6月16日 Django作业 文件解压缩统计行数
作业要求:
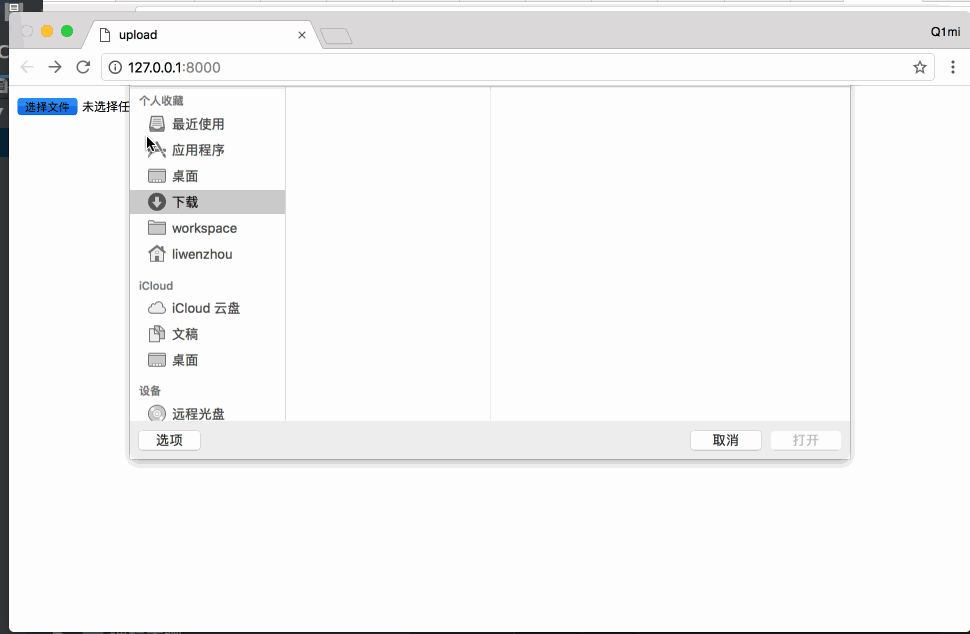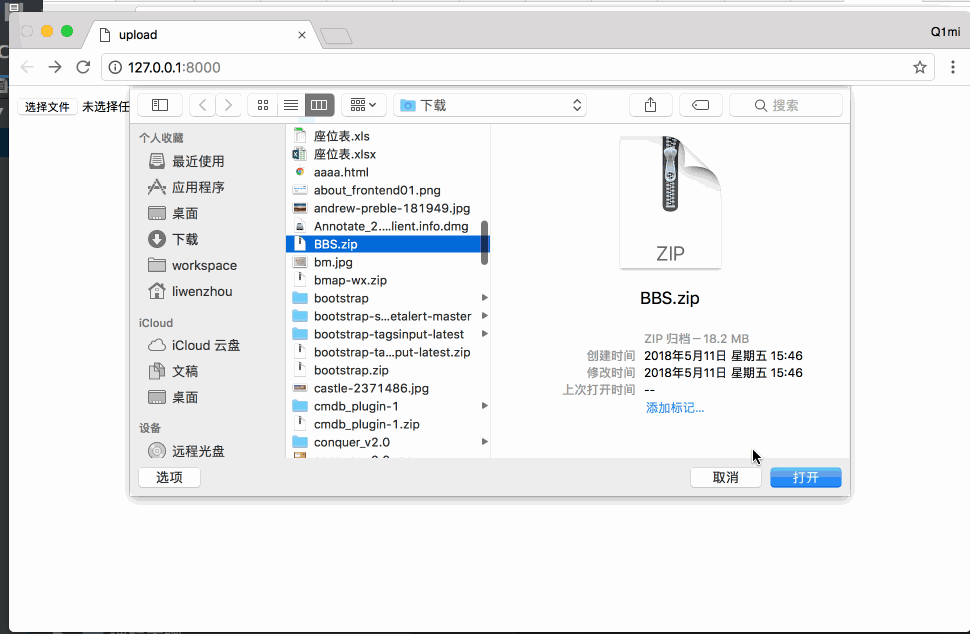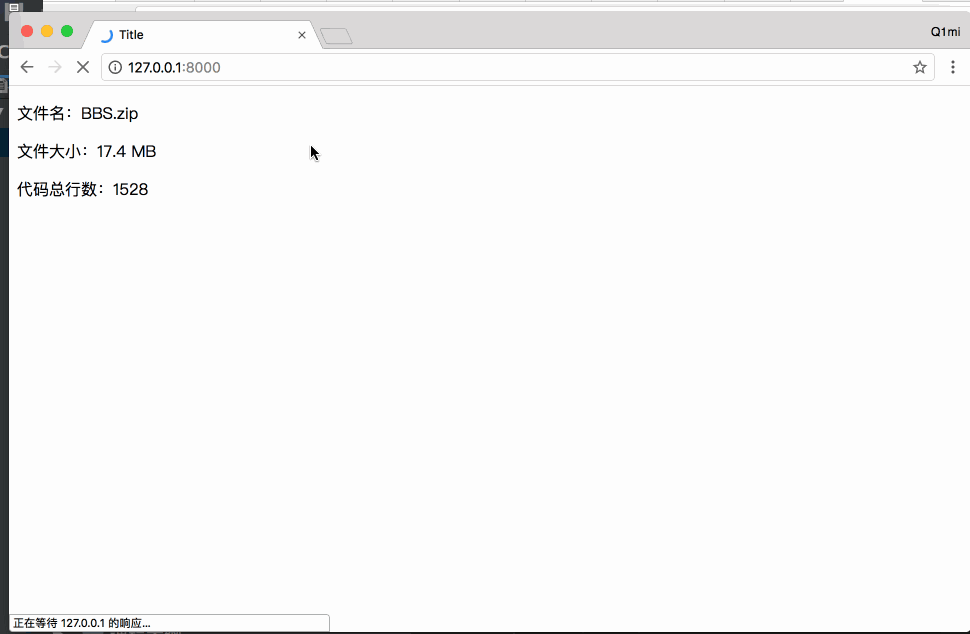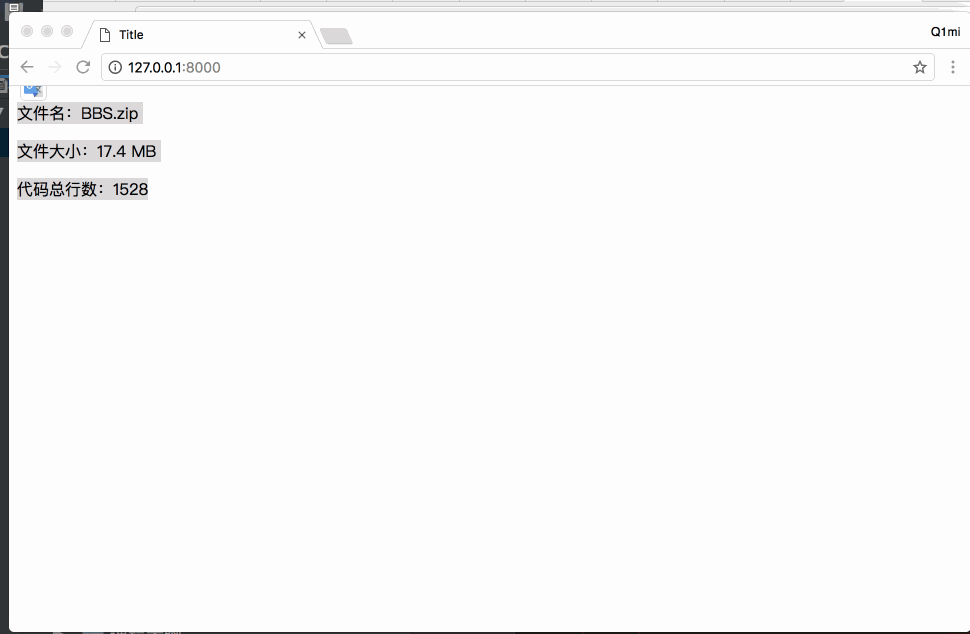
前端页面注意:
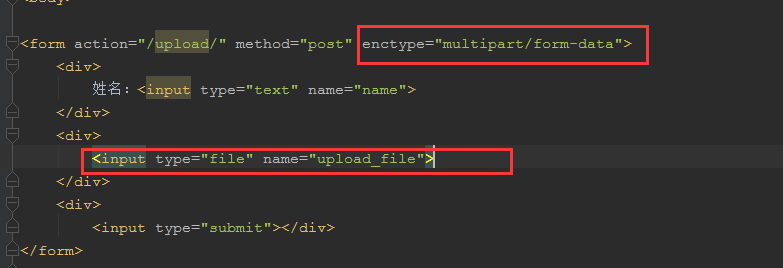
自己写的:
from django.shortcuts import render, HttpResponse
import zipfile
import re # Create your views here. def op_zip(zip_file):
zfile = zipfile.ZipFile(zip_file, 'r') zfile_name_list = zfile.namelist()
# zfile_name_list = list(filter(lambda x: re.findall('\.[a-z]+$', x), zfile_name_list))
# print(zfile_name_list)
# html_files = filter(lambda x: x.endswith('.html'), zfile_name_list)
# py_files = filter(lambda x: x.endswith('.py'), zfile_name_list)
# css_files = filter(lambda x: x.endswith('.css'), zfile_name_list)
# js_files = filter(lambda x: x.endswith('.js'), zfile_name_list) count_file = {'html': 0, 'py': 0, 'css': 0, 'js': 0}
for file_name in zfile.namelist():
# if file_name.endswith('.zip'):
# child_zip_file = zfile.getinfo(file_name)
# print(zipfile.is_zipfile(file_name))
#
# data = zfile.read(file_name)
# print(data)
# res = op_zip(child_zip_file)
# for k in res:
# count_file[k] += res[k] if file_name.endswith('.html'):
data = zfile.read(file_name)
data_list = data.decode('utf8').split('\r\n')
