【Python】批量查询-提取站长之家IP批量查询的结果加强版本v3.0
1、工具说明
写报告的时候为了细致性,要把IP地址对应的地区给整理出来。500多条IP地址找出对应地区复制粘贴到报告里整了一个上午。
为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本。
某个项目每次改需求都是这么突然。 应 XX 每天要求各种省份域名统计,再加强下Domain to IP to 地区的脚本。
Domain2ip2locality.py v2.0 写入到XLS中
Domain2ip2locality.py v3.0 增加域名解析IP、IP解析地区的部分
2、使用方法
把IP写到.txt文件中就可以了,输出到D:\0utCode_ip_domain\目录内的IP.xls内。代码注释中已经说明!
#-*-coding:utf-8-*-
import sys
import os
import requests
from bs4 import BeautifulSoup
import tablib
import socket
import re
# Domain2ip2locality.py v3.0
# 作者:zzzhhh
# 2017-9-30
# 提取站长之家IP批量查询的结果加强版本-写入到XLS中
# 增加域名解析IP、IP解析地区的部分
## 默认存放路径D:\\0utCode_ip_domain\\ip.xls
path = "D:\\0utCode_ip_domain\\" # 存放路径
filename = "ip" # 文件名称
dataset1 = tablib.Dataset() # 数据集合
ip_list = [] # IP列表
# 写XLS
def into_els(old_ip,new_ip,taglocality):
headers = ('域名','ip', '地区') # 首行字段
dataset1.headers = headers
dataset1.append((old_ip,new_ip,taglocality))
# 判断是否是IP
def DetermineIPorDomain(unknow):
# IP判断的正则
reip = r'\d+\.\d+\.\d+\.\d+'
ip = re.findall(reip, unknow)
if len(ip)>0:
return ip
else:
ip = www_ip(unknow)
return ip
# 域名转换IP
def www_ip(name):
try:
result = socket.getaddrinfo(name,None)
return result[0][4][0]
except:
return 0
#匹配出IP地址函数
def matchIP (new_ip,old_ip):
url = "http://ip.chinaz.com/"
try:
url = url+str(new_ip)
except:
print url
## 根据传入的IP地址截取出地区
wbdata = requests.get(url).text
soup = BeautifulSoup(wbdata, 'lxml')
for tag in soup.find_all('span', class_='Whwtdhalf w50-0'):
tag_extractl = tag.get_text().encode('utf-8')
if tag_extractl.find("IP的物理位置"): #过滤掉【IP的物理位置】这个字符
print "%s||%s||%s" % (old_ip,new_ip,tag.get_text()) #输出域名,IP,地区
into_els(old_ip,new_ip,tag.get_text()) #写数据到数据集合中
#读取文件函数
def read_file(file_path):
# 判断文件路径是否存在,如果不存在直接退出,否则读取文件内容
if not os.path.exists(file_path):
print 'Please confirm correct filepath !'
sys.exit(0)
else:
with open(file_path, 'r') as source:
for line in source:
ip_list.append(line.rstrip('\r\n').rstrip('\n'))
# 遍历IP,通过站长之家查询IP对应地区
for ip in ip_list:
to_ip = DetermineIPorDomain(ip) # 转换
matchIP(to_ip,ip)
# 写文件到Excel
hFile = open(path + filename + '.xls', "wb")
hFile.write(dataset1.xls)
hFile.close()
if __name__ == '__main__':
file_str=raw_input('Input file ip.txt filepath eg:D:\\\\test.txt \n')
#file_str = "D:\\WebUrl.txt"
read_file(file_str) #读取文件
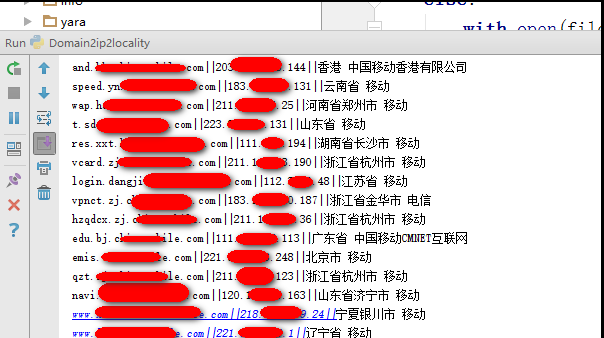
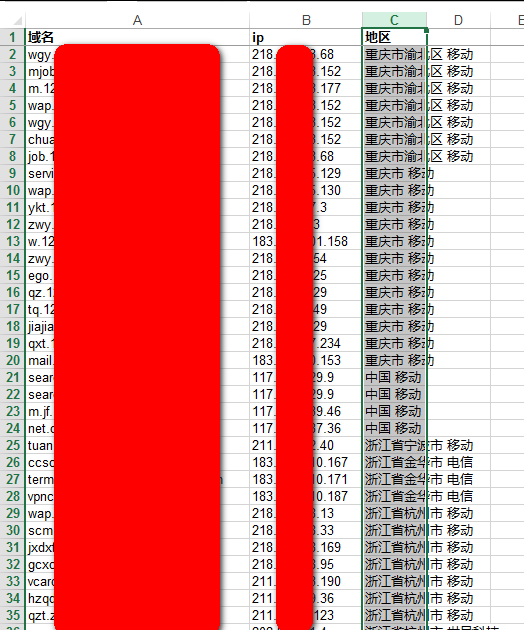
3、 代码效果
用Excel自定义排序就可以可以排序某个特定省份了。。。


【Python】批量查询-提取站长之家IP批量查询的结果加强版本v3.0的更多相关文章
- 【Python】批量查询-提取站长之家IP批量查询的结果v1.0
0 前言 写报告的时候为了细致性,要把IP地址对应的地区给整理出来.500多条IP地址找出对应地区复制粘贴到报告里整了一个上午. 为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本. 1 使 ...
