kafka从入门到了解
kafka从入门到了解
一、什么是kafka
Apache Kafka是Apache软件基金会的开源的流处理平台,该平台提供了消息的订阅与发布的消息队列,一般用作系统间解耦、异步通信、削峰填谷等作用。同时Kafka又提供了Kafka streaming插件包实现了实时在线流处理。相比较一些专业的流处理框架不同,Kafka Streaming计算是运行在应用端,具有简单、入门要求低、部署方便等优点。
二、kafka的架构
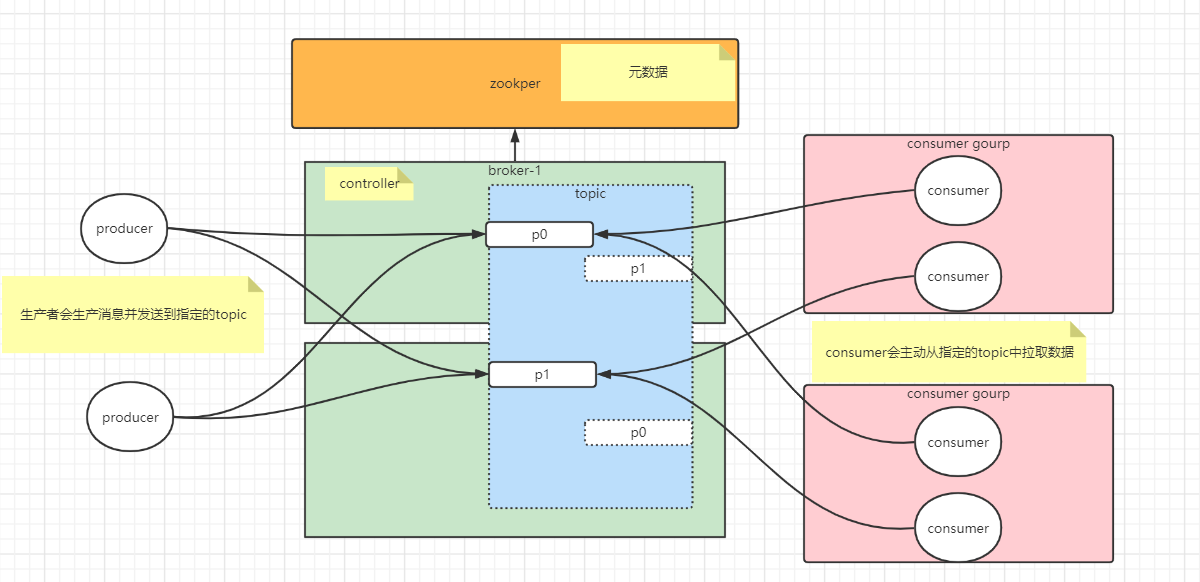
Kafka集群以Topic形式负责分类集群中的Record,每一个Record属于一个Topic。每个Topic底层都会对应一组分区的日志用于持久化Topic中的Record。同时在Kafka集群中,Topic的每一个日志的分区都一定会有1个Borker担当该分区的Leader,其他的Broker担当该分区的follower,Leader负责分区数据的读写操作,follower负责同步改分区的数据。这样如果分区的Leader宕机,该分区的其他follower会选取出新的leader继续负责该分区数据的读写。其中集群的中Leader的监控和Topic的部分元数据是存储在Zookeeper中.