zhu = 0
html_count = 0
for line in data_list:
if line.startswith('//'):
continue
if line.startswith('<!--') or line.startswith('/*'):
zhu += 1
if line.endswith('-->') or line.endswith('*/'):
zhu -= 1
if zhu == 0:
html_count += 1
count_file['html'] += html_count
elif file_name.endswith('.py'):
data = zfile.read(file_name)
data_list = data.decode('utf8').split('\r\n')
zhu = 0
py_count = 0
for line in data_list:
if line.startswith('#'):
continue
if line.startswith("\'\'\'") or line.startswith('\"\"\"'):
zhu += 1
if line.endswith("\'\'\'") or line.endswith('\"\"\"'):
zhu -= 1
if zhu == 0 and line:
py_count += 1
count_file['py'] = py_count
elif file_name.endswith('.css'):
data = zfile.read(file_name)
data_list = data.decode('utf8').split('\r\n')
zhu = 0
css_count = 0
for line in data_list:
if line.startswith('//'):
continue
if line.startswith('/*'):
zhu += 1
if line.endswith('*/'):
zhu -= 1
if zhu == 0:
css_count += 1
count_file['css'] += css_count elif file_name.endswith('.js'):
data = zfile.read(file_name)
data_list = data.decode('utf8').split('\r\n')
zhu = 0
js_count = 0
for line in data_list:
if line.startswith('//'):
continue
if line.startswith('/*'):
zhu += 1
if line.endswith('*/'):
zhu -= 1
if zhu == 0:
js_count += 1
count_file['js'] += js_count