- 提取站长之家IP批量查询
1.工具说明 写报告的时候为了细致性,要把IP地址对应的地区给整理出来.500多条IP地址找出对应地区复制粘贴到报告里整了一个上午. 为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本. 使 ...
- 【python数据挖掘】批量爬取站长之家的图片
概述: 站长之家的图片爬取 使用BeautifulSoup解析html 通过浏览器的形式来爬取,爬取成功后以二进制保存,保存的时候根据每一页按页存放每一页的图片 第一页:http://sc.china ...
- Python 超简单 提取音乐高潮(附批量提取)
很多时候我们想提取某首歌的副歌部分(俗称 高潮部分),只能手动直接卡点剪切,但是对于大批量的获取就很头疼,如何解决? 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后 ...
- python requests库爬取网页小实例:ip地址查询
ip地址查询的全代码: 智力使用ip183网站进行ip地址归属地的查询,我们在查询的过程是通过构造url进行查询的,将要查询的ip地址以参数的形式添加在ip183url后面即可. #ip地址查询的全代 ...
- [1]IP地址查询
今天起开始玩百度APIStore里面的免费API.以前用过的有12306的:数据.接口,有时间整理出来,12306的有点乱就是了.还有扇贝以及有道的API,之前用在留言板里自动翻译,公司用过百度地图以 ...
- 利用Python制作简单的小程序:IP查看器
前言 说实话,查看电脑的IP,也挺无聊的,但是够简单,所以就从这里开始吧.IP地址在操作系统里就可以直接查看.但是除了IP地址,我们也想通过IP获取地理地址和网络运营商情况.IP地址和地理地址并没有固 ...
- python扫描proxy并获取可用代理ip列表
mac或linux下可以work的代码如下: # coding=utf-8 import requests import re from bs4 import BeautifulSoup as bs ...
- 【学习】Python进行数据提取的方法总结【转载】
链接:http://www.jb51.net/article/90946.htm 数据提取是分析师日常工作中经常遇到的需求.如某个用户的贷款金额,某个月或季度的利息总收入,某个特定时间段的贷款金额和笔 ...
随机推荐
- day14 闭包
闭包的概念 必须要有函数嵌套,内部函数调用外部函数的变量 简单的例子 此种方法会导致每次使用内部函数inner的时候需要不断的调用外部函数. 结果导致外部函数的变量不断的被调用被释放,比较低效,相当于 ...
- day12 max min zip 用法
max min ,查看最大值,最小值 基础玩法 l = [1,2,3,4,5] print(max(l)) print(min(l)) 高端玩法 默认字典的取值是key的比较 age_dic={'al ...
- MT【63】证明不是周期函数
证明$f(x)=sinx^2$不是周期函数. 反证:假设是周期函数,周期为$T,T>0$. $$f(0)=f(T)\Rightarrow sinT^2=0\Rightarrow T^2=k_1\ ...
- Luogu 2668 NOIP 2015 斗地主(搜索,动态规划)
Luogu 2668 NOIP 2015 斗地主(搜索,动态规划) Description 牛牛最近迷上了一种叫斗地主的扑克游戏.斗地主是一种使用黑桃.红心.梅花.方片的A到K加上大小王的共54张牌来 ...
- JS模块化开发(二)——构建工具grunt
gruntJs——构建工具:代码压缩.文件合并 安装流程: 1.到nodeJs官网下载安装nodeJs(附带了npm包管理工具) 2.cmd命令行:npm install -g grunt-cli / ...
- laravel/lumen 的构造函数需要注意的地方
比如 lumen,ConsoleServiceProvider 里面的 register 做了下面的处理: \Laravel\Lumen\Console\ConsoleServiceProvider: ...
- nginx设置反向代理后端jenklins,页面上的js css文件无法加载
转载 2017年06月14日 22:36:59 8485 问题现象: nginx配置反向代理后,网页可以正常访问,但是页面上的js css文件无法加载,页面样式乱了. (1)nginx配置如下: (2 ...
- python 面向对象之多态
多态是什么? 用一句话来概括下,多态就是同一操作(方法)作用于不同的对象时,可以有不同的解释,产生不同的执行结果. #!/usr/bin/env python # -*- coding: utf-8 ...
- RESTful框架简述
什么是RESTful架构: (1)每一个URI代表一种资源: (2)客户端和服务器之间,传递这种资源的某种表现层: (3)客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态 ...
- Nginx 入门指南
Nginx 入门指南 简介: Nginx 是一款轻量级的 Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,其特点是占有内存少,并发能力强.本教程根据淘宝核心系统服务器平台组的 ...