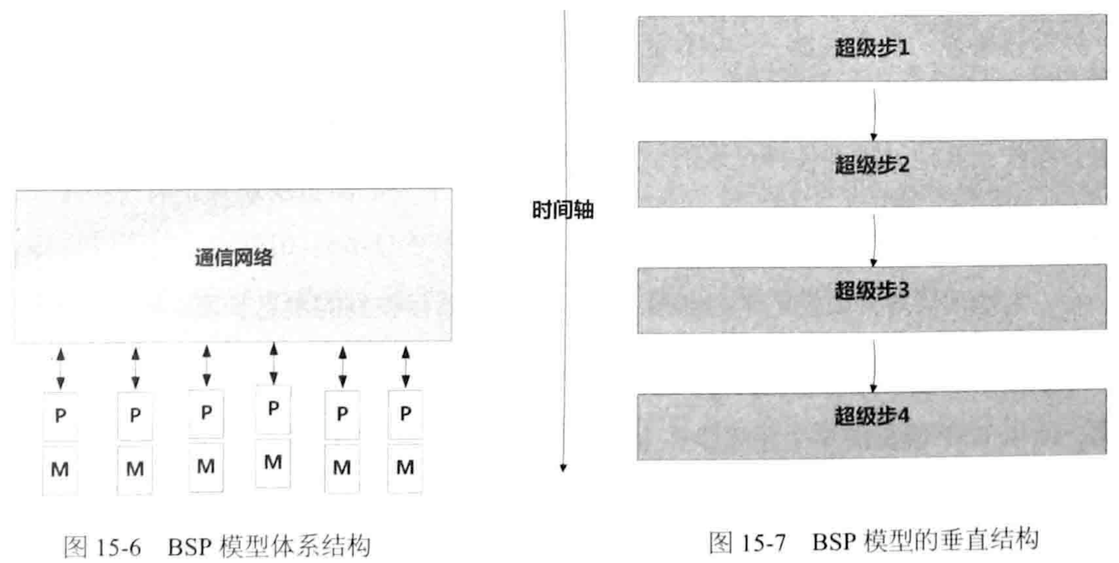
BSP(Bulk Synchronous Parallel)计算模型
“桥接模型”:介于纯硬件、纯编程模式之间的模型
许多相关工作已验证BSP模型的健壮性、性能可预测性和可扩展性

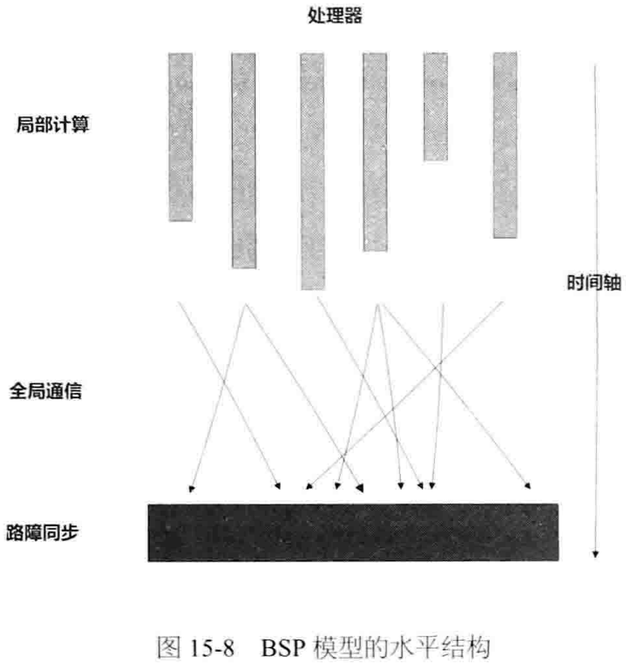
优点:

缺点:
资源利用率低、网络通信多、计算效率低
图计算框架也用BSP:比如Pregel、Giraph
SSP(Stale Synchronous Parallel)计算模型


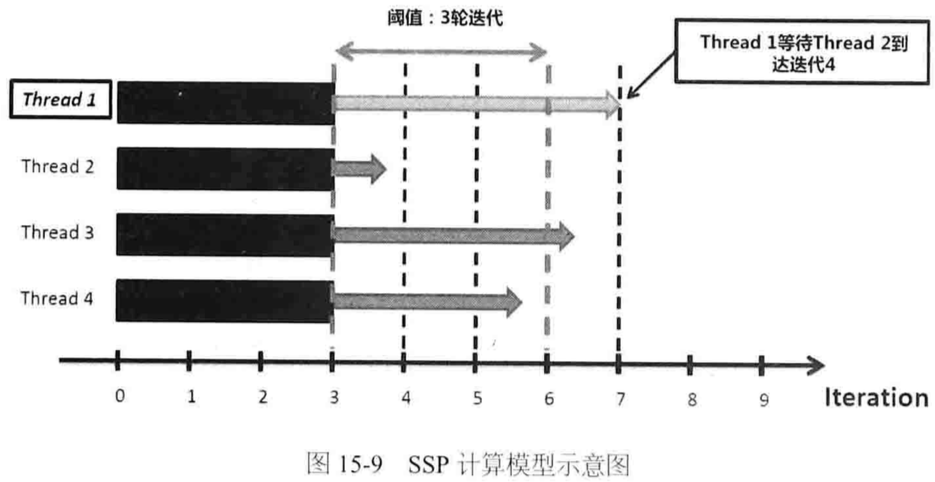
