吴裕雄 python 机器学习——聚类
import numpy as np
import matplotlib.pyplot as plt from sklearn.datasets.samples_generator import make_blobs def create_data(centers,num=100,std=0.7):
'''
生成用于聚类的数据集 :param centers: 聚类的中心点组成的数组。如果中心点是二维的,则产生的每个样本都是二维的。
:param num: 样本数
:param std: 每个簇中样本的标准差
:return: 用于聚类的数据集。是一个元组,第一个元素为样本集,第二个元素为样本集的真实簇分类标记
'''
X, labels_true = make_blobs(n_samples=num, centers=centers, cluster_std=std)
return X,labels_true # 用于产生聚类的中心点
centers=[[1,1],[2,2],[1,2],[10,20]]
# 产生用于聚类的数据集
X,labels_true=create_data(centers,1000,0.5)
# X,labels_true = create_data(centers,num=100,std=0.7)
# print(X,labels_true)
print(len(X))
print(len(labels_true))
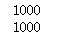
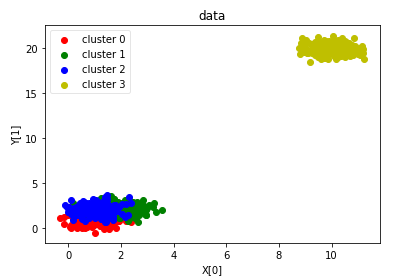
def plot_data(*data):
'''
绘制用于聚类的数据集
'''
X,labels_true=data
labels=np.unique(labels_true)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
# 每个簇的样本标记不同的颜色
colors='rgbyckm'
for i,label in enumerate(labels):
position=labels_true==label
ax.scatter(X[position,0],X[position,1],label="cluster %d"%label,color=colors[i%len(colors)])
ax.legend(loc="best",framealpha=0.5)
ax.set_xlabel("X[0]")
ax.set_ylabel("Y[1]")
ax.set_title("data")
plt.show() plot_data(X,labels_true) # 绘制用于聚类的数据集
吴裕雄 python 机器学习——聚类的更多相关文章
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np import matplotlib.pyplot as plt from sklearn import mixture from sklearn.metrics ...
- 吴裕雄 python 机器学习——层次聚类AgglomerativeClustering模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——回归决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——线性判断分析LinearDiscriminantAnalysis
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——逻辑回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——ElasticNet回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
随机推荐
- Boost::split用法详解
工程中使用boost库:(设定vs2010环境)在Library files加上 D:\boost\boost_1_46_0\bin\vc10\lib在Include files加上 D:\boost ...
- js 获取ur参数 只要问号后面的那段传进url
//获取url中的参数 function getUrlParam (pName, win) { var sUrl; if (typeof (win) == 'string') { sUrl = win ...
- Java设计模式(3)——抽象工厂模式
抽象工厂模式是所有形态的工厂模式中最为抽象和最其一般性的.抽象工厂模式可以向客户端提供一个接口,使得客户端在不必指定产品的具体类型的情况下,能够创建多个产品族的产品对象. 一.产品族和产品等级结构 为 ...
- 用Spring实现文件上传(CommonsMultipartFile)!
2012-02-16 18:10:26| 分类: 计算机--JAVA EE-|字号 订阅 spring中的文件上传实际比较容易1.页面中<html> <body> & ...
- mysql 添加字段,修改字段的用法
1.添加字段 ALTER TABLE 表明 add 字段名称 类型(int,char,VARCHAR...) DEFAULT 默认值 位置(FIRST, AFTER+字段名称); 2.删除 ALTE ...
- java8 Lambda表达式的10个例子(转)
原文:http://jobar.iteye.com/blog/2023477 Java8中Lambda表达式的10个例子 例1 用Lambda表达式实现Runnable接口 Java代码 收藏代码// ...
- Spring框架总结(一)
名词解释: 框架就是组件的集合.比如:Struts.Spring.Hibernate就是组件的集合 组件就是常用的功能包封装成工具类. 常用组件: Dom4j/Xpath.DBUtils.C3p0.B ...
- 引用的一道JAVA题目
code: class A { A() {}} class B extends A { } Which two statements are true? (Choose two) A. Class B ...
- How attach Java source(为eclipseIDE附加资源)
In Eclipse, when you press Ctrl button and click on any Class names, the IDE will take you to the s ...
- Java 栈与堆简介
一.前言 长久以来,一直被Java的内存分配问题,堆和栈问题困扰好久,面试的时候也非常心虚,这几天好好通过看书和技术博客来整理了一下,希望能找到我自己的理解方式. 二.内存 内存分物理内存和虚拟内存, ...