三、kafka的API
kafka的详细安装请参考官网:http://kafka.apache.org/documentation/#quickstart;
1.topic的创建
创建一个test的topic,有三个分区,三个副本。
[root@node01 bin]# kafka-topics.sh
--zookeeper node2:2181,node3:2181/kafka
--create
--topic test
--partitions 3
--replication-factor 3
2.查看topic的列表
[root@node01 bin]# kafka-topics.sh
--zookeeper node2:2181,node3:2181/kafka
--list
3.查看一个topic的详细信息
[root@node01 bin]# ./bin/kafka-topics.sh
--zookeeper node2:2181,node3:2181/kafka
--describe
--topic test
4.修改topic
[root@node01 kafka_2.11-2.2.0]# ./bin/kafka-topics.sh
--zookeeper node2:2181,node3:2181/kafka
--alter
--topic test
--partitions 2
5.删除topic
[root@node01 bin]# kafka-topics.sh
--zookeeper node2:2181,node3:2181/kafka
--delete
--topic test
6.producer往一个topic中生产消息
[root@node01 bin]# kafka-console-producer.sh
--broker-list node01:9092,node01:9092,node01:9092
--topic test
7.consumer订阅一个topic消费消息
[root@node01 bin]# kafka-console-consumer.sh
--bootstrap-server node01:9092,node01:9092,node01:9092
--topic test
--group opentest
8.查看消费组信息
[root@node01 bin]# kafka-console-consumer.sh
--bootstrap-server node01:9092,node01:9092,node01:9092
--list
9.查看某一消费组的详细信息
[root@node01 bin]# kafka-console-consumer.sh
--bootstrap-server node01:9092,node01:9092,node01:9092
--describe
--group opentest
四、kafka在程序中的使用
1.导入对应的jar包
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>2.1.0</version>
</dependency>
2.生产者的代码
@Test
public void producer() throws ExecutionException, InterruptedException {
String topic = "items";
Properties p = new Properties();
p.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node02:9092,node03:9092,node01:9092");
p.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
p.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
p.setProperty(ProducerConfig.ACKS_CONFIG, "-1");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(p);
while(true){
for (int i = 0; i < 3; i++) {
