Pyhthon爬虫其之验证码识别
背景
现在的登录系统几乎都是带验证手段的,至于验证的手段也是五花八门,当然用的最多的还是验证码。不过纯粹验证码识已经是很落后的东西了,现在比较多见的是滑动验证,滑动拼图验证(这个还能往里面加广告)、点击图片特定位置确认(同样能放广告),再或者谷歌的No-CAPTCHA。总之纯粹的验证码效果不好,成本也不如一众新型验证码,迟早是要被全部淘汰的,但现在仍然有很多地方在使用传统的图片验证码。所以提到自动模拟登录,验证码识别肯定也是需要进行研究的。
思路
由于我此前并没有接触过验证码识别的相关知识,所以在开工前在网上查找了大量的资料,个人觉得对我最有帮助的三篇附在文章最后。
在翻阅了大量的博客、文章后我采用的识别方法为pytesser中的image_to_string函数。
起先是打算按照某篇文章的介绍,使用libSVM进行人工网络识别,但在完成了图片处理后,我发现使用pytesser进行识别的成功率已经达到了8成以上,便没有继续研究下去(因为我懒…)
验证码是别的流程大概是这样的:
1. 获取验证码图片
2. 二值化图片(使图片只有黑白两种像素)
3. 去噪、去干扰线
4. 修正扭曲、变形
5. 分割字符(视识别手段而定)
6. 识别
其中的去噪和修正并没有严格的先后顺序,怎么办效果好就怎么办。
由于我校教务处的验证码没有扭曲变形,而我也没有使用神经网络识别,所以我在这次的实际操作中只使用了1、2、3、6,不过分割字符的部分我也完成了,只是最后发现不需要使用神经网络所以没有放进最后的代码中。
所需工具
这里列出识别验证码所需的第三方库。
- PIL(图片处理库,不解释了)
- pytesser(识别验证码的库,需要使用Tesseract这个开源项目)
- Tesseract
关于这几个东西怎么装,如果你是liunx用户,我不用说,你们肯定会,yum 、sudo、apt-get……不同的liunx有不同的方法。
如果你win用户,CMD——pip install pillow(pip是python带的,当然能在win下使用)——pip install pytesser——去github找到Tesseract项目的主页,里面有windows版的exe安装包,理论上只需要装Tesseract而不需要装Tesseract-ORC,但反正我们也不缺这么点储存空间。
代码
怎么获取验证码图片我就不再提了,这是很基础的技能,上篇也有讲。
图片二值化
from PIL import Image
i = 0
img = Image.open('E:/cCode/image.png') # 读入图片
img = img.convert("RGBA")
while i < 4:#循环次数视情况进行调整
i = i+1
pixdata = img.load()
#一次二值化
for y in range(img.size[1]):
for x in range(img.size[0]):
if pixdata[x, y][0] < 90:#使RGB值中R小于90的像素点变成纯黑
pixdata[x, y] = (0, 0, 0, 255)
for y in range(img.size[1]):
for x in range(img.size[0]):
if pixdata[x, y][1] < 190:#使RGB值中G小于90的像素点变成纯黑
pixdata[x, y] = (0, 0, 0, 255)
for y in range(img.size[1]):
for x in range(img.size[0]):
if pixdata[x, y][2] > 0:#使RGB值中B大于0的像素点变成纯白
pixdata[x, y] = (255, 255, 255, 255)
'''
理论上的二值化代码只有上面那些,RGB值的调整阈值需要针对不同验证码反复调整。同时实际中一组阈值往往没法做到完美,后面的部分是视实际情况添加的类似部分
'''
#二次二值化(除去某些R、G、B值接近255的颜色)
for y in range(img.size[1]):
for x in range(img.size[0]):
if pixdata[x, y][0] < 254:
pixdata[x, y] = (0, 0, 0, 255)
for y in range(img.size[1]):
for x in range(img.size[0]):
if pixdata[x, y][1] < 254:
pixdata[x, y] = (0, 0, 0, 255)
for y in range(img.size[1]):
for x in range(img.size[0]):
if pixdata[x, y][2] > 0:
pixdata[x, y] = (255, 255, 255, 255)
#三次二值化,怼掉纯黄色(实际使用中发现很多图片最后剩几个纯黄色的像素点)
for y in range(img.size[1]):
for x in range(img.size[0]):
if pixdata[x, y] ==(255,255,0,255):
pixdata[x, y] = (0, 0, 0, 255)
img.save('e:/cCode/image.png', "png")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
经过二值化的图片,应该只剩下黑白2种像素
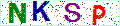
二值化前
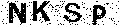
二值化后
二值化的各项颜色阈值怎么调、用几次二值化,全要看实际情况来,总之一句话,效果怎么好怎么来。
去噪
from PIL import Image
#一次清除黑点
def fall ():
