Hue的安装与部署
Hue的安装与部署
Hue 简介
Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job等等。很早以前就听说过Hue的便利与强大,一直没能亲自尝试使用,下面先通过官网给出的特性,通过翻译原文简单了解一下Hue所支持的功能特性集合:
默认基于轻量级sqlite数据库管理会话数据,用户认证和授权,可以自定义为MySQL、Postgresql,以及Oracle
基于文件浏览器(File Browser)访问HDFS
基于Hive编辑器来开发和运行Hive查询
支持基于Solr进行搜索的应用,并提供可视化的数据视图,以及仪表板(Dashboard)
支持基于Impala的应用进行交互式查询
支持Spark编辑器和仪表板(Dashboard)
支持Pig编辑器,并能够提交脚本任务
支持Oozie编辑器,可以通过仪表板提交和监控Workflow、Coordinator和Bundle
支持HBase浏览器,能够可视化数据、查询数据、修改HBase表
支持Metastore浏览器,可以访问Hive的元数据,以及HCatalog
支持Job浏览器,能够访问MapReduce Job(MR1/MR2-YARN)
支持Job设计器,能够创建MapReduce/Streaming/Java Job
支持Sqoop 2编辑器和仪表板(Dashboard)
支持ZooKeeper浏览器和编辑器
支持MySql、PostGresql、Sqlite和Oracle数据库查询编辑器
Hue的架构:

hue官网:http://gethue.com/
配置文档:http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/manual.html#_install_hue
源码:https://github.com/cloudera/hue
这里我们直接用下载Hue:http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6.tar.gz
Hue 编译
需要连接互联网
修改虚拟机网络配置安装系统包
yum install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi gcc gcc-c++ krb5-devel libtidy libxml2-devel libxslt-devel openldap-devel python-devel sqlite-devel openssl-devel mysql-devel gmp-devel
在实际安装的时候,sqlite-devel不能从镜像下载,这里我是用了手动下载tar包,安装编译:
下载地址: http://www.sqlite.org/sqlite-autoconf-3070500.tar.gztar zxf sqlite-autoconf-3070500.tar.gz
cd sqlite-autoconf-3070500
./configure
make
sudo make install
编译Hue
tar zxf hue-3.7.0-cdh5.3.6.tar.gz /opt/cdh5/
cd /opt/cdh5/hue-3.7.0-cdh5.3.6/
make apps
配置Hue
secret_key=jFE93j;2[290-eiw.KEiwN2s3['d;/.q[eIW^y#e=+Iei*@Mn<qW5o
# Webserver listens on this address and port
http_host=hadoop
http_port=8888
# Time zone name
time_zone=Asia/Shanghai
启动Hue
${HUE_HOME}/build/env/bin/supervisor
打开hue的浏览器页面:hadoop:8888
Hue与HDFS,YARN集成
Hue与Hadoop集成时,需要配置启动HDFS中的webHDFS,在hdfs-site.xml增加下面配置:
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
此外,还需要配置Hue访问HDFS用户权限,在core-site.xml中配置:
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property> <property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
完成上述配置后,需重启HDFS。
配置Hue
[[hdfs_clusters]]
# HA support by using HttpFs [[[default]]]
fs_defaultfs=hdfs://hadoop:8020 # Directory of the Hadoop configuration
hadoop_conf_dir=/opt/cdh5/hadoop-2.5.0-cdh5.3.6/etc/hadoop # This is the home of your Hadoop HDFS installation.