for (int j = 0; j <3; j++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "item"+j,"val" + i);
Future<RecordMetadata> send = producer
.send(record);
RecordMetadata rm = send.get();
int partition = rm.partition();
long offset = rm.offset();
System.out.println("key: "+ record.key()+" val: "+record.value()+" partition: "+partition + " offset: "+offset);
}
}
}
}
3.消费者代码
@Test
public void consumer(){
Properties p = new Properties();
p.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node02:9092,node03:9092,node01:9092");
p.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
p.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
p.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"opentest");
p.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");//
p.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");//自动提交
// p.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"15000");//默认5秒
// p.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,""); //拉取数据的配置
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(p);
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(0));//
if(!records.isEmpty()){
Iterator<ConsumerRecord<String, String>> iter = records.iterator();
while(iter.hasNext()){
ConsumerRecord<String, String> record = iter.next();
int partition = record.partition();
long offset = record.offset();
String key = record.key();
String value = record.value();
System.out.println("key: "+ record.key()+" val: "+ record.value()+ " partition: "+partition + " offset: "+ offset);
}
}
}
}
五、kafka的原理深入
1.kafka的AKF
kafka的高可用性在于可以搭建集群,保证单点故障问题,尤其注意kafka是采用主备模式,leader负责数据读写,flower负责数据同步,它牺牲了读写分离的特性,采用主备模式保证数据的一致性以及系统的可用性。topic可以按照不同业务,创建不同的topic在业务上进行区分。kafka还有分区,可以将同一个topic的消息,放到不同的分区中,类似数据分片。
2.kafka数据如何保证顺序消费
kafka可以按照消息的key值进行hash分区,保证同一个key值的消息,进入到同一分区中。对同一分区的消息进行顺序性消费,可以保证消费信息的顺序性。总而言之,kafka在同一分区的消息是可以保证有序性的。所以开发者在使用producer生产消息的时候,只要保证消息发送到分区的顺序性,就可以保证后续消息的顺序消费。