阈值s=0时,SSP退化为BSP同步模型;s=+inf时,SSP演化为完全异步模型
分布式机器学习架构:
MapReduce系列架构:
Cloudera Oryx、Apache Mahout,两者类似。
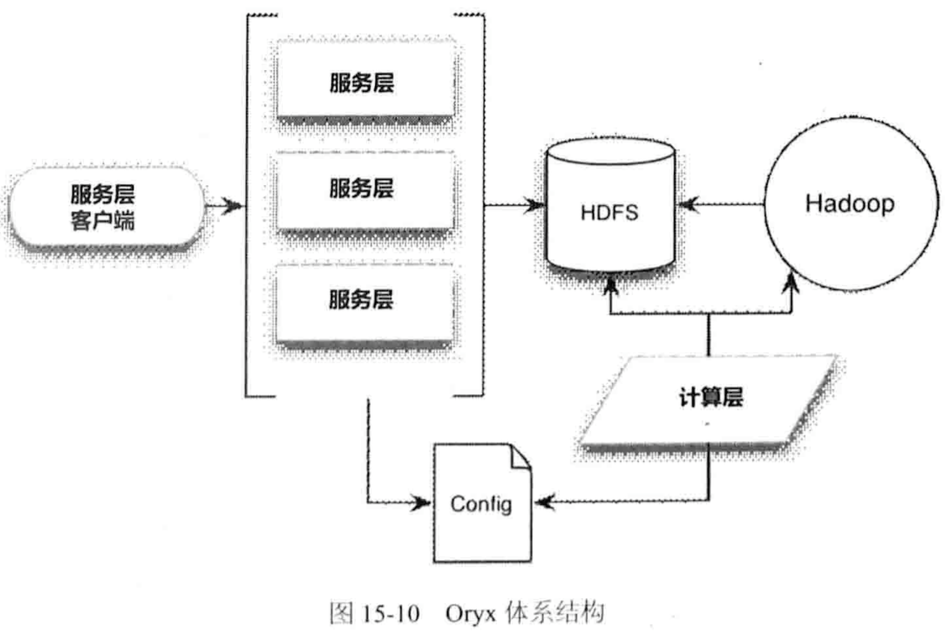
Spark及MLBase:
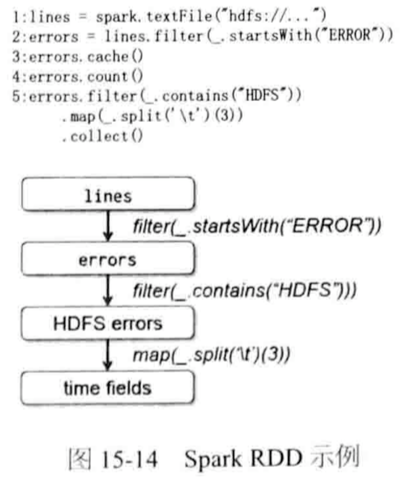
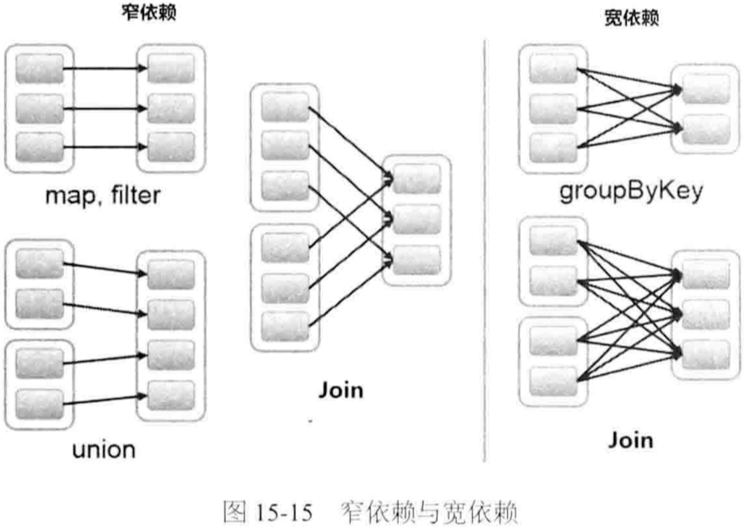
Spark







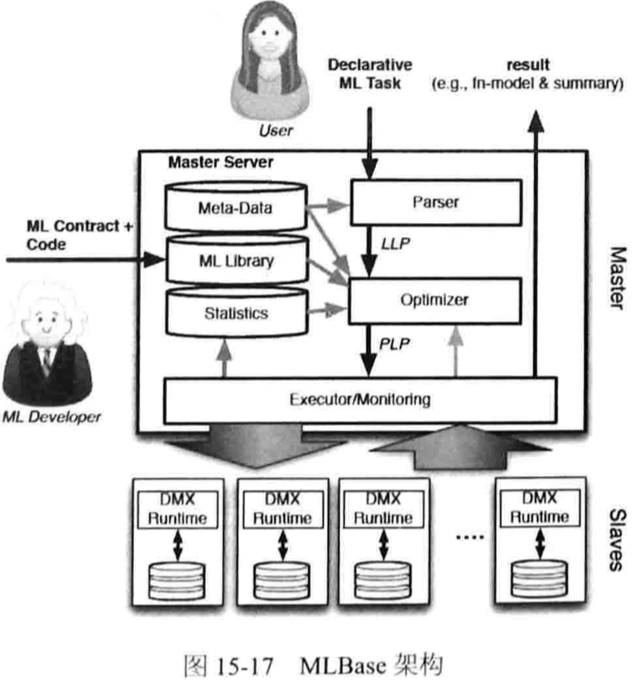
2. MLBase