hadoop_hdfs_home=/opt/cdh5/hadoop-2.5.0-cdh5.3.6 # Use this as the HDFS Hadoop launcher script
hadoop_bin=/opt/cdh5/hadoop-2.5.0-cdh5.3.6/bin # Configuration for YARN (MR2)
# ------------------------------------------------------------------------
[[yarn_clusters]] [[[default]]]
# Enter the host on which you are running the ResourceManager
resourcemanager_host=hadoop # The port where the ResourceManager IPC listens on
resourcemanager_port=8032 # Whether to submit jobs to this cluster
submit_to=True # URL of the ResourceManager API
resourcemanager_api_url=http://hadoop:8088 # URL of the ProxyServer API
proxy_api_url=http://hadoop:8088 # URL of the HistoryServer API
history_server_api_url=http://hadoop:19888
重启Hue服务。这里我们可以通在远程cmd中运行hive,在Hue中查看任务运行状况
Hue与Hive的集成
hive-site.xml:
注:metastore应该作为一个服务起来,然后让客户端去连接这个服务,去读mysql数据库里面的数据,可以参考hive官网上的Administrator Documentation中的Setting Up MetaStore<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
配置完成以后,需启动服务:
nohup {$HIVE_HOME}/bin/hive --service metastore &
nohup {$HIVE_HOME}/bin/hiveserver2 &hue.ini
# Host where HiveServer2 is running.
# If Kerberos security is enabled, use fully-qualified domain name (FQDN).
hive_server_host=hadoop # Port where HiveServer2 Thrift server runs on.
hive_server_port=10000 # Hive configuration directory, where hive-site.xml is located
hive_conf_dir=/opt/cdh5/hive-0.13.1-cdh5.3.6/conf # Timeout in seconds for thrift calls to Hive service
server_conn_timeout=120
注:重新启动hive和hue以后,可能在hue中运行sql时会出现错误,因为权限问题,hue登陆的用户和hdfs上创建表的用户不相同,这个时候需要用hadoop的命令在后台做出更改
bin/hdfs dfs -R o+x /xx
Hue与RDBMS的集成
在hue.ini中配置Hue本身的数据库SQLite
[[[sqlite]]]
# Name to show in the UI.
nice_name=SQLite # For SQLite, name defines the path to the database.
name=/opt/cdh5/hue-3.7.0-cdh5.3.6/desktop/desktop.db # Database backend to use.
engine=sqlite
在hue.ini中配置Mysql数据库
# Name to show in the UI.
nice_name="My SQL DB"
## nice_name=MySqlDB
# For MySQL and PostgreSQL, name is the name of the database.
# For Oracle, Name is instance of the Oracle server. For express edition
# this is 'xe' by default.
## name=db_track # Database backend to use. This can be:
# 1. mysql
# 2. postgresql
# 3. oracle
engine=mysql # IP or hostname of the database to connect to.
host=hadoop # Port the database server is listening to. Defaults are:
# 1. MySQL: 3306
# 2. PostgreSQL: 5432
# 3. Oracle Express Edition: 1521
port=3306 # Username to authenticate with when connecting to the database.
user=root # Password matching the username to authenticate with when
# connecting to the database.
password=123456
重启hue服务,可以在页面中看到配置的数据库了:
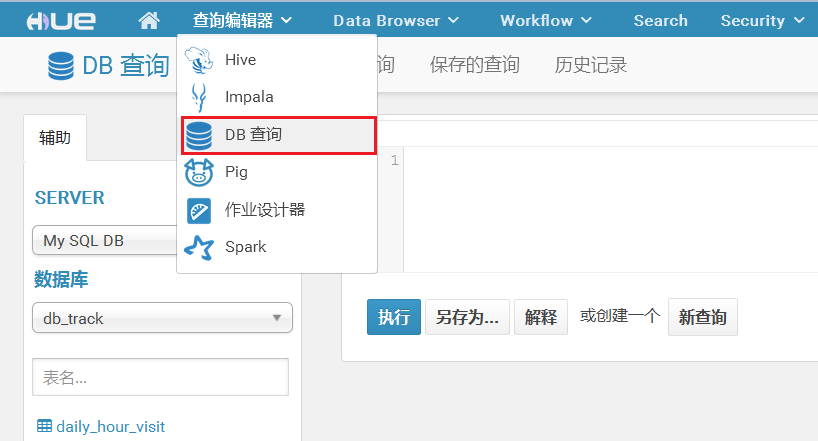

Hue的安装与部署的更多相关文章
- linux下hue的安装与部署
一.Hue 简介 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Djang ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS7安装CDH 第五章:CDH的安装和部署-CDH5.7.0
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- Windows Server 2012 虚拟化实战:SCVMM的安装和部署
本篇大概介绍一下在Windows Server 2012 R2上安装和部署SCVMM的过程及其注意事项.下图是我们数据中心SCVMM的基本架构,其中 SCVMM Database 是用于存储了所有配置 ...
