【并行计算】基于OpenMP的并行编程
我们目前的计算机都是基于冯偌伊曼结构的,在MIMD作为主要研究对象的系统中,分为两种类型:共享内存系统和分布式内存系统,之前我们介绍的基于MPI方式的并行计算编程是属于分布式内存系统的方式,现在我们研究一种基于OpenMP的共享内存系统的并行编程方法。OpenMP是一个什么东东?首先我们来看看来之百度百科中的定义:OpenMp是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受的,用于共享内存并行系统的多处理器程序设计的一套指导性的编译处理方案(Compiler Directive)。OpenMP支持的编程语言包括C语言、C++和Fortran;而支持OpenMp的编译器包括Visual studio,Sun Compiler,GNU Compiler和Intel Compiler等。OpenMP功能中最强大的一个功能是:在我们之前串行程序的源码基础上,只要进行少量的改动,就可以并行化许多串行的for循环,达到明显提高性能的效果。
1.OpenMP环境配置与例子
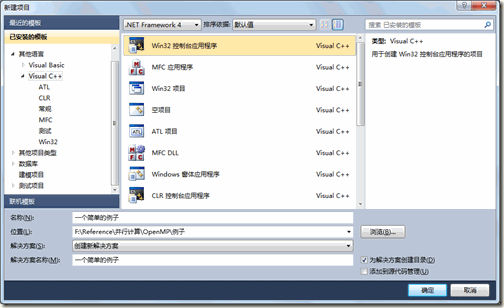
废话不多少,首先上一个例子,由于本文以Vs 2015作为IDE,C++作为开发语言,在正式进行OpenMP编码之前,需要对编译器稍微配置一下。启动VS2015新建一个C++的控制台应用程序,如下图所示:
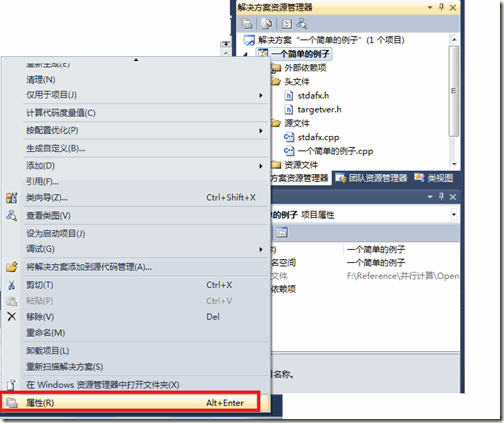
然后在项目解决方案资源管理器上选择项目名称,点击右键,选择“属性”,如下图所示:
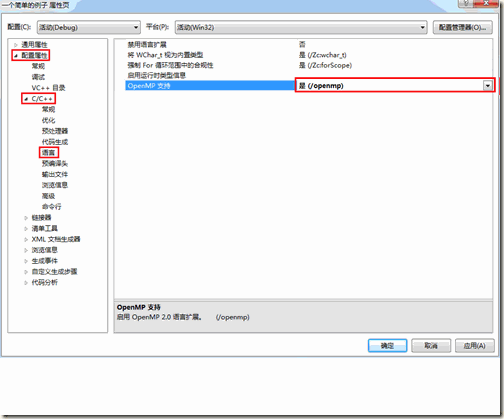
然后在属性页上左侧选择“配置属性”——“C/C++”——“语言”,然后在右侧“OpenMP支持”后选择“是(/openmp)”,如下图所示:
这样就能在我们VS2015中进行OpenMP的程序开发了。将如下串行程序运行一下
//数字累加
void blog4::SumForNumber()
{
int a = 0;
for (int i = 0; i<100000000; i++)
a++;
}
//测试串行程序
void blog4::Test1(int argc, char* argv[])
{
clock_t t1 = clock();
for (int i = 0; i<100; i++)
SumForNumber();
clock_t t2 = clock();
std::cout << "Serial time: " << t2 - t1 << std::endl;
}对上面的串行程序增加一句话:#pragma omp parallel for。变为OpenMP的并行,继续运行。
void blog4::Test2(int argc, char* argv[])
{
clock_t t1 = clock();
#pragma omp parallel for
for (int i = 0; i<100; i++)
SumForNumber();
clock_t t2 = clock();
std::cout << "Parallel time: " << t2 - t1 << std::endl;
}同两次运行时间的对比图如下,可以看出,只要对程序做很少的改动,程序的运行时间就会减少为之前的1/3,性能提升有3倍左右,效果还是蛮好的。
2.基础理论
通过上面的例子,相信大部分同学已经了解了怎么写一个简单的OpenMP的并行计算程序,已经注意到OpenMP的并行计算程序总是以
#pragma omp作为开始的。
在pragma opm后面是一条parallel指令,用来表明之后是一个结构化代码块,最基本的parallel指令可以用如下的形式表示:
#pragma omp parallel如果使用上面这条简单的指令去运行并行计算的话,程序的线程数将由运行时系统决定(这里使用的算法十分复杂),典型的情况下,系统将在每一个核上运行一个线程。如果需要执行使用多少个线程来执行我们的并行程序,就得为parallel指令增加num_threads子句,这样的话,就允许程序员指定执行后代码块的线程数。
#pragma omp parallel num_threads(thread_count)在程序中,为了能够使用OpenMP函数,还需要在程序包含omp.h头文件。
#include <omp.h>在这里,我们还是用之前介绍过的求积分的函数作为例子,

积分函数
//积分函数
double blog4::Trap(double a, double b, int n)
{
double h, x, my_result;
double local_a, local_b;
int i, local_n;