print(count_file)
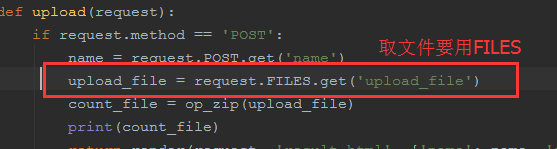
return count_file def upload(request):
if request.method == 'POST':
name = request.POST.get('name')
upload_file = request.FILES.get('upload_file')
count_file = op_zip(upload_file)
print(count_file)
return render(request, 'result.html', {'name': name, 'result': count_file})
return render(request, 'upload.html')
存在的问题:
1、没有考虑到上传文件时,上传的文件类型是否是压缩包
2、只对zip类型的压缩包进行解压
3、忘记了shutil模块
4、过程中遇到的问题:
正则表达式几乎都忘记了,前端界面bootstrap用的也磕磕绊绊的 ,还是缺少练习
老师的答案:
from django.shortcuts import render, HttpResponse
import shutil
import os
import uuid
from django.conf import settings ACCEPT_FILE_TYPE = ["zip", "tar", "gztar", "rar"] # Create your views here. def upload(request):
if request.method == "POST":
# 拿到上传的文件对象
file_obj = request.FILES.get("code_file")
# prefix:前缀 suffix:后缀
# 将上传文件的文件名字 从右边按 '.'切割(最多切一次)
filename, suffix = file_obj.name.rsplit(".", maxsplit=1)
# 如果上传的文件类型不是可接受的,就直接返回错误提示
if suffix not in ACCEPT_FILE_TYPE:
return HttpResponse("上传文件必须是压缩文件")
# 上传文件的类型正确
# 在项目的根目录下新建一个和上传文件同名的文件
with open(file_obj.name, "wb") as f:
# 从上传文件对象一点一点读取数据
for chunk in file_obj.chunks():
# 将数据写入我新建的文件
f.write(chunk)
# 拼接得到上传文件的全路径
real_file_path = os.path.join(settings.BASE_DIR, file_obj.name)
