CUDA: 流
1. 页锁定主机内存
c库函数malloc()分配标准的,可分页(Pagable)的内存,cudaHostAlloc()分配页锁定的主机内存。页锁定内存也称为固定内存(Pinned Memory)或者不可分页内存,它有个重要属性:操作系统将不会对这块内存分页并交换到磁盘上,从而确保了该内存始终驻留在物理内存中。因此,操作系统能够安全的使某个应用程序访问该内存的物理地址,因为这块内存将不会被破坏或者重新定位。
由于GPU知道内存的物理地址,因此可以通过“直接内存访问(Direct Memory Access ,DMA)”技术来在GPU和主机之间复制数据。由于DMA在执行复制时无需CPU的介入,这也就同样意味着,CPU可能在DMA的执行过程中将目标内存交换到磁盘上,或者通过更新操作系统的可分页表来重新定位目标内存的物理地址。CPU可能会移动可分页的数据,这就可能对DMA操作造成延迟。因此,在DMA复制过程中使用固定内存是非常重要的。事实上,当使用可分页内存进行复制时,CUDA驱动程序仍然会通过DMA把数据传输给GPU。因此,复制操作将执行两遍,第一遍从可分页内存复制到一块临时的页锁定内存,然后再从这个页锁定内存复制到GPU上。因此,每当从可分页内存中执行复制操作时,复制速度将受限于PCIE传输速度和系统前端总线速度相对较低的一方。
当使用固定内存时,将失去虚拟内存的所有功能,导致系统更快的耗尽内存,降低系统整体性能。建议,仅对cudaMemcpy()调用中的源内存或者目标内存,才使用锁定内存,并且不再需要使用它们时立即释放,而不是等到应用程序关闭时才释放。
2. CUDA 流
CUDA流表示一个GPU操作队列,并且该队列中的操作将以指定的顺序执行。可以将每个流视为GPU的一个任务,并且这些任务可以并行执行。
选择一个支持设备重叠功能的设备:
cudaDeviceProp prop;
int whichDevice;
cudaGetDevice(&whichDevice);
cudaGetDevice(&prop, whichDevice);
if(!prop.deviceOverlap){
printf("Device will not handle overlaps , so no speed up from streams\n");
}
创建流:
cudaStream_t stream;
cudaStreamCreate(&stream);
使用流:
for(int i =; i< FULL_DATA_SIZE; i+=N){
cudaMemcpyAsync(dev_a, host_a + i, N*sizeof(int),cudaMemcpyHostToDevice, stream);
cudamemcpyAsync(dev_b, host_b + i, N*sizeof(int),cudaMemcpyHostToDevice, stream);
kernel<<<N/,,,stream>>>(dev_a, dev_b,dev_c);
cudaMemcpyAsync(host_c + i, dev_c, N*sizeof(int),cudaMemcpyDeviceToHost, stream);
}
任何传递给cudaMemcpyAsync的主机内存指针都必须已经通过cudaHostAlloc分配好内存,也就是说,你只能以异步方式对页锁定内存进行复制操作。
GPU与主机同步,调用cudaStreamSynchronize()并制定想要等待的流:
cudaStreamSynchronize(stream);
释放流:
cudaStreamDestroy(stream)
3. 使用多个流
for(int i =; i< FULL_DATA_SIZE; i+= *N){
cudaMemcpyAsync(dev_a0, host_a + i, N*sizeof(int),cudaMemcpyHostToDevice, stream0);
cudamemcpyAsync(dev_b0, host_b + i, N*sizeof(int),cudaMemcpyHostToDevice, stream0);
kernel<<<N/,,,stream0>>>(dev_a0, dev_b0,dev_c0);
cudaMemcpyAsync(host_c + i, dev_c0, N*sizeof(int),cudaMemcpyDeviceToHost, stream0);
//第二个流