int my_rank = omp_get_thread_num();
int thread_count = omp_get_num_threads(); h = (b - a) / n;
local_n = n / thread_count;
local_a = a + my_rank*local_n*h;
local_b = local_a + local_n*h;
my_result = (f(local_a) + f(local_b)) / 2.0;
for (i = 1; i <= local_n - 1; i++)
{
x = local_a + i*h;
my_result += f(x);
}
my_result = my_result*h; return my_result;
}
数学函数
//数学函数
double blog4::f(double x)
{
return pow(x, 3);
}
OpenMP代码
//第二个案例
void blog4::Test2(int argc, char* argv[])
{
int thread_count = strtol(argv[1], NULL, 10); double global_result = 0.0; #pragma omp parallel num_threads(thread_count)
{
double my_result = 0.0;
my_result = Trap(0, 3, 1024);
#pragma omp critical
global_result += my_result;
} printf("%f\n", global_result);
}
归约
void blog4::Test2(int argc, char* argv[])
{
int thread_count = strtol(argv[1], NULL, 10); double global_result = 0.0; #pragma omp parallel num_threads(thread_count) reduction(+: global_result)
{
global_result += Trap(0, 3, 1024);
} printf("%f\n", global_result);
}
运行:

后面的2指定使用2个线程运行程序。
通过以上的例子,大概知道OpenMP只要添加一条很简单的parallel for指令,就能够并行化大量的for循环所组成的串行程序。但使用它有几天限制条件:
(1)、OpenMP只能并行化for循环,它不会并行while和do-while循环,而且只能并行循环次数在for循环外面就确定了的for循环。
(2)、循环变量只能是整型和指针类型(不能是浮点型)
(3)、循环语句只能是单入口单出口的。循环内部不能改变index,而且里面不能有goto、break、return。但是可以使用continue,因为它并不会减少循环次数。另外exit语句也是可以用的,因为它的能力太大,他一来,程序就结束了。
3.数据依赖问题
使用OpenMP在明面上有上面的这些限制规则,而需要关注的是一个更隐匿的问题:数据依赖问题。这其中涉及两种依赖情况:数据依赖和循环依赖。为了弄清楚这两种依赖的具体是什么,我们先来看一个例子。
计算前n个斐波那契(fibonacci)数:

然后加上OpenMP并行

通过测试,我们有时会得到:
1 1 2 3 5 8 13 21 34 55(正确)
然后也可能偶尔会得到:
1 1 2 3 5 8 0 0 0 0.(错误)
这究竟是发生了什么?似乎运行时,系统将fibo[2], fibo[3], fibo[4], 和 fibo[5]的计算分配给了一个线程,将fibo[6], fibo[7],fibo[8], 和 fibo[9]分配给了另外一个线程。所以在计算fibo[6]的时候,如果第一个线程在此线程之前已经完成,入口初始化为fibo[5]=8,得到的计算结果就是正确的;而如果在计算fibo[6]的时候,如果第一个线程在此线程之前还没有完成,入口初始化为fibo[5]=0,则得到的计算结果就是错误的。
从这里,我们看到两个要点:
(1)OpenMP编译器不检查被parallel for指令并行化的循环所包含的迭代间的依赖关系,而是由程序员来识别这些依赖关系。
(2)一个或更多个迭代结果依赖于其它迭代的循环,一般不能被OpenMP正确的并行化。
从求斐波那契(fibonacci)数的这个例子中,我们发现fibo[3], fibo[4]计算间的依赖关系称之为数据依赖。而fibo[5]的值在一个迭代中计算,它的结果是在之后的迭代中使用,这样的依赖关系称之为循环依赖。
4.怎么寻找循环依赖及解决办法
当我们试图使用一个parallel for指令时,需要小心循环依赖关系,而不用担心数据依赖。例如,在下列循环中:
