[深度学习] Contractive Autoencoder
转载于DeepLearning: Contractive Autoencoder - dupuleng - 博客园
一、雅克比矩阵
雅克比矩阵是一阶偏导,假设(x1,x2,....,xn)到(y1,y2,...,ym)的映射,相当于m个n元函数,它的Jacobian Matrix如下
 编辑
编辑
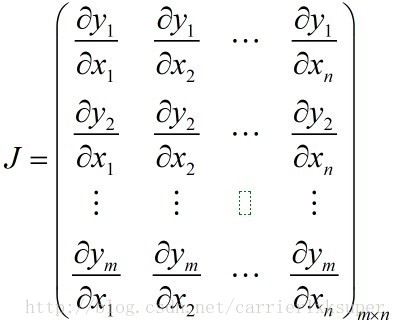
该矩阵表示x的微小波动对y的影响。
雅克比矩阵与Hessian矩阵不同,hessian矩阵表示二阶偏导。
可以用雅克比矩阵表示函数的一阶泰勒展开编辑
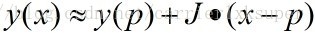
二、Contractive Autoencoder( CAE )
在特征学习中使用雅克比矩阵,CAE的损失函数:

编辑
第一部分原始autoencoder的损失函数,第二部分是F范式下的雅克比矩阵的形式

编辑

编辑
第一部分最小化重构误差,第二部分是让模型具有局部不变性,我们的目标是使偏导尽可能的小,假设极端情况下偏导为0,那么即表示模型对局部的抖动具有鲁棒性。
hogo的解释很有意思,第一部分最小化重构误差,即要在编码的时候将最具代表性的特征信息保留下来,而第二部分只与偏导不为0时的样本有关,即丢掉了所有有用的信息,而保留下抖动信息,我们要使模型对抖动具有不变性。
那么整个损失函数的作用即只保持具有代表性的好特征信息

编辑
从下图可以看出,CAE在编码时,对横坐标的变化要具有不变性,即三个手写体2要具有相同的编码,而对纵轴不需要具有不变性。
因为CAE只考虑样本中出现的情况,不考虑未出现的情况。而denoising autoencoder( DAE)是对输入加入噪声,然后重构未加噪声的样本,
也就是说它要对样本中未出现的测试样本具有鲁棒性。