3.kafka中consumer的分组
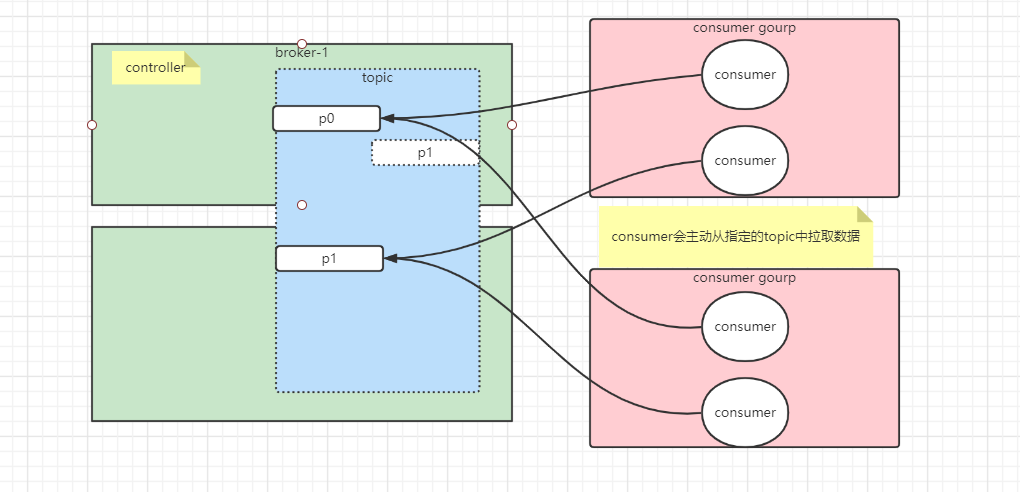
在kafak中,一个consumer可以消费多个paritition中的消息。可以是1:n。但是一个partition不能同时让一个组中的多个consumer消费,否则会破坏消息消费的有序性。但是多个group可以同时消费一个分区里的数据。如果一个组内有两个consumer,并且topic中有两个分区,那么两个consumer分别会消费一个分区中的信息。如上图。
4.消息队列,常见保证消息顺序性消费的两种方案
1.生产时保证消息的有序性,单线程消费
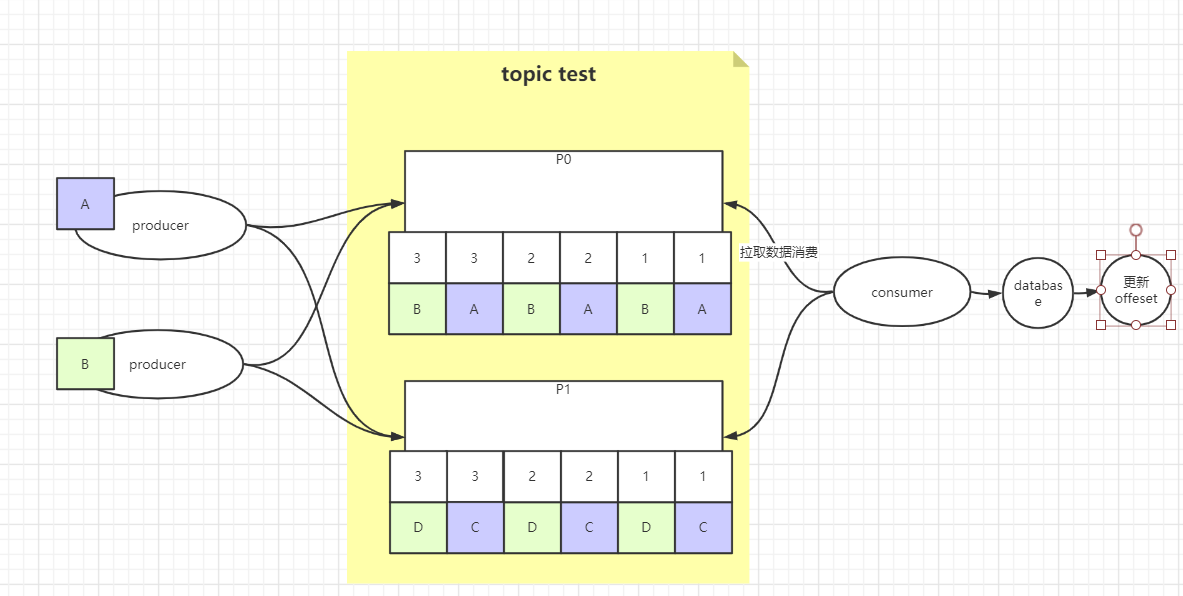
多线程生产消息,后面单线程消费数据,可以消费一条数据,就更新kafka偏移量offset的值,这种方式可以保证消息消费的进度,以及准确地更细offset的值,但是单线程的消费会对数据库以及offset进行频繁的更新,成本有点高,并且存在cpu以及网卡的资源浪费。
2.多线程消费
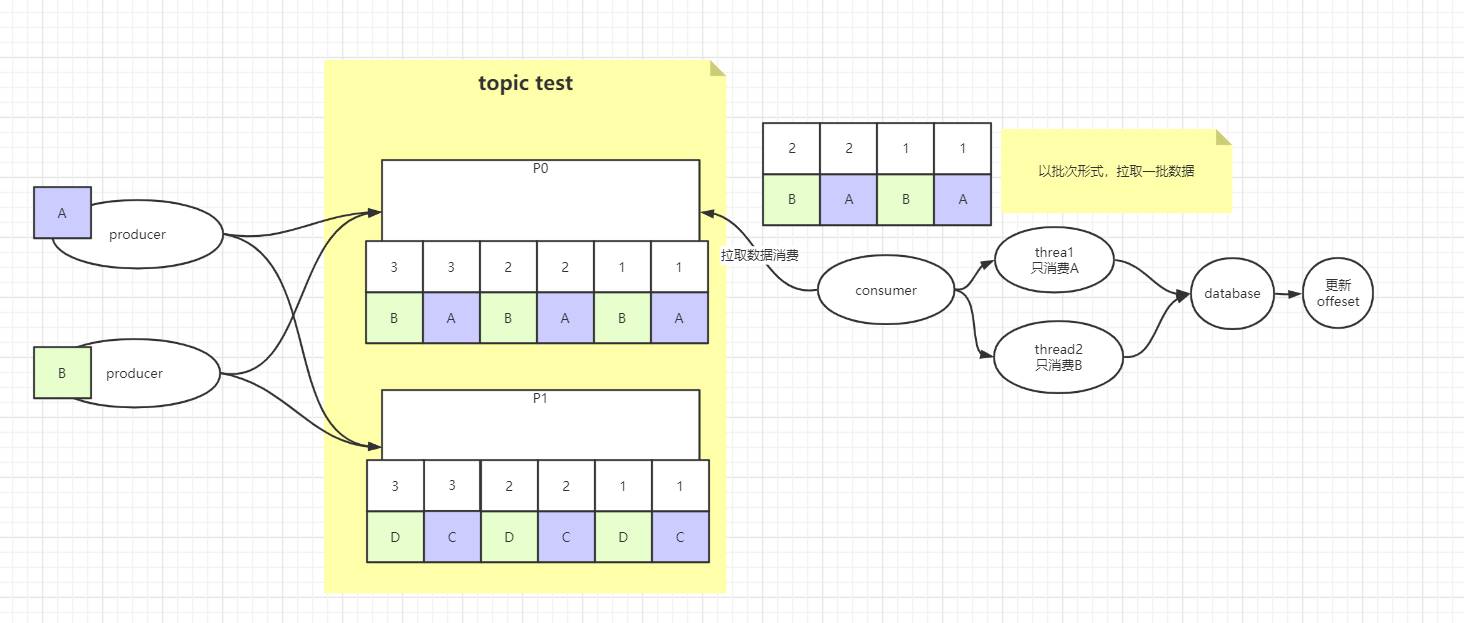
按批次从partition中拉取一批数据,消费规则中让同一类型的数据在同一线程中顺序性消费,但是后续对于数据库这种类型的操作,以批次的方式统一进行更新,最后以数据的事务结果,去更新offset。
5.kafka的消息生产的确认机制-- ack确认机制
Kafka生产者在发送完一个的消息之后,要求Broker在规定的时间内Ack应答,如果没有在规定时间内应答,Kafka生产者会尝试重新发送消息。默认acks=1。
acks=1 - Leader会将Record写到其本地日志中,但会在不等待所有Follower的完全确认的情况下做出响应。在这种情况下,如果Leader在确认记录后立即失败,但在Follower复制记录之前失败,则记录将丢失。
acks=0 - 生产者根本不会等待服务器的任何确认。该记录将立即添加到套接字缓冲区中并视为已发送。在这种情况下,不能保证服务器已收到记录。
acks=all /-1 - 这意味着Leader将等待全套同步副本确认记录。这保证了只要至少一个同步副本仍处于活动状态,记录就不会丢失。这是最有力的保证。这等效于acks = -1设置。
request.timeout.ms = 30000 默认 retries = 2147483647 默认
6.kafka的ISR、OSR以及AR
AR:Assigned Replicas 总的分配副本 OSR:Out-of-Sync Replicas 脱离同步副本。 数据同步严重滞后的副本组成OSR(网络原因造成的等等) ISR:in-sync-replica set 同步副本设置。为了解决数据同步高延迟问题以及leader重新选举时不会影响数据同步。
kafka中,ISR集合中的分区会定时从分区leader中同步数据,当acks=-1时,ISR集合中过半的节点同步完数据才会发送ack应答给producer。ISR是可以动态伸缩的。如果一个ISR中的节点,在一定时间内没有同步分区leader中的数据,那么这个节点就会从ISR中剔除,进入OSR。如果OSR中节点的数据同步已经跟上了leader,那么它会重新回到ISR中。
7.kafka中的索引
kafka中索引文件有两个,分别是offset的索引文件以及timeindex的索引文件,文件初始化时,都是10M大小。offset索引文件中会记录offset的值,以及文件中的position。以position取读取log文件中的一批数据。timeindex索引会记录一个时间戳,以及对应的offset,所以需要重新去offset的索引文件中找到offset对应的log文件的position,再去读取数据。
参考文档:
kafka英文官方网站:http://kafka.apache.org/documentation/
kafka中文官方网站:https://kafka.apachecn.org/intro.html
kafka从入门到了解的更多相关文章
- 【转】kafka概念入门[一]
转载的,原文:http://www.cnblogs.com/intsmaze/p/6386616.html ---------------------------------------------- ...
