强化学习-学习笔记9 | Multi-Step-TD-Target
这篇笔记依然属于TD算法的范畴。Multi-Step-TD-Target 是对 TD算法的改进。
9. Multi-Step-TD-Target
9.1 Review Sarsa & Q-Learning
- Sarsa
- 训练 动作价值函数 \(Q_\pi(s,a)\);
- TD Target 是 \(y_t = r_t + \gamma\cdot Q_\pi(s_{t+1},a_{t+1})\)
- Q-Learning
- 训练 最优动作价值函数 Q-star;
- TD Target 是 \(y_t = r_t +\gamma \cdot \mathop{max}\limits_{a} Q^*({s_{t+1}},a)\)
- 注意,两种算法的 TD Target 的 r 部分 都只有一个奖励 \(r_t\)
- 如果用多个奖励,那么 RL 的效果会更好;Multi-Step-TD-Target就是基于这种考虑提出的。
在第一篇强化学习的基础概念篇中,就提到过,agent 会观测到以下这个轨迹:
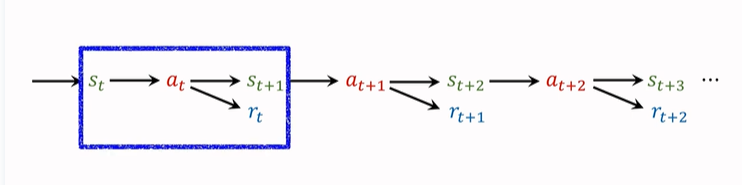
我们之前只使用一个 transition 来记录动作、奖励,并且更新 TD-Target。一个 transition 包括\((s_t,a_t,s_{t+1},r_t)\),只有一个奖励 \(r_t\)。(如上图蓝框所示)。
这样算出来的 TD Target 就是 One Step TD Target。
其实我们也可以一次使用多个 transition 中的奖励,得到的 TD Target 就是 Multi-Step-TD-Target。如下图蓝框选择了两个 transition,同理接下来可以选后两个 transition 。

9.2 多步折扣回报
Multi-Step Return.
折扣回报公式为:\(U_t=R_t+\gamma\cdot{U_{t+1}}\);
这个式子建立了 t 时刻和 t+1 时刻的 U 的关系,为了得到多步折扣回报,我们递归使用这个式子:
\(U_t=R_t+\gamma\cdot{U_{t+1}}\\=R_t+\gamma\cdot(R_{t+1}+\gamma\cdot{U_{t+2}})\\=R_t+\gamma\cdot{R_{t+1}}+\gamma^2\cdot{U_{t+2}}\)
这样,我们就可以包含两个奖励,同理我们可以有三个奖励......递归下去,包含 m个奖励为:
\(U_t=\sum_{i=0}^{m-1}\gamma^i\cdot{R_{t+i}}+\gamma^m\cdot{U_{t+m}}\)
即:回报 \(U_t\) 等于 m 个奖励的加权和,再加上 \(\gamma^m\cdot{U_{t+m}}\),后面这一项称为 多步回报。
现在我们推出了 多步的 \(U_t\) 的公式,进一步可以推出 多步 \(y_t\) 的公式,即分别对等式两侧求期望,使随机变量具体化:
Sarsa 的 m-step TD target:
\(y_t=∑_{i=0}^{m−1}\gamma^i\cdot r_{t+i}+\gamma^m\cdot{Q_\pi}(s_{t+m},a_{t+m})\)
注意:m=1 时,就是之前我们熟知的标准 TD Target。
多步的 TD Target 效果要比 单步 好。
Q-Learning 的 m-step TD target:
\(y_t = \sum_{i=0}^{m-1}\gamma^i{r_{t+i}}+\gamma^m\cdot\mathop{max}\limits_{a} Q^*({s_{t+m}},a)\)
同样,m=1时,就是之前的TD Target。
9.3 单步 与 多步 的对比
单步 TD Target 中,只使用一个奖励 \(r_t\);
如果用多步TD Target,则会使用多个奖励:\(r_t,r_{t+1},...,r_{t+m-1}\)
联想一下第二篇 价值学习 的旅途的例子,如果真实走过的路程占比越高,不考虑 “成本” 的情况下,对于旅程花费时间的估计可靠性会更高。
m 是一个超参数,需要手动调整,如果调的合适,效果会好很多。
x. 参考教程
- 视频课程:深度强化学习(全)_哔哩哔哩_bilibili
- 视频原地址:https://www.youtube.com/user/wsszju
- 课件地址:https://github.com/wangshusen/DeepLearning
强化学习-学习笔记9 | Multi-Step-TD-Target的更多相关文章
- 强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning)
强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning) 学习笔记: Reinforcement Learning: An Introductio ...