编辑
三、DAE and CAE
- CAE主要挖掘训练样本内在的特征,它使用的是样本本身的梯度信息,而DAE使用的是加了噪声的样本的梯度信息,不能够完全体现原数据分布,因此CAE的泛化能力比DAE好
- DAE实现比较简单,只需要加几句代码就行,不需要计算隐含层的Jacobian矩阵
- CAE需要使用 使用二阶的优化方法(conjugate gradient, LBFGS等)
特征表示的两个衡量标准
- 重构误差小,很好的重构出原数据 (autoencoder , sparse autoencoder )
- 对抖动具有不变性 ( denoising autoencoder , contractive autoencoder )
参考文献 :
hogo youtube上的视频:https://www.youtube.com/watch?v=79sYlJ8Cvlc
[深度学习] Contractive Autoencoder的更多相关文章
- 深度学习之自编码器AutoEncoder
原文地址:https://blog.csdn.net/marsjhao/article/details/73480859 一.什么是自编码器(Autoencoder) 自动编码器是一种数据的压缩算法, ...
- Deep Learning 1_深度学习UFLDL教程:Sparse Autoencoder练习(斯坦福大学深度学习教程)
1前言 本人写技术博客的目的,其实是感觉好多东西,很长一段时间不动就会忘记了,为了加深学习记忆以及方便以后可能忘记后能很快回忆起自己曾经学过的东西. 首先,在网上找了一些资料,看见介绍说UFLDL很不 ...
- 深度学习Keras框架笔记之AutoEncoder类
深度学习Keras框架笔记之AutoEncoder类使用笔记 keras.layers.core.AutoEncoder(encoder, decoder,output_reconstruction= ...
- 深度学习——无监督,自动编码器——尽管自动编码器与 PCA 很相似,but自动编码器既能表征线性变换,也能表征非线性变换;而 PCA 只能执行线性变换
自动编码器是一种有三层的神经网络:输入层.隐藏层(编码层)和解码层.该网络的目的是重构其输入,使其隐藏层学习到该输入的良好表征. 自动编码器神经网络是一种无监督机器学习算法,其应用了反向传播,可将目标 ...
- SIGAI深度学习第五集 自动编码器
深度学习模型-自动编码器(AE),就是一个神经网络的映射函数,f(x)——>y,把输入的一个原始信号,如图像.声音转换为特征. 大纲: 自动编码器的基本思想 网络结构 损失函数与训练算法 实际使 ...
- Deep Learning 19_深度学习UFLDL教程:Convolutional Neural Network_Exercise(斯坦福大学深度学习教程)
理论知识:Optimization: Stochastic Gradient Descent和Convolutional Neural Network CNN卷积神经网络推导和实现.Deep lear ...
- [译]2016年深度学习的主要进展(译自:The Major Advancements in Deep Learning in 2016)
译自:The Major Advancements in Deep Learning in 2016 建议阅读时间:10分钟 https://tryolabs.com/blog/2016/12/06/ ...
- Deep learning:四十八(Contractive AutoEncoder简单理解)
Contractive autoencoder是autoencoder的一个变种,其实就是在autoencoder上加入了一个规则项,它简称CAE(对应中文翻译为?).通常情况下,对权值进行惩罚后的a ...
- Deep learning:四十(龙星计划2013深度学习课程小总结)
头脑一热,坐几十个小时的硬座北上去天津大学去听了门4天的深度学习课程,课程预先的计划内容见:http://cs.tju.edu.cn/web/courseIntro.html.上课老师为微软研究院的大 ...
- 深度学习中的Data Augmentation方法(转)基于keras
在深度学习中,当数据量不够大时候,常常采用下面4中方法: 1. 人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.也就是Data Augm ...
随机推荐
- Oracle导出和导入
导出 exp exp 用户名/密码@实例名 file=导出的dmp文件存放路径 l og=导出日志存放路径 exp hr/123456@orcl file= C:\Users\Administrato ...
- 个人音乐博客 h5、css和js等
浅说一下吧 这个小项目由h5和css还有js和jq写的 主题内容为个人音乐 博客等 首页一级导航栏 以及侧边栏 整合部分图标(侧边栏未添加收起操作 时间原因 会的朋友们可以自行添加一个动画就可以 在m ...
- 4.httprunner-参数化和数据驱动
前言 参数化在config中使用parameters关键字 httprunner2.x 是在testsuite中实现参数化 httprunner3.x 是在testcase中的config实现参数化 ...
- java中GC的日志认识详解
不同的垃圾回收器 他们的日志都是完成不一样的,看懂日志是解决和发现问题的重中之重. Parallel Scavenge + Parallel Old 日志 启动参数 -XX:+UseParallelG ...
- kubelet忽然不可用
原因,有可能机器的cpu信息有变化(扩容或者缩容)解决办法: 删掉/opt/var/lib/kubelet目录下(或者/data/lib/kubelet)cpu_manager_state文件 然后m ...
- 你给文字描述,AI艺术作画,精美无比!附源码,快来试试!
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 TensorFlow 实战系列:https://www.showmeai ...
- Java:既然有了synchronized,为什么还要提供Lock?
摘要:在Java中提供了synchronized关键字来保证只有一个线程能够访问同步代码块.既然已经提供了synchronized关键字,那为何在Java的SDK包中,还会提供Lock接口呢?这是不是 ...
- 探究Presto SQL引擎(4)-统计计数
作者:vivo互联网用户运营开发团队 - Shuai Guangying 本篇文章介绍了统计计数的基本原理以及Presto的实现思路,精确统计和近似统计的细节及各种优缺点,并给出了统计计数在具体业务 ...
- Android开发 对接微信分享SDK总结
原文:Android开发 对接微信分享SDK总结 - Stars-One的杂货小窝 公司项目需要对接微信分享,本来之前准备对接友盟分享的,但友盟的分享实际参数太多,而我又只需要对接一个微信分享,于是便 ...
- 深入学习SpringBoot
1. 快速上手SpringBoot 1.1 SpringBoot入门程序开发 SpringBoot是由Pivotal团队提供的全新框架,其设计目的是用来简化Spring应用的初始搭建以及开发过程 1. ...