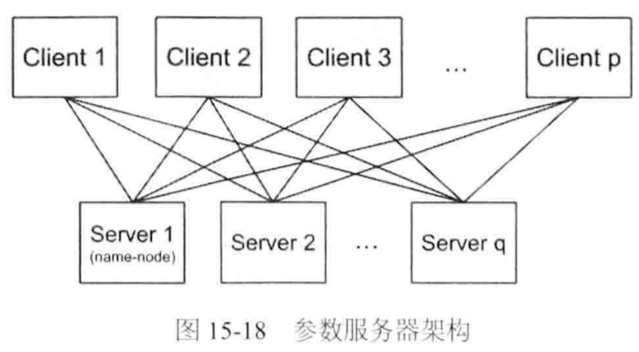
参数服务器(Parameter Server):
比如:Google能处理百亿参数的深度机器学习框架DistBelief
1. 架构

2. 一致性模型
需要设计新型的参数副本一致性均衡正确性和并发度。往往通过受限的异步并行方式(类似于部分同步并行)
1)时钟界异步并行(Clock-bounded Asynchronous Parallel,CAP)

2)值界异步并行(Value-bounded Asynchronous Parallel,VAP)
不考虑时钟值而是参数的更新积累数值。
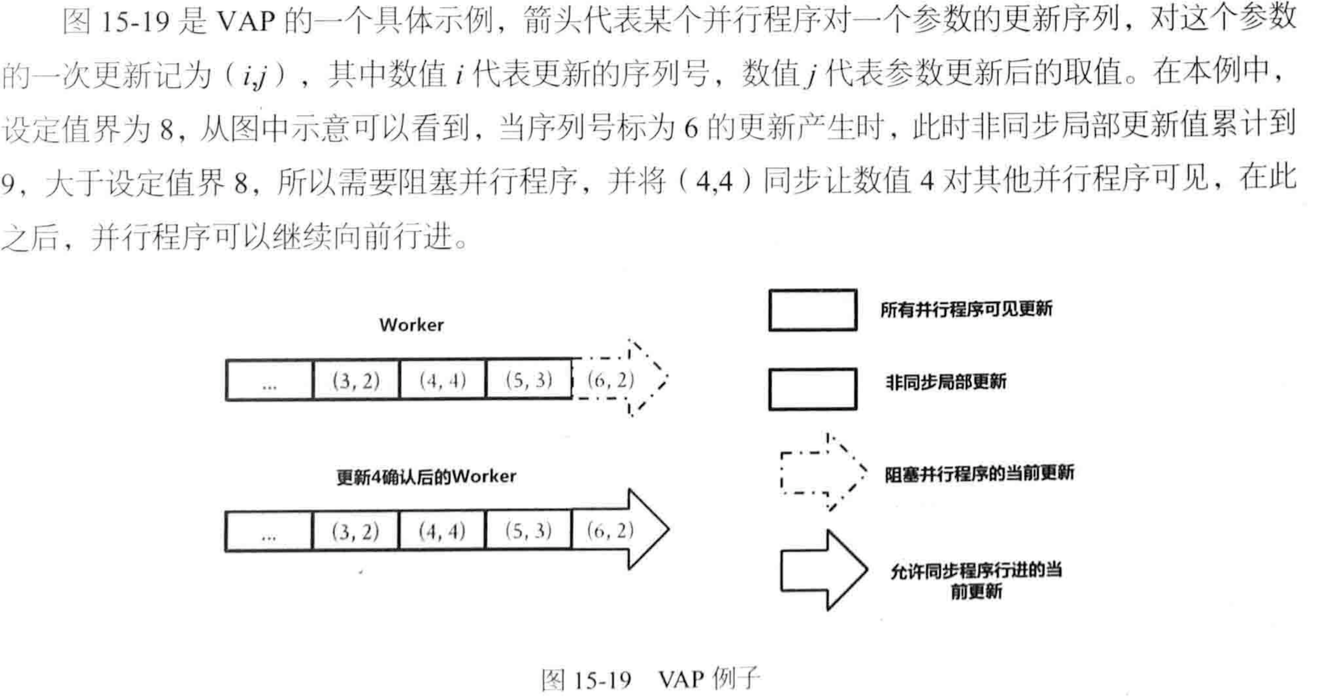
也可以集成CAP和VAP。有理论可以证明:对于随机梯度下降等常见机器学习算法,VAP可以保证算法收敛性。
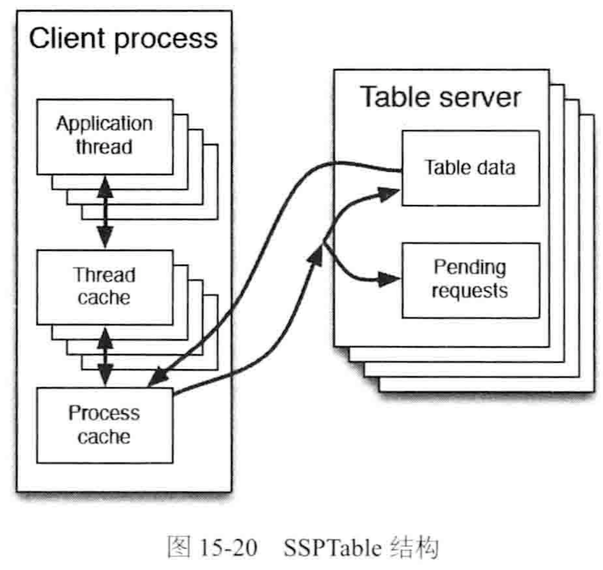
3. SSPTable




《大数据日知录》读书笔记-ch15机器学习:范型与架构的更多相关文章
- 一. 数据分片和路由 <<大数据日知录>> 读书笔记
本章主要讲解大数据下如何做数据分片,所谓分片,即将大量数据分散在不同的节点,同时每个存储节点还要做副本备份. 而一般的抽象分片方法是, 先将数据映射到一个分片空间,这是多对一的关系,即一个数据分片区间 ...