white = (255,255,255,255)
black = (0,0,0,255)
img = Image.open('E:/cCode/image.png') # 读入图片
pixdata = img.load()
X = img.size[0]-1#因为我校的验证码二值化后正好剩下一圈宽度为一像素的白边,所以这么处理了
Y = img.size[1]-1
def icolor(RGBA):
if RGBA == white:
return(1)
else:
return(0)
for y in range(Y):
for x in range(X):
if (x<1 or y<1):
pass
else:
if icolor(pixdata[x,y]) == 1:
pass
else:
if (
icolor(pixdata[x+1,y])+
icolor(pixdata[x,y+1])+
icolor(pixdata[x-1,y])+
icolor(pixdata[x,y-1])+
icolor(pixdata[x-1,y-1])+
icolor(pixdata[x+1,y-1])+
icolor(pixdata[x-1,y+1])+
icolor(pixdata[x+1,y+1])
)>5:
#如果一个黑色像素周围的8个像素中白色像素数量大于5个,则判断其为噪点,填充为白色
pix[x,y] = white
#填充白点
for y in range(Y):
for x in range(X):
if (x<1 or y<1):
pass
else:
if icolor(pixdata[x,y]) == 0:
pass
else:
if (
(icolor(pixdata[x+1,y]))+
(icolor(pixdata[x,y+1]))+
(icolor(pixdata[x-1,y]))+
(icolor(pixdata[x,y-1]))
)<2:
#如果一个白色像素上下左右4个像素中黑色像素的个数大于2个,则判定其为有效像素,填充为黑色。
pix[x,y] = black
#二次去除黑点
for y in range(Y):
for x in range(X):
if (x<1 or y<1):
pass
else:
if icolor(pixdata[x,y]) == 1:
pass
else:
if (
icolor(pixdata[x+1,y])+
icolor(pixdata[x,y+1])+
icolor(pixdata[x-1,y])+
icolor(pixdata[x,y-1])
)>2:
pix[x,y] = white
img.save('e:/cCode/image.png', "png")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
关于去噪,有一个填充算法叫做洪水算法,我本来是打算学着使用那个算法,所以将函数命名为fall,最后只是搞了个四不像出来,基本思路是判断一个像素周围有多少同色像素。
比如白色像素周围黑色像素大于5个则判断其为噪点
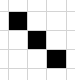
这种即会被填充为白点(以正中为基准,下同)
这种不会被填充为白点
而对白色像素进行的判断时值参考其上下左右4个像素
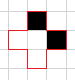
这种不会被填充为黑点
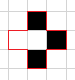
这种会被填充为黑点
当然,取几个点判定、判定阈值为多少、判定几次,也需要看实际情况来,比如我就是按照去噪、填白、去噪,一共来了三次,还是那句话,效果怎么好怎么来。
在实际使用中,对参数略加调整的话,可以做到在不修改代码结构的情况下去除不是很粗的干扰线。
刚完成二值化时
第一次去噪(可以看到还有很多空洞,右上角还有一个噪点)
白色像素已经填满了
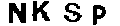
最后再去一次噪
如此处理完的验证码图片,直接调用image_to_string函数也能得到很好的识别效果了
识别
由于我选择了直接调用image_to_string函数,所以这里没啥特殊处理,直接加载文件,调用函数即可。
#验证码识别
import pytesseract
from PIL import Image
import re
def readcCode():
try:
img = Image.open('E:/cCode/image.png')
text = pytesseract.image_to_string (img)
text = text.replace(' ', '')
if text == "":#如果识别结果为空,则识别失败
tip = False
if re.search(r'[0-9a-zA-Z]{4}',text):
pass
else:
tip = False#如果识别结果中出现了了字母数字之外的字符,则识别失败
if len(text) !=4:
tip = False#如果识别结果不足四位(因为有部分字符粘连的验证码),则识别失败
except UnicodeDecodeError as e:
tip = False #如果报字符编码错误,则识别失败,需要捕捉错误
if tip == False:
#识别失败
return (readcCode())#如果识别失败,迭代、重新识别(实际使用中需要调用验证码获取函数重新获取验证码)
else:
return(text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
其实识别验证码的部分就三行罢了,主要是这个步骤会有很多BUG。有时候识别不出来;有时会识别出不正常的字符;有时候验证码图片会刷出来类似