int i = 0;
for (i = 0; i < n; i++)
{
x[i] = a + i*h;
y[i] = exp(x[i]);
}
在这个程序中y[i]数据依赖于x[i]的,这种依赖使用OpenMP并行化的话,是没有关系的。
在看一个例子,如下公式计算π:
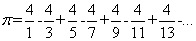
使用能够在串行代码中实现的公式
//第5个案例
void blog4::Test5(int argc, char* argv[])
{
double factor = 1;
double sum = 0.0;
int n = 1000;
for (int i = 0; i < n; i++)
{
sum += factor / (2 * i + 1);
factor = -factor; }
double pi_approx = 4.0*sum;
printf("%f", pi_approx);
}
得到的结果3.140593,符合预期。我们在上面这个段代码中加上OpenMP的并行化指令
//第5个案例
void blog4::Test5(int argc, char* argv[])
{
double factor = 1;
double sum = 0.0;
int n = 1000;
int thread_count = strtol(argv[1], NULL, 10);//omp_get_num_threads();
cout << thread_count << endl;
#pragma omp parallel for num_threads(thread_count) reduction(+:sum)
for (int i = 0; i < n; i++)
{
sum += factor / (2 * i + 1);
factor = -factor;
//cout << i << "-" << factor << endl;
}
double pi_approx = 4.0*sum;
printf("%f", pi_approx);
}
运行程序

得到结果2.730014,不符合预期。这是存在一个循环依赖,不能保证第k次迭代中对factor的更新对第k+1次迭代有影响,所以导致结果不正确。通过分析,对代码进行相应的改动。
if (i % 2 == 0)
factor = 1.0;
else
factor = -1.0;
sum += factor / (2 * i + 1);
运行结果为:2.976587,依旧不正确,为什么呢?
缺省情况下,任何在循环前声明的变量,在线程间都是共享的,。为了消除这种循环依赖关系之外,还需要保证每个线程有它自己的factor副本,OpenMP的语句为我们考虑了,通过添加private子句到parallel指令中来实现这一目标。
//第5个案例
void blog4::Test5(int argc, char* argv[])
{
double factor = 1;
double sum = 0.0;
int n = 1000;
int thread_count = strtol(argv[1], NULL, 10);//omp_get_num_threads();
cout << thread_count << endl;
#pragma omp parallel for num_threads(thread_count) reduction(+:sum) private(factor)
for (int i = 0; i < n; i++)
{
if (i % 2 == 0)
factor = 1.0;
else
factor = -1.0;
sum += factor / (2 * i + 1);
//factor = -factor;
//cout << i << "-" << factor << endl;
//SumForNumber();
}
double pi_approx = 4.0*sum;
printf("%f", pi_approx);
}
这下终于正确了。
【并行计算】基于OpenMP的并行编程的更多相关文章
- C++ OpenMp的并行编程
基于OpenMp的并行编程 功能:并行处理比较耗时的for循环 在OpenMP中,对for循环并行化的任务调度使用schedule子句来实现: 使用格式:schedule(type[,size]) t ...
- 使用openmp进行并行编程
预处理指令pragma 在系统中加入预处理器指令一般是用来允许不是基本c语言规范部分的行为.不支持pragma的编译器会忽略pragma指令提示的那些语句,这样就允许使用pragma的程序在不支持它们 ...