- docker安装kafka快速入门
docker安装kafka快速入门 1.安装zookeeper docker search zookeeperdocker pull zookeeperdocker run -d -v /home/s ...
- Kafka从入门到放弃(三) —— 详说生产者
上一篇对Kafka做了简单介绍,还没看的朋友可以点击下方链接. Kafka从入门到放弃(一) -- 初识别Kafka 消息中间件必须与生产者和消费者一起存在才有意义,这次先来聊聊Kafka的生产者. ...
- Kafka从入门到放弃(三)—— 详说消费者
之前介绍了Kafka以及生产者,包括它的一些特性和参数,这回写一下消费者. 之前没看得可以点击链接阅读. Kafka从入门到放弃(一) -- 初识Kafka Kafka从入门到放弃(二) -- 详说生 ...
- kafka快速入门(官方文档)
第1步:下载代码 下载 1.0.0版本并解压缩. > tar -xzf kafka_2.11-1.0.0.tgz > cd kafka_2.11-1.0.0 第2步:启动服务器 Kafka ...
- Kafka 之 入门
摘要: 最近研究采集层,对Kafka做了一个研究.分为入门,中级,高级步步进阶.本篇主要介绍基本概念,适用场景. 一.入门 1. 简介 Kafka is a distributed, parti ...
- Kafka【入门】就这一篇!
为获得更好的阅读体验,建议您访问原文地址:传送门 前言:在之前的文章里面已经了解到了「消息队列」是怎么样的一种存在(传送门),Kafka 作为当下流行的一种中间件,我们现在开始学习它! 一.Kafka ...
- Kafka使用入门教程
转载自http://www.linuxidc.com/Linux/2014-07/104470.htm 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自 ...
- Kafka使用入门教程 简单介绍
介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语: Kafka将消息以 ...
随机推荐
- VUE常见问题
VUE常见问题 对于MVVM的理解 MVVM 是 Model-View-ViewModel 的缩写 Model代表数据模型,也可以在Model中定义数据修改和操作的业务逻辑 View 代表UI 组件, ...
- webapi_3 今天真真真全是大经典案例
这个项目一多起来了,还是分个序号比价好一点,你好我好大家好,然后关于这个标点符号的问题,我打字真的很不喜欢打标点符号,不是不好按,按个逗号其实也是顺便的事情,可能就是养成习惯了,就喜欢按个空格来分开, ...
- 服务端处理 Watcher 实现 ?
1.服务端接收 Watcher 并存储 接收到客户端请求,处理请求判断是否需要注册 Watcher,需要的话将数据节点 的节点路径和 ServerCnxn(ServerCnxn 代表一个客户端和服务端 ...
- 用 wait-notify 写一段代码来解决生产者-消费者问题?(答案)
请参考答案中的示例代码.只要记住在同步块中调用 wait() 和 notify()方法,如果阻塞,通过循环来测试等待条件.
- 转载:TCP协议如何保证可靠传输
转载至:https://www.cnblogs.com/xiaokang01/p/10033267.html TCP协议如何保证可靠传输 概述: TCP协议保证数据传输可靠性的方式主要有: (校 序 ...
- 创建Maven web工程
---恢复内容开始--- 第一步,启动Eclipse,依次打开菜单[File][New][Other] 找到目录Maven,选择Maven Project, 选择一个Archetype.这里创建Web ...
- Flask-SQLAlchemy 使用教程
Flask-SQLAlchemy ,是对SQLAlchemy进一步封装 SQLAlchemy使用教程地址: https://www.cnblogs.com/bigox/p/11552542.html ...
- OpenCV+QT5在Window下的环境配置记录
在安装OpenCV时最需要注意的是,OpenCV库,也就是我们需要的dll和动态库需要我们使用CMake来生成. 虽然在官网上下载得到的文件中已经包含了库文件和.h等头文件,但是在具体开发中编译器编译 ...
- 学习webpack前的准备工作
前言 由于vue和react的流行,webpack这个模块化打包工具也已经成为热门.作为前端工程师这个需要不断更新自己技术库的职业,真的需要潜下心来学习一下. 准备工作(针对mac用户) 安装 hom ...
- 国际化相对时间格式化API:Intl.RelativeTimeFormat
原文:The Intl.RelativeTimeFormat API 作者:Mathias Bynens(@mathias) 现代 Web 应用程序通常使用"昨天","4 ...