【python数据挖掘】批量爬取站长之家的图片
概述:
站长之家的图片爬取
使用BeautifulSoup解析html
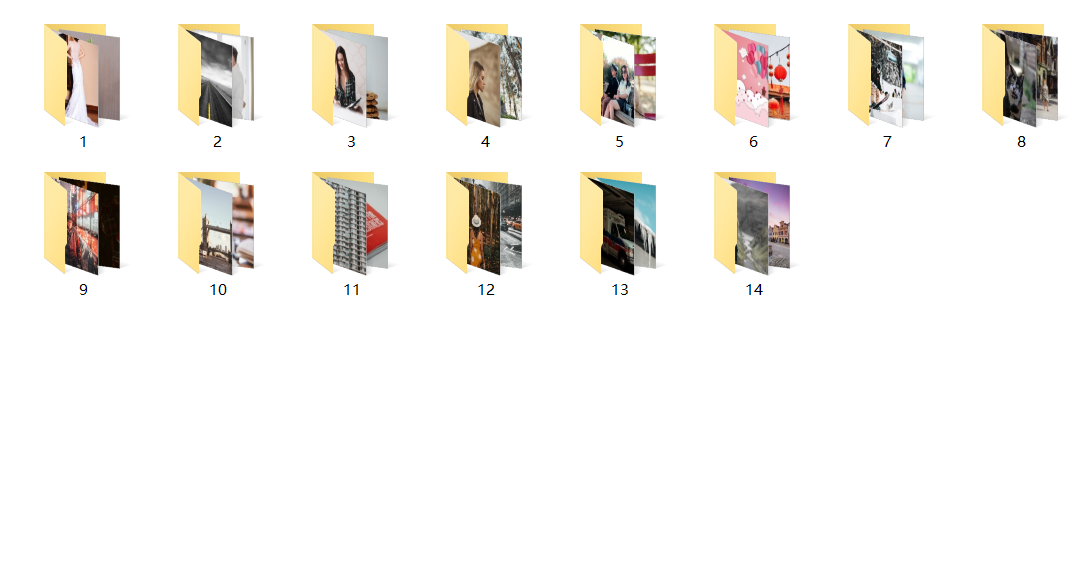
通过浏览器的形式来爬取,爬取成功后以二进制保存,保存的时候根据每一页按页存放每一页的图片
第一页:http://sc.chinaz.com/tupian/index.html
第二页:http://sc.chinaz.com/tupian/index_2.html
第三页:http://sc.chinaz.com/tupian/index_3.html
以此类推,遍历20页
源代码
# @Author: lomtom
# @Date: 2020/2/27 14:22
# @email: lomtom@qq.com
# 站长之家的图片爬取
# 使用BeautifulSoup解析html
# 通过浏览器的形式来爬取,爬取成功后以二进制保存
# 第一页:http://sc.chinaz.com/tupian/index.html
# 第二页:http://sc.chinaz.com/tupian/index_2.html
# 第三页:http://sc.chinaz.com/tupian/index_3.html
# 遍历14页
import os
import requests
from bs4 import BeautifulSoup
def getImage():
url = ""
for i in range(1,15):
# 创建文件夹,每一页放进各自的文件夹
download = "images/%d/"%i
if not os.path.exists(download):
os.mkdir(download)
# url
if i ==1:
url = "http://sc.chinaz.com/tupian/index.html"
else:
url = "http://sc.chinaz.com/tupian/index_%d.html"%i
#发送请求获取响应,成功状态码为200
response = requests.get(url)
if response.status_code == 200:
# 使用bs解析网页
bs = BeautifulSoup(response.content,"html5lib")
# 定位到图片的div
warp = bs.find("div",attrs={"id":"container"})
# 获取img
imglist = warp.find_all_next("img")
for img in imglist:
# 获取图片名称和链接
title = img["alt"]
src = img["src2"]
# 存入文件
with open(download+title+".jpg","wb") as file:
file.write(requests.get(src).content)
print("第%d页打印完成"%i)
if __name__ == '__main__':
getImage()
效果图
作者
【python数据挖掘】批量爬取站长之家的图片的更多相关文章
- python爬取站长之家植物图片
from lxml import etree from urllib import request import urllib.parse import time import os def hand ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 【Python】批量查询-提取站长之家IP批量查询的结果v1.0
0 前言 写报告的时候为了细致性,要把IP地址对应的地区给整理出来.500多条IP地址找出对应地区复制粘贴到报告里整了一个上午. 为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本. 1 使 ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- 【Python】批量查询-提取站长之家IP批量查询的结果加强版本v3.0
1.工具说明 写报告的时候为了细致性,要把IP地址对应的地区给整理出来.500多条IP地址找出对应地区复制粘贴到报告里整了一个上午. 为了下次更好的完成这项重复性很高的工作,所以写了这个小的脚本. 某 ...