cudaMemcpyAsync(dev_a1, host_a + i + N, N*sizeof(int),cudaMemcpyHostToDevice, stream1);
cudamemcpyAsync(dev_b1, host_b + i + N, N*sizeof(int),cudaMemcpyHostToDevice, stream1);
kernel<<<N/,,,stream1>>>(dev_a1, dev_b1,dev_c1);
cudaMemcpyAsync(host_c + i + N, dev_c1, N*sizeof(int),cudaMemcpyDeviceToHost, stream1);
}
cudaStreamSynchronize(stream0);
cudaStreamSynchronize(stream1);
4.GPU的工作调度机制
在硬件中并没有流的概念,而是包含一个或多个引擎(主机到设备,设备到主机可能是分开的两个引擎)来执行内存复制操作,以及一个引擎来执行核函数。这些引擎彼此独立的对操作进行排队,因此导致下图所示任务调度情形:
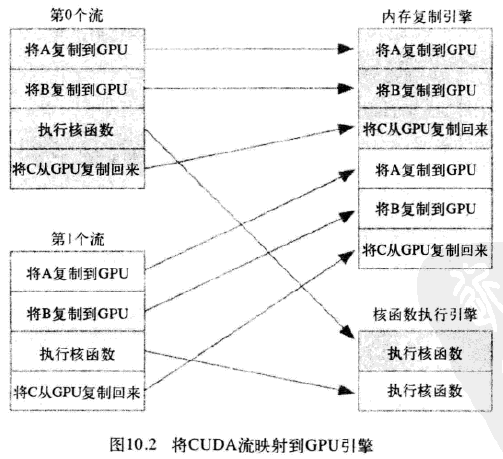
应用程序首先将第0个流的所有操作放入队列,然后是第一个流的所有操作。CUDA驱动程序负责按照这些操作的顺序把他们调度到硬件上执行,这就维持了流内部的依赖性。图10.3说明了这些依赖性,箭头表示复制操作要等核函数执行完成之后才能开始。

于是得到这些操作在硬件上执行的时间线:
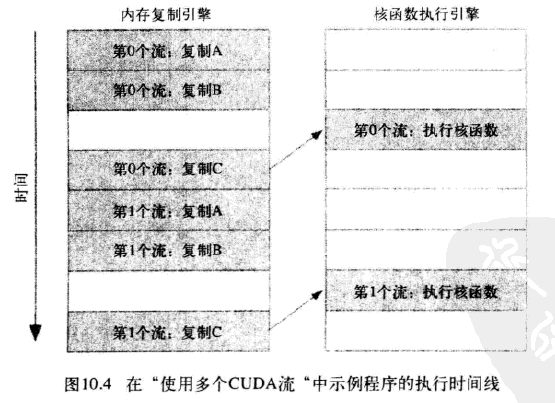
由于第0个流中将c复制回主机的操作要等待核函数执行完成,因此第1个流中将a和b复制到GPU的操作虽然是完全独立的,但却被阻塞了,这是因为GPU引擎是按照指定的顺序来执行工作。记住,硬件在处理内存复制和核函数执行时分别采用了不同的引擎,因此我们需要知道,将操作放入流队列中的顺序将影响着CUDA驱动程序调度这些操作以及执行的方式。
5. 高效使用多个流
如果同时调度某个流的所有操作,那么很容易在无意中阻塞另一个流的复制操作或者核函数执行。要解决这个问题,在将操作放入流的队列时应采用宽度优先方式,而非深度优先方式。如下代码所示:
for(int i =; i< FULL_DATA_SIZE; i+= *N){
cudaMemcpyAsync(dev_a0, host_a + i, N*sizeof(int),cudaMemcpyHostToDevice, stream0);
cudaMemcpyAsync(dev_a1, host_a + i + N, N*sizeof(int),cudaMemcpyHostToDevice, stream1);
cudamemcpyAsync(dev_b0, host_b + i, N*sizeof(int),cudaMemcpyHostToDevice, stream0);
cudamemcpyAsync(dev_b1, host_b + i + N, N*sizeof(int),cudaMemcpyHostToDevice, stream1);
kernel<<<N/,,,stream0>>>(dev_a0, dev_b0,dev_c0);
kernel<<<N/,,,stream1>>>(dev_a1, dev_b1,dev_c1);
cudaMemcpyAsync(host_c + i, dev_c0, N*sizeof(int),cudaMemcpyDeviceToHost, stream0);
cudaMemcpyAsync(host_c + i + N, dev_c1, N*sizeof(int),cudaMemcpyDeviceToHost, stream1);
}
如果内存复制操作的时间与核函数执行的时间大致相当,那么新的执行时间线将如图10.5所示,在新的调度顺序中,依赖性仍然能得到满足:
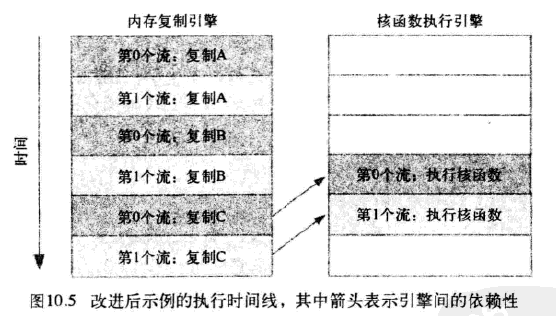
由于采用了宽度优先方式将操作放入各个流的队列中,因此第0个流对c的复制操作将不会阻塞第1个流对a和b的内存复制操作。这使得GPU能够并行的执行复制操作和核函数,从而使应用程序的运行速度显著加快。
CUDA: 流的更多相关文章
- cuda流测试=basic_single_stream
cuda流测试 /* * Copyright 1993-2010 NVIDIA Corporation. All rights reserved. * * NVIDIA Corporation and ...