到这里,我实际使用的验证码识别的代码就已经完了,不过我最开始有打算用神经网络,所以做好了字符分割,下面上代码。
字符分割
去除掉图片的白边
from PIL import Image
white = (255,255,255,255)
black = (0,0,0,255)
def char(i):
for y in Y[::1]:
for x in X[::1]:
if pix[x,y] == black :
y1 = y+1
for y in Y[::-1]:
for x in X[::1]:
if pix[x,y] == black :
y0 = y
for x in X[::1]:
for y in Y[::1]:
if pix[x,y] == black :
x1 = x+1
for x in X[::-1]:
for y in Y[::1]:
if pix[x,y] == black :
x0 = x
region=(x0,y0,x1,y1)
print(region)
cropImg = img.crop(region)
cropImg.save('E:/cCode2/image.png')
i = 0
while i <4:
i =i+1
img = Image.open('E:/image.png')
pix = img.load()
X = list(range(img.size[0]))
Y = list(range(img.size[1]))
char(i)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
代码片里没有注释了,因为我懒….本来我最后也没用这个
基本思路是从左到右扫描每列像素,检测到出现黑色像素记录列数,同理反向从右到左、从上到下、从下到上进行扫描,然后裁剪图片。
由于我没有实际采用这种方法,所以没图可上,但我是测试通过了的
分割字符
import pytesseract
from PIL import Image
#没有打开图片的代码,因为这段代码我当时已经把它混到主程序里去了,完全剥离开太费劲,故只复制主体
def char_str():
record = False
record1 = False
for y in Y[::1]:
for x in X[::1]:
if pix[x,y] == black :
y1 = y+1
for y in Y[::-1]:
for x in X[::1]:
if pix[x,y] == black :
y0 = y
for x in X[i::1]:
record2 = True
for y in Y[::1]:
if record == False:
if pix[x,y] == black :
record = True
x0 = x
if record == True:
if pix[x,y] == white:
record1 = True
else:
record1 = False
record2 = record2 and record1
if x <len(X)-1:
if record2 == True:
x1 = x
return [x0,y0,x1,y1]
#此处返回值为从左到右第一个字符的坐标,按坐标裁剪即可获得字符
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
裁剪字符的思路为,从左到右遍历每列像素,出现黑色像素时,记录x0值,继续向右,出现一整列全为白色时,记录x1 = 当前列数,纵向同理。
获得大量字符集后可以进行神经网络训练,关于这方面亲参考我最后附上的文章。
最初有考虑过按字符颜色进行分割,但最后发现有字符颜色一样的验证码,于是放弃。
总结
这次识别的验证码仍然算很简单的那种,没有变形、扭曲,没有很粗的干扰线,没有镂空字,没有全部粘连。但也是一次学到很多东西的体验。
其中最重要的收获不是学会了怎么识别验证码,毕竟这么耿直的验证码不多了。最重要的是,为以后自己制作验证码提供了大量的经验,怎样做才能提高验证码自动识别难度:粘连,扭曲变形,字符颜色不要完全不同,可以考虑使用镂空字、背景小字进行干扰。
同时我也在别的地方注意到了,某些连人都很难辨认的报社验证码,在机器面前反而会很简单。这种是最蠢的验证码,对自动识别没有防范作用,反而是让正常的用户们吃瘪,事实上只要自己有过做验证码识别的经历的话,是很容易发现这些问题的。
参考资料
对我最有帮助的当属下面三篇:
使用python以及工具包进行简单的验证码识别
(这篇博文讲的东西其实并不怎么深入,尤其图片处理方面几乎是完全没讲,而做过验证码识别的都知道,图片处理才是验证码识别的重中之重。但正因为这篇博文讲的很浅,将在python下使用pytesser进行验证码识别的流程完全讲清了。)
字符型图片验证码识别完整过程及Python实现
(这篇文章与上面那篇正好相反,获取验证码图片、处理图片、分割字符、神经网络训练等几大部分都讲的很详细。作者对自己的思路也叙述的有条有理,是这三篇文章里干货最多的。)
验证码——python去除干扰线
(这篇文章对我的主要意义在于为我提供了一个分割字符的思路,虽然最后并没有用上,因为分割字符是用于神经网络训练的。)
Pyhthon爬虫其之验证码识别的更多相关文章
- 爬虫—GEETEST滑动验证码识别
一.准备工作 本次使用Selenium,浏览器为Chrome,并配置好ChromDriver 二.分析 1.模拟点击验证按钮:可以直接使用Selenium完成. 2.识别滑块的缺口位置:先观察图 ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
- 二十二 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://github.com/muchrooms/zheye 注意:此程序依赖以下模块包 Keras==2.0.1 Pillow= ...