# 对上传的文件做处理
upload_path = os.path.join(settings.BASE_DIR, "files", str(uuid.uuid4()))
# 解压代码文件至指定文件夹
shutil.unpack_archive(real_file_path, extract_dir=upload_path)
# 代码行数统计
total_num = 0
for (dir_path, dir_names, filenames) in os.walk(upload_path):
# dir_path: 根目录 dir_names: 文件夹 filenames: 文件
# 遍历所有的文件
for filename in filenames:
# 将文件名和根目录拼接成完整的路径
file_path = os.path.join(dir_path, filename)
# 完整的路径按照'.' 进行右切割 (最大切割一次)
file_path_list = file_path.rsplit(".", maxsplit=1)
# 文件没有后缀名直接跳过
if len(file_path_list) != 2:
continue
# 如果不是py文件直接跳过
if file_path_list[1] != "py":
continue
# 初始化一个存放当前文件代码行数的变量
line_num = 0
with open(file_path, "r", encoding="utf8") as f:
# 一行一行读取
for line in f:
# 如果是注释就跳过
if line.strip().startswith("#"):
continue
# 否则代码行数+1
line_num += 1
total_num += line_num
return render(
request,
"show.html",
{"file_name": file_obj.name, "file_size": file_obj.size, "total_num": total_num, "value": "张曌"})
return render(request, "upload.html")
6月16日 Django作业 文件解压缩统计行数的更多相关文章
- 20.Nodejs基础知识(上)——2019年12月16日
2019年12月16日18:58:55 2019年10月04日12:20:59 1. nodejs简介 Node.js是一个让JavaScript运行在服务器端的开发平台,它让JavaScript的触 ...
- 16.go语言基础学习(上)——2019年12月16日
2019年12月13日10:35:20 1.介绍 2019年10月31日15:09:03 2.基本语法 2.1 定义变量 2019年10月31日16:12:34 1.函数外必须使用var定义变量 va ...