- CUDA流(Stream)
CUDA流表示一个GPU操作队列,该队列中的操作将以添加到流中的先后顺序而依次执行.可以将一个流看做是GPU上的一个任务,不同任务可以并行执行.使用CUDA流,首先要选择一个支持设备重叠(Device ...
- CUDA中的流与事件
流:CUDA流很像CPU的线程,一个CUDA流中的操作按顺序进行,粗粒度管理多个处理单元的并发执行. 通俗的讲,流用于并行运算,比如处理同一副图,你用一个流处理左边半张图片,再用第二个流处理右边半张图 ...
- CUDA多个流的使用
CUDA中使用多个流并行执行数据复制和核函数运算可以进一步提高计算性能.以下程序使用2个流执行运算: #include "cuda_runtime.h" #include < ...
- 【CUDA 基础】6.1 流和事件概述
title: [CUDA 基础]6.1 流和事件概述 categories: - CUDA - Freshman tags: - 流 - 事件 toc: true date: 2018-06-10 2 ...
- 【CUDA 基础】6.0 流和并发
title: [CUDA 基础]6.0 流和并发 categories: - CUDA - Freshman tags: - 流 - 事件 - 网格级并行 - 同步机制 - NVVP toc: tru ...
- CUDA 7流简化并发
CUDA 7流简化并发 异构计算是指有效使用系统中的所有处理器,包括CPU和GPU.为此,应用程序必须在多个处理器上同时执行功能.CUDA应用程序通过在流(按顺序执行的命令序列)中,执行异步命令来管理 ...
- cuda by example【读书笔记2】
常量内存 用常量内存来替换全局内存可以有效的减少内存带宽 __constant__修饰符标识常量内存,从主机内存复制到GPU上的常量内存时,需要特殊版本的cudaMemcpy(): cudaMemcp ...
- 一篇不错的CUDA入门
鉴于自己的毕设需要使用GPU CUDA这项技术,想找一本入门的教材,选择了Jason Sanders等所著的书<CUDA By Example an Introduction to Genera ...
随机推荐
- ASIHTTPRequest 问题总结
1, ASIHttpRequest与30秒超时 今天在项目中发现一个ASIHttpRequest的Bug.这个Bug可能会导致你Http请求延时至少在timeout设置时间结束之后.更可怕的是,为了找 ...
- 在容器内执行go编译程序的坑
如果你编译了一个go程序,让后把它放到容器里面.很多时候这个程序都会无法执行,大概的样子是: /tmp # ls pub sub /tmp # ./pub /bin/ash: pub: not fou ...
- Mockito 如何 mock 返回值为 void 的方法
转载:https://unmi.cc/mockito-how-to-mock-void-method/#more-7748 最初接触 Mockito 还思考并尝试过如何用它来 mock 返回值为 vo ...
- 《linux 内核全然剖析》 mktime.c
tm结构体的定义在time.h里面 struct tm { int tm_sec; int tm_min; int tm_hour; int tm_mday; int tm_mon; int tm_y ...
- Win7如何修复开机画面
将下面文件保存为"修复Win7开机画面.bat"双击运行即可 bcdedit /set {current} locale zh-CN
- Webpack DLL
参考自:https://www.jianshu.com/p/a5b3c2284bb6 在用 Webpack 打包的时候,对于一些不经常更新的第三方库,比如 react,lodash,我们希望能和自己的 ...
- SVN 服务端、客户端安装及配置、导入导出项目
http://blog.csdn.net/xcy13638760/article/details/12994923 http://www.cnblogs.com/armyfai/p/3985660.h ...
- 1BIT,1BYTE,1KB,1MB,1GB,1TB等计量单位换算
http://iask.sina.com.cn/b/8961090.html知识 在数字世界里没有电影.没有杂志.没有一首首的乐曲,只有一个个的数字“1”和“0”.以前人们对于数字世界中的这两个数 ...
- vscode Js 插件 Jshint 的配置
vscode这款编辑器让人用起来很舒服,但是刚刚入手的童鞋可能会对其插件的安装产生一些恐惧,虽然vscode提供了插件的搜索和安装,但是其中一些插件是需要一些软件或者包之类的东西做支撑的,并不是在vs ...
- Django--网页管理实例解析
此篇为代码流程的注释以及自己写的小项目的思路: 首先是项目的路由配置: urlpatterns = [ # url(r'^admin/', admin.site.urls), url(r'^yemia ...