- 强化学习读书笔记 - 09 - on-policy预测的近似方法
强化学习读书笔记 - 09 - on-policy预测的近似方法 参照 Reinforcement Learning: An Introduction, Richard S. Sutton and A ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces)
强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces) 学习笔记: Reinforcement Learning: An Introduction, Richard S. S ...
- 强化学习读书笔记 - 10 - on-policy控制的近似方法
强化学习读书笔记 - 10 - on-policy控制的近似方法 学习笔记: Reinforcement Learning: An Introduction, Richard S. Sutton an ...
- 强化学习-学习笔记4 | Actor-Critic
Actor-Critic 是价值学习和策略学习的结合.Actor 是策略网络,用来控制agent运动,可以看做是运动员.Critic 是价值网络,用来给动作打分,像是裁判. 4. Actor-Crit ...
- 强化学习-学习笔记8 | Q-learning
上一篇笔记认识了Sarsa,可以用来训练动作价值函数\(Q_\pi\):本篇来学习Q-Learning,这是另一种 TD 算法,用来学习 最优动作价值函数 Q-star,这就是之前价值学习中用来训练 ...
- 强化学习-学习笔记14 | 策略梯度中的 Baseline
本篇笔记记录学习在 策略学习 中使用 Baseline,这样可以降低方差,让收敛更快. 14. 策略学习中的 Baseline 14.1 Baseline 推导 在策略学习中,我们使用策略网络 \(\ ...
随机推荐
- Metalama简介4.使用Fabric操作项目或命名空间
使用基于Roslyn的编译时AOP框架来解决.NET项目的代码复用问题 Metalama简介1. 不止是一个.NET跨平台的编译时AOP框架 Metalama简介2.利用Aspect在编译时进行消除重 ...
- [操作系统]LINUX进程状态说明
R(task_running) : 可执行状态 只有在该状态的进程才可能在CPU上运行.而同一时刻可能有多个进程 处于可执行状态,这些进程的task_struct结构(进程控制块)被放入对应CPU的 ...
- QtWebEngine性能问题
目录 1. 概述 2. 详论 2.1. 图形属性设置 2.2. 硬件加速设置 2.3. Qt6 3. 参考 1. 概述 Qt的Qt WebEngine模块是基于Chromium项目,但是本人在使用QW ...
- 【Hadoop】10、Flume组件
目录 Flume组件安装配置 1.下载和解压 Flume 2.Flume 组件部署 3.使用 Flume 发送和接受信息 Flume组件安装配置 1.下载和解压 Flume # 传Flume安装包 [ ...
- ajax 请求登录超时跳转登录页解决方法
在Filter里判断是否登录,如果未登录返回401状态 public class SelfOnlyAttribute : ActionFilterAttribute { public override ...
- 谈谈最近玩的设计软件:Figma 与 Sketch
谈谈最近玩的设计软件:Figma 与 Sketch 本文写于 2020 年 5 月 9 日 作为一个优秀的开发者,不懂设计是绝对不行的! 毕竟不懂设计的程序员不是好老板. 而做设计,早已不是尺规作图的 ...
- 是时候使用 YAML 来做配置或数据文件了
概述 我们做程序,经常需要用到配置信息,回顾一下这么多年的搬砖生涯,我记得用过多种格式的文件来定义配置信息,例如 ini文件,xml文件,或者现在比较流行的 json 文件. 这些年虽然云计算和云原生 ...
- mybatis plus 更新字段的时候设置为 null 后不生效
mybatis plus 将属性设置为 null 值会被忽略,最终生成的 sql 中不会有 set field = null(可能是某些情况) mybatis-plus 更新字段的时候设置为 null ...
- 【多线程】线程礼让 Thread.yield()
线程礼让 Thread.yield() 礼让线程,让当前正在执行的线程暂停,但不阻塞 : 将线程从运行状态转为就绪状态 : 让cpu重新调度,礼让不一定成功!看CPU心情. 代码示例: /** * @ ...
- VS.NET启动显示ID为XXXX的进程当前未运行
解决办法:在启动项目根目录下用文本编辑器打开Web项目下的{X}.csproj文件,然后查找 <WebProjectProperties>,将这一对标签之间的内容全部删除,然后再打开项目就 ...