- Linux下Redis的安装和部署
一.Redis介绍 Redis是当前比较热门的NOSQL系统之一,它是一个key-value存储系统.和Memcache类似,但很大程度补偿了Memcache的不足,它支持存储的value类型相对更多 ...
- 他山之石——vs2013 安装与部署及程序打包
C#打包需要这个:InstallShield 2013 Limited Edition for Visual Studio .下载地址: InstallShield 2013 Limited Edi ...
- 阿里云服务器Linux CentOS安装配置(六)resin多端口配置、安装、部署
阿里云服务器Linux CentOS安装配置(六)resin多端口配置.安装.部署 1.下载resin包 http://125.39.66.162/files/2183000003E08525/cau ...
- Kafka的安装和部署及测试
1.简介 大数据分析处理平台包括数据的接入,数据的存储,数据的处理,以及后面的展示或者应用.今天我们连说一下数据的接入,数据的接入目前比较普遍的是采用kafka将前面的数据通过消息的方式,以数据流的形 ...
- Redis的安装与部署
为了解决公司产品数据增长过快,初始化太耗费时间的问题,决定使用redis作为缓存服务器. Windows下的安装与部署: 可以直接参考这个文章,我也是实验了一遍:http://www.runoob.c ...
随机推荐
- Spring的IOC底层实现
IOC的底层实现 续图:
- Keras + Ubuntu环境搭建
安装Theano (环境参数:Ubuntu 16.04.2 Python 2.7) 安装 numpy 和 scipy 1.sudo apt-get install python-numpy pyth ...
- areas表-省市区
不全,缺少台湾省.香港.澳门:新疆重复了 /* Navicat MySQL Data Transfer Source Server : win7_local Source Server Version ...
- mysql ERROR 1264 (22003): Out of range value for column 'x' at row 1 错误
mysql> insert into t1 values (-129), (-128), (127),(128);ERROR 1264 (22003): Out of range value f ...
- python web框架 django 用pycharm 添加django项目
用pycharm 创建django项目 用pycharm 启动django 用项目名启动 点击蓝色连接的url 直接跳转到页面 修改 运行django 程序 设置 可以改端口 可以在创建djang ...
- 007-Shell test 命令,[],[[]]
一.概述 test 命令用于检查某个条件是否成立,它可以进行数值.字符和文件三个方面的测试. 其中[]完全等价于test,只是写法不同.双中括号[[]]基本等价于[],它支持更多的条件表达式,还允许在 ...
- 用仿ActionScript的语法来编写html5——第一篇,显示一张图片
第一篇,显示一张图片 一,代码对比 as代码: public var loader:Loader; public function loadimg():void{ loader = new Loade ...
- 理解tomcat之搭建简易http服务器
做过java web的同学都对tomcat非常熟悉.我们在使用tomcat带来的便利的同时,是否想过tomcat是如何工作的呢?tomcat本质是一个http服务器,本篇文章将搭建一个简单的http服 ...
- 通俗了解IaaS,PaaS,SaaS,看这里就对了(转)
[IT168 评论]云服务已经被大众所熟知,但对于刚接触云计算的朋友来说,仍然是云里雾里的绕着,今天小编就为你解读一下云计算的几种服务模式,IaaS,PaaS,SaaS到底是什么…区别有哪些? 字正腔 ...
- 论MYSQL数据库数据错误的处理
1,备份 2,事务回滚 3,binlog日志回复 4,以上措施都没有,那就望洋兴叹吧