- 【python数据挖掘】爬取豆瓣影评数据
概述: 爬取豆瓣影评数据步骤: 1.获取网页请求 2.解析获取的网页 3.提速数据 4.保存文件 源代码: # 1.导入需要的库 import urllib.request from bs4 impo ...
- 【Python】批量爬取网站URL测试Struts2-045漏洞
1.概述都懒得写了.... 就是批量测试用的,什么工具里扣出来的POC,然后根据自己的理解写了个爬网站首页URL的代码... #!/usr/bin/env python # -*- coding: u ...
- Python爬虫项目--爬取链家热门城市新房
本次实战是利用爬虫爬取链家的新房(声明: 内容仅用于学习交流, 请勿用作商业用途) 环境 win8, python 3.7, pycharm 正文 1. 目标网站分析 通过分析, 找出相关url, 确 ...
- 从0实现python批量爬取p站插画
一.本文编写缘由 很久没有写过爬虫,已经忘得差不多了.以爬取p站图片为着手点,进行爬虫复习与实践. 欢迎学习Python的小伙伴可以加我扣群86七06七945,大家一起学习讨论 二.获取网页源码 爬取 ...
随机推荐
- 使用doxygen
Getting started with Doxygen 可执行文件doxygen是解析源文件并生成文档的主程序. 另外, 也可以使用可执行文件doxywizard, 是用于编辑配置文件, 以及在图形 ...
- Java容器解析系列(11) HashMap 详解
本篇我们来介绍一个最常用的Map结构--HashMap 关于HashMap,关于其基本原理,网上对其进行讲解的博客非常多,且很多都写的比较好,所以.... 这里直接贴上地址: 关于hash算法: Ha ...
- COCOAPI for windows error!
refer this https://github.com/philferriere/cocoapi However, you may encounter a bug where you cannot ...
- Windows下Charles从下载安装到证书设置和浏览器抓包
1.在Charles官网https://www.charlesproxy.com/download/下载,我这边下载的是免费体验版的. 2.安装好以后打开,配置Charles证书:选择help——SS ...
- Spring(四)核心容器 - BeanDefinition 解析
前言 在上篇文章中,我们讨论了 refresh 的前四个方法,主要是对 ApplicationContext 上下文启动做一些准备工作.原计划是对接下来的 invokeBeanFactoryPostP ...
- 容器技术与docker
名词介绍 IaaS:基础设施即服务,要搭建上层数据应用,先得通过互联网获得基础性设施服务 PaaS:平台即服务,搭建平台,集成应用产品,整合起来提供服务 SaaS:软件即服务,通过网络提供程序应用类服 ...
- 【WPF学习】第三十章 元素绑定——绑定到非元素对象
前面章节一直都在讨论如何添加链接两个各元素的绑定.但在数据驱动的应用程序中,更常见的情况是创建从不可见对象中提取数据的绑定表达式.唯一的要求是希望显示的信息必须存储在公有属性中.WPF数据绑定数据结构 ...
- Maven异常:Dynamic Web Module 3.0 requires Java 1.6 or newer.
问题 我目前用的JDK 是java 1.8 ,搭建Maven项目的时候,设置Project facets后,出现来以下problem : Dynamic Web Module 3.0 requires ...
- Java 设计模式之抽象工厂模式
抽象工厂模式(Abstract Factory Pattern)是围绕一个超级工厂创建其他工厂.该超级工厂又称为其他工厂的工厂.这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式. 在抽 ...
- 【读书笔记】关于《精通C#(第6版)》与《C#5.0图解教程》中的一点矛盾的地方
志铭-2020年2月8日 03:32:03 先说明,这是一个旧问题,很久很久以前大家就讨论了, 哈哈哈,而且先声明这是一个很无聊的问题,