- Python并行编程的几个要点
一.基于线程的并行编程 如何使用Python的线程模块 如何定义一个线程 如何探测一个线程 如何在一个子类中使用线程 Lock和RLock实现线程同步 信号实现线程同步 条件(condition)实现 ...
- C#基础之并行编程
并行编程从业务实现的角度可分为数据并行与任务并行,也就是要解决的问题是以数据为核心还是以要处理的事情为核心.基于任务的并行编程模型TPL(任务并行库)是从业务角度实现的并行模型,它以System.Th ...
- .NET并行编程实践(一:.NET并行计算基本介绍、并行循环使用模式)
阅读目录: 1.开篇介绍 2.NET并行计算基本介绍 3.并行循环使用模式 3.1并行For循环 3.2并行ForEach循环 3.3并行LINQ(PLINQ) 1]开篇介绍 最近这几天在捣鼓并行计算 ...
- OpenMP共享内存并行编程详解
实验平台:win7, VS2010 1. 介绍 平行计算机可以简单分为共享内存和分布式内存,共享内存就是多个核心共享一个内存,目前的PC就是这类(不管是只有一个多核CPU还是可以插多个CPU,它们都有 ...
- OpenMP并行编程
什么是OpenMP?“OpenMP (Open Multi-Processing) is an application programming interface (API) that support ...
- 并行编程OpenMP基础及简单示例
OpenMP基本概念 OpenMP是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C.C++和Fortran.OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的 ...
- OpenMP并行编程应用—加速OpenCV图像拼接算法
OpenMP是一种应用于多处理器程序设计的并行编程处理方案,它提供了对于并行编程的高层抽象.仅仅须要在程序中加入简单的指令,就能够编写高效的并行程序,而不用关心详细的并行实现细节.减少了并行编程的难度 ...
随机推荐
- 个人博客开发-01-nodeJs项目搭建
// window系统下 1.nodeJs 安装 nodeJs 安装 看 这里 , 先下载再下一步下一步就OK了,我的是在C盘里安装的. 安装完以后 按 win + R ,在弹出的小框框里输入 CM ...
- BZOJ4985 评分(二分答案+树形dp)
首先二分答案简化一下问题,现在只有0和1了,要求最后剩下的是1.再简化一下考虑没有已固定的位置怎么做.考虑每个位置由其合并到的位置连边,显然这样形成了一棵三叉树.设f[i]为使得某位置为1其子树至少要 ...
- BZOJ4921 互质序列
即求删掉一个子序列的gcd之和.注意到前后缀gcd的变化次数都是log级的,于是暴力枚举前缀gcd和后缀gcd即可. #include<iostream> #include<cstd ...
- 【转】NHibernate主键类型介绍
转自:http://blog.163.com/wzx_dd/blog/static/1942850722012828934553/ 最近整合了一下框架,用SSH搭建了一个框架,但是在整合好之后,启动t ...
- 【JavaScript】基本类型和引用类型的值、引用类型
一.前言 接着上一篇继续记笔记 二.内容 动态的属性 var person = new Object(); person.name = "Nicholas&qu ...
- 代码收藏系列--javascript--移动端技巧
JS判断是否是手机端访问: var is_mobi = navigator.userAgent.toLowerCase().match(/(ipod|iphone|android|coolpad|mm ...
- 【bzoj4036】按位或
Portal --> bzoj4036 Solution 感觉容斥的东西内容有点qwq多啊qwq还是以题目的形式来慢慢补档好了 这里补的是min-max容斥 其实min-max容斥 ...
- 【BZOJ 1129】[POI2008]Per 二叉堆
这个东西读完题之后,就能知道我们要逐位计算贡献.推一下式子,会发现,这一位的贡献,是当前剩余的数字形成的序列的总数,乘上所剩数字中小于s上这一位的数的个数与所剩数字的总数的比.所以我们维护“当前剩余的 ...
- 洛谷P2398 GCD SUM (数学)
洛谷P2398 GCD SUM 题目描述 for i=1 to n for j=1 to n sum+=gcd(i,j) 给出n求sum. gcd(x,y)表示x,y的最大公约数. 输入输出格式 输入 ...
- advanced bash shell guide读书笔记
http://note.youdao.com/noteshare?id=fc23a679849b4627d131d3ef07c74a71