- 11月16日《奥威Power-BI基于SQL的存储过程及自定义SQL脚本制作报表》腾讯课堂开课啦
上周的课程<奥威Power-BI vs微软Power BI>带同学们全面认识了两个Power-BI的使用情况,同学们已经迫不及待想知道这周的学习内容了吧!这周的课程关键词—— ...
- 2016年12月16日 星期五 --出埃及记 Exodus 21:11
2016年12月16日 星期五 --出埃及记 Exodus 21:11 If he does not provide her with these three things, she is to go ...
- 2016年11月16日 星期三 --出埃及记 Exodus 20:7
2016年11月16日 星期三 --出埃及记 Exodus 20:7 "You shall not misuse the name of the LORD your God, for the ...
- 2016年10月16日 星期日 --出埃及记 Exodus 18:27
2016年10月16日 星期日 --出埃及记 Exodus 18:27 Then Moses sent his father-in-law on his way, and Jethro returne ...
- 12月16日广州.NET俱乐部下午4点爬白云山活动
正如我们在<广州.NET微软技术俱乐部与其他技术群的区别>和<广州.NET微软技术俱乐部每周三五晚周日下午爬白云山活动>里面提到的, 我们会在每周三五晚和周日下午爬白云山. ...
- 9月16日,base 福州,2018MAD技术论坛邀您一起探讨最前沿AR技术!
“ 人工智能新一波浪潮带动了语音.AR等技术的快速发展,随着智能手机和智能设备的普及,人机交互的方式也变得越来越自然. 9月16日,由网龙网络公司.msup联合主办的MAD技术论坛将在福州举行.本次论 ...
- 成都Uber优步司机奖励政策(4月16日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
随机推荐
- nodejs并行无关联
var async = require('async'); //串行无关联series//串行有关联waterfall//并行:parallel //会把各个函数的执行结果一起放到最后的回调中asyn ...
- postman中用当前时间戳做请求的入参
用postman做接口测试的,有些接口需要带上当前时间的时间戳作为请求的入参,postman支持这种功能吗? 答案是肯定的. 文中有使用时间戳的两种方法和postman常用的预定义变量. 例子中接口的 ...
- 《PHP程序员面试笔试真题解析》——新书上线
你好,是我--琉忆.很高兴可以跟你分享我的新书. 很高兴,在出版了PHP程序员面试笔试宝典后迎来了我的第二本书出版--<PHP程序员面试笔试真题解析>. 如果你是一个热爱PHP的程序员,刚 ...
- Typora软件的使用
Typora软件 一.简介 1.该软件编写文档采用markdown格式是目前最为频繁的一种格式 2.该软件生成的文档后缀名是.md结尾 3.下载网址 https://www.typora.io/ 二. ...
- Solution -「洛谷 P4389」付公主的背包
\(\mathcal{Description}\) Link. 容量为 \(n\),\(m\) 种物品的无限背包,求凑出每种容量的方案数,对 \(998244353\) 取模. \(n,m ...
- 手撸一个springsecurity,了解一下security原理
手撸一个springsecurity,了解一下security原理 转载自:www.javaman.cn 手撸一个springsecurity,了解一下security原理 今天手撸一个简易版本的sp ...
- 轻量级DI框架Guice使用详解
背景 在日常写一些小工具或者小项目的时候,有依赖管理和依赖注入的需求,但是Spring(Boot)体系作为DI框架过于重量级,于是需要调研一款微型的DI框架.Guice是Google出品的一款轻量级的 ...
- AFNetworking 修改
相比大家刚刚拿到AFNetworking post 和 get 请求数据的时候都会有些小问题吧 NSLocalizedDescription=Request failed: unacceptabl ...
- Django数据库与模块models(4)
上一节做到把一个应用加入到项目中,现在再往里面加一个数据库就可以与数据库进行交互了. Django默认有一个轻量级的数据库叫SQLite,当我们要更换其他的数据库时,则需要绑定数据库,如何绑定?首先打 ...
- 攻防世界之Web_php_rce
题目: ========================================================================== 解题思路: 1.这题主要考查ThinkPH ...