- Python爬虫教程:验证码的爬取和识别详解
今天要给大家介绍的是验证码的爬取和识别,不过只涉及到最简单的图形验证码,也是现在比较常见的一种类型. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻 ...
- 第二十三节:scrapy爬虫识别验证码(二)图片验证码识别
图片验证码基本上是有数字和字母或者数字或者字母组成的字符串,然后通过一些干扰线的绘制而形成图片验证码. 例如:知网的注册就有图片验证码 首先我们需要获取验证码图片,通过开发者工具我们可以得到验证码ur ...
- python3爬虫图片验证码识别
# 图片验证码识别 环境安装# sudo apt-get install -y tesseract-ocr libtesseract-dev libleptonica-dev# pip install ...
- ocr智能图文识别 tess4j 图文,验证码识别 分享及所遇到的问题
自己对tess4j的使用总结 1,tess4j 封装了 tesseract-ocr 的操作 可以用很简洁的几行代码就实现原本tesseract-ocr 复杂的实现逻辑 如果你也想了解tesseract ...
- [验证码识别技术]字符验证码杀手--CNN
字符验证码杀手--CNN 1 abstract 目前随着深度学习,越来越蓬勃的发展,在图像识别和语音识别中也表现出了强大的生产力.对于普通的深度学习爱好者来说,一上来就去跑那边公开的大型数据库,比如I ...
- ocr智能图文识别 tess4j 图文,验证码识别
最近写爬虫采集数据,遇到网站登录需要验证码校验,想了想有两种解决办法 1,利用htmlunit,将验证码输入到swing中,并弹出一个输入框,手动输入验证码,这种实现方式,如果网站需要登录一次可以使用 ...
随机推荐
- asp.net通过distinct过滤集合(list)中重复项的办法
/// <summary> /// 权限Distinct比较器 /// </summary> public class PermissionIdComparer : IEqua ...
- css 类选择器结合元素选择器和多类选择器
1.结合元素选择器 <p class="important">css</p> p.important {color: red} 匹配class属性包含imp ...
- 在windows下安装git中文版客户端并连接gitlab
下载git Windows客户端 git客户端下载地址:https://git-scm.com/downloads 我这里下载的是Git-2.14.0-64-bit.exe版本 下载TortoiseG ...
- 动态ip、静态ip、pppoe拨号的区别
pppoe拨号 pppoe拨号上网,又叫做ADSL拨号上网.宽带拨号上网.指现在有很多我的E家用户,送的无线猫,阉割了PPPOE拨号功能,必须要从电脑上拨号才能上网.还有大街上的WIFI热点也很多,如 ...
- android_双击退出
/** * 设置高速双击退出程序 */ @Override public boolean onKeyDown(int keyCode, KeyEvent event) { // TODO Auto-g ...
- svn与git操作对比 (未来有空做一个 svn与git实战对比 )
svn是集中式的,git是分布式的,但是我们日常使用的都是按照集中式唯一服务器仓库的方式来去做的,最终我们的代码都要提交到一个唯一仓库中. 他们最大的区别是本地工作拷贝的工作方式不同, 一.svn本地 ...
- 微软BI 之SSIS 系列 - 通过 OLE DB 连接访问 Excel 2013 以及对不同 Sheet 页的数据处理
文章更新历史 2014年9月7日 - 加入了部分更新内容,在文章最后提到了关于不同 Office Excel 版本间的连接问题. 开篇介绍 这篇文章主要总结在 SSIS 中访问和处理 Excel 数据 ...
- MySQL中的insert ignore into, replace into用法总结
MySQL replace into 有三种形式: 1. replace into tbl_name(col_name, ...) values(...) 2. replace into tbl_na ...
- 使用log4net将C#日志发送到Elasticsearch
一.安装Elasticsearch 参考前面写的文章:https://www.cnblogs.com/songxingzhu/p/7909486.html 安装完Elasticsearch后,修改/e ...
- domino server端的Notes.ini详解
Web代理监控与调式问题 Web代理在服务器的执行优先级是最高的,由Web代理引发的服务器宕机现象很多,但是我们很难监控Web代理的运行.通过对notes.ini的研究可以通过如下途径进行处理 ...