- 二. 大数据常用的算法和数据结构 <<大数据日知录>> 读书笔记
基本上是hash实用的各种举例 布隆过滤器 Bloom Filter 常用来检测某个原色是否是巨量数据集合中的成员,优势是节省空间,不会有漏判(已经存在的数据肯定能够查找到),缺点是有误判(不存在的数 ...
- 读<大数据日知录:架构与算法>有感
前一段时间, 一个老师建议我能够学学 '大数据' 和 '机器学习', 他说这必定是今后的热点, 学会了, 你就是香饽饽.在此之前, 我对大数据, 机器学习并没有非常深的认识, 总觉得它们是那么的缥缈, ...
- 《大数据日知录》读书笔记-ch1数据分片与路由
目前主流大数据存储使用横向扩展(scale out)而非传统数据库纵向扩展(scale up)的方式.因此涉及数据分片.数据路由(routing).数据一致性问题 二级映射关系:key-partiti ...
- 《大数据日知录》读书笔记-ch2数据复制与一致性
CAP理论:Consistency,Availability,Partition tolerance 对于一个分布式数据系统,CAP三要素不可兼得,至多实现其二.要么AP,要么CP,不存在CAP.分布 ...
- 《大数据日知录》读书笔记-ch16机器学习:分布式算法
计算广告:逻辑回归 千次展示收益eCPM(Effective Cost Per Mille) eCPM= CTR * BidPrice 优化算法 训练数据使用:在线学习(online learning ...
- 《大数据日知录》读书笔记-ch11大规模批处理系统
MapReduce: 计算模型: 实例1:单词统计 实例2:链接反转 实例3:页面点击统计 系统架构: 在Map阶段还可以执行可选的Combiner操作,类似于Reduce,但是在Mapper sid ...
- 《大数据日知录》读书笔记-ch3大数据常用的算法与数据结构
布隆过滤器(bloom filter,BF): 二进制向量数据结构,时空效率很好,尤其是空间效率极高.作用:检测某个元素在某个巨量集合中存在. 构造: 查询: 不会发生漏判(false negativ ...
- [转载] leveldb日知录
原文: http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html 对leveldb非常好的一篇学习总结文章 郑重声明:本篇博客是自己学 ...
随机推荐
- Redis与Java的链接Jedis(二)
就像jdbc跟java链接数据库一样 redis跟java链接最好的工具就是Jedis 相关资源下载:https://github.com/xetorthio/jedis 正常建立java项目, 导入 ...
- python切片、列表解析、元组
1.列表解析 test = [x**2 for x in range(1,11)] 2.切片 test1 = ["a","b","c",&q ...
- 说说javap命令
javap定义 javap是 Java class文件分解器,可以反编译(即对javac编译的文件进行反编译),也可以查看java编译器生成的字节码.用于分解class文件. 测试类 public c ...
- Linux下MySQL表名不区分大小写的设置方法
MySQL表名不区分大小写的设置方法 在用centox安装mysql后,把项目的数据库移植了过去,发现一些表的数据查不到,排查了一下问题,最后发现是表名的大小写不一致造成的. mysql在window ...
- Servlet 学习总结-1
JavaWeb应用程序中所有的请求-响应都是由Servlet来完成的.Servlet是Java Web的核心程序,所有的网址(请求-响应)都交给Servlet来处理. Servlet在Web应用中被映 ...
- thinkjs用户请求处理
- [leetcode] 2. Pascal's Triangle II
我是按难度往下刷的,第二道是帕斯卡三角形二.简单易懂,题目如下: Given an index k, return the kth row of the Pascal's triangle. For ...
- Linq特取操作之ElementAt,Single,Last,First源码分析
Linq特取操作之ElementAt,Single,Last,First源码分析 一:linq的特取操作 First/FirstOrDefault, Last/LastOrDefault, Eleme ...
- 【装饰者模式】Decorator Pattern
装饰者模式,这个模式说我一直记忆深刻的模式,因为Java的IO,我以前总觉得Java的IO是一个类爆炸,自从明白了装饰者模式,Java的IO体系让我觉得非常的可爱,我们现在看看什么是装饰者,然后再来看 ...
- scrapy爬虫框架入门实战
博客 https://www.jianshu.com/p/61911e00abd0 项目源码 https://github.com/ppy2790/jianshu/blob/master/jiansh ...