吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import mixture
from sklearn.metrics import adjusted_rand_score
from sklearn.datasets.samples_generator import make_blobs def create_data(centers,num=100,std=0.7):
X, labels_true = make_blobs(n_samples=num, centers=centers, cluster_std=std)
return X,labels_true #混合高斯聚类GMM模型
def test_GMM(*data):
X,labels_true=data
clst=mixture.GaussianMixture()
clst.fit(X)
predicted_labels=clst.predict(X)
print("ARI:%s"% adjusted_rand_score(labels_true,predicted_labels)) # 用于产生聚类的中心点
centers=[[1,1],[2,2],[1,2],[10,20]]
# 产生用于聚类的数据集
X,labels_true=create_data(centers,1000,0.5)
# 调用 test_GMM 函数
test_GMM(X,labels_true)
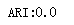
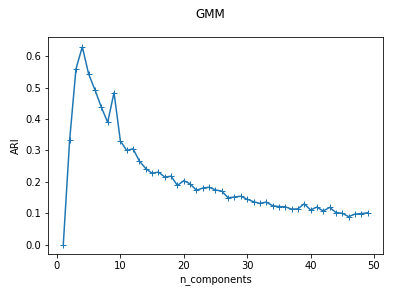
def test_GMM_n_components(*data):
'''
测试 GMM 的聚类结果随 n_components 参数的影响
'''
X,labels_true=data
nums=range(1,50)
ARIs=[]
for num in nums:
clst=mixture.GaussianMixture(n_components=num)
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs.append(adjusted_rand_score(labels_true,predicted_labels))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(nums,ARIs,marker="+")
ax.set_xlabel("n_components")
ax.set_ylabel("ARI")
fig.suptitle("GMM")
plt.show() # 调用 test_GMM_n_components 函数
test_GMM_n_components(X,labels_true)
def test_GMM_cov_type(*data):
'''
测试 GMM 的聚类结果随协方差类型的影响
'''
X,labels_true=data
nums=range(1,50) cov_types=['spherical','tied','diag','full']
markers="+o*s"
fig=plt.figure()
ax=fig.add_subplot(1,1,1) for i ,cov_type in enumerate(cov_types):
ARIs=[]
for num in nums:
clst=mixture.GaussianMixture(n_components=num,covariance_type=cov_type)
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs.append(adjusted_rand_score(labels_true,predicted_labels))
ax.plot(nums,ARIs,marker=markers[i],label="covariance_type:%s"%cov_type) ax.set_xlabel("n_components")
ax.legend(loc="best")
ax.set_ylabel("ARI")
fig.suptitle("GMM")
plt.show() # 调用 test_GMM_cov_type 函数
test_GMM_cov_type(X,labels_true)

吴裕雄 python 机器学习——混合高斯聚类GMM模型的更多相关文章
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——超大规模数据集降维IncrementalPCA模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——数据预处理正则化Normalizer模型
from sklearn.preprocessing import Normalizer #数据预处理正则化Normalizer模型 def test_Normalizer(): X=[[1,2,3, ...
- 吴裕雄 python 机器学习——数据预处理标准化MaxAbsScaler模型
from sklearn.preprocessing import MaxAbsScaler #数据预处理标准化MaxAbsScaler模型 def test_MaxAbsScaler(): X=[[ ...
- 吴裕雄 python 机器学习——数据预处理标准化StandardScaler模型
from sklearn.preprocessing import StandardScaler #数据预处理标准化StandardScaler模型 def test_StandardScaler() ...
- 吴裕雄 python 机器学习——数据预处理标准化MinMaxScaler模型
from sklearn.preprocessing import MinMaxScaler #数据预处理标准化MinMaxScaler模型 def test_MinMaxScaler(): X=[[ ...
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
- 吴裕雄 python 机器学习——数据预处理流水线Pipeline模型
from sklearn.svm import LinearSVC from sklearn.pipeline import Pipeline from sklearn import neighbor ...
随机推荐
- Windows环境下ELK简单搭建记录
前言 ELK已经是一套成熟的日志解决方案,虽然出现了好久,今日才终于研究了一下,不过是在windows平台上安装的. 搭建步骤 下载软件 安装软件 修改配置文件 启动软件 集成测试 下载软件 首先从官 ...
- sort论文和代码解读
流程:1.detections和trackers用匈牙利算法进行匹配 2.把匹配中iou < 0.3的过滤成没匹配上的(1.2步共同返回匹配上的,没匹配上的trackers,没匹配上的detec ...
- 图片背景2X && 3X
图片背景2X && 3X @media (-webkit-min-device-pixel-ratio: 3),(min-device-pixel-ratio: 3){ .share_ ...
- JSP的域对象的作用范围
<%-- Created by IntelliJ IDEA. User: tT丶 Date: 2017-12-12 Time: 14:53 To change this template use ...
- jsp页面运行的步骤以及原理
1.jsp页面在服务器端的执行步骤: 1)将jsp页面翻译成java文件 2)编译 java-class 3)执行返回结果(html页面)给客户端. 2.jsp页面运行的原理: jsp在服务器端运行 ...
- 图形解析理解 css3 之倾斜属性skew()
1.作用 改变元素在页面中的形状2.语法 属性:transform 函数: 1.skew(xdeg) 向横向倾斜指定度数 x取值为正,X轴不动,y轴逆时针倾斜一定角度 x取值为负,X轴不动,y轴顺时针 ...
- Python 多客户端
服务端代码 #引入socketserver模块 import socketserver #定义处理类必须继承BaseRequestHandler类 class my_server(socketserv ...
- Oracle创建表、修改表、删除表、约束条件语法
一. 使用create关键字创建表 --(1)创建新表use 数据库(在那个数据库中建表)create table 表名(字段名1(列名) 数据类型 列的特征,字段名2(列名) 数据类型 列的特征(N ...
- python 面向对象之添加功能
'''**#实现功能**案列 姓名:王飞 年龄:30 性别:男 工龄:5我承诺,我会认真教课.王飞爱玩象棋 姓名:小明 年龄:15 性别:男 学号:00023102我承诺,我会 好好学习.小明爱玩足球 ...
- php中的引用
$var1 = 'zhuchunyu'; $var2 = ""; function foo($vaa){ global $var1,$var2; if (!$vaa){ $var2 ...