大话Spark(4)-一文理解MapReduce Shuffle和Spark Shuffle
Shuffle本意是 混洗, 洗牌的意思, 在MapReduce过程中需要各节点上同一类数据汇集到某一节点进行计算,把这些分布在不同节点的数据按照一定的规则聚集到一起的过程成为Shuffle.
在Hadoop的MapReduce框架中, Shuffle是连接Map和Reduce之间的桥梁, Map的数据要用到Reduce中必须经过Shuffle这个环节. 由于Shuffle涉及到磁盘的读写和网络的传输, 所以Shuffle的性能高低直接影响到整个程序的性能和吞吐量.
MapReduce中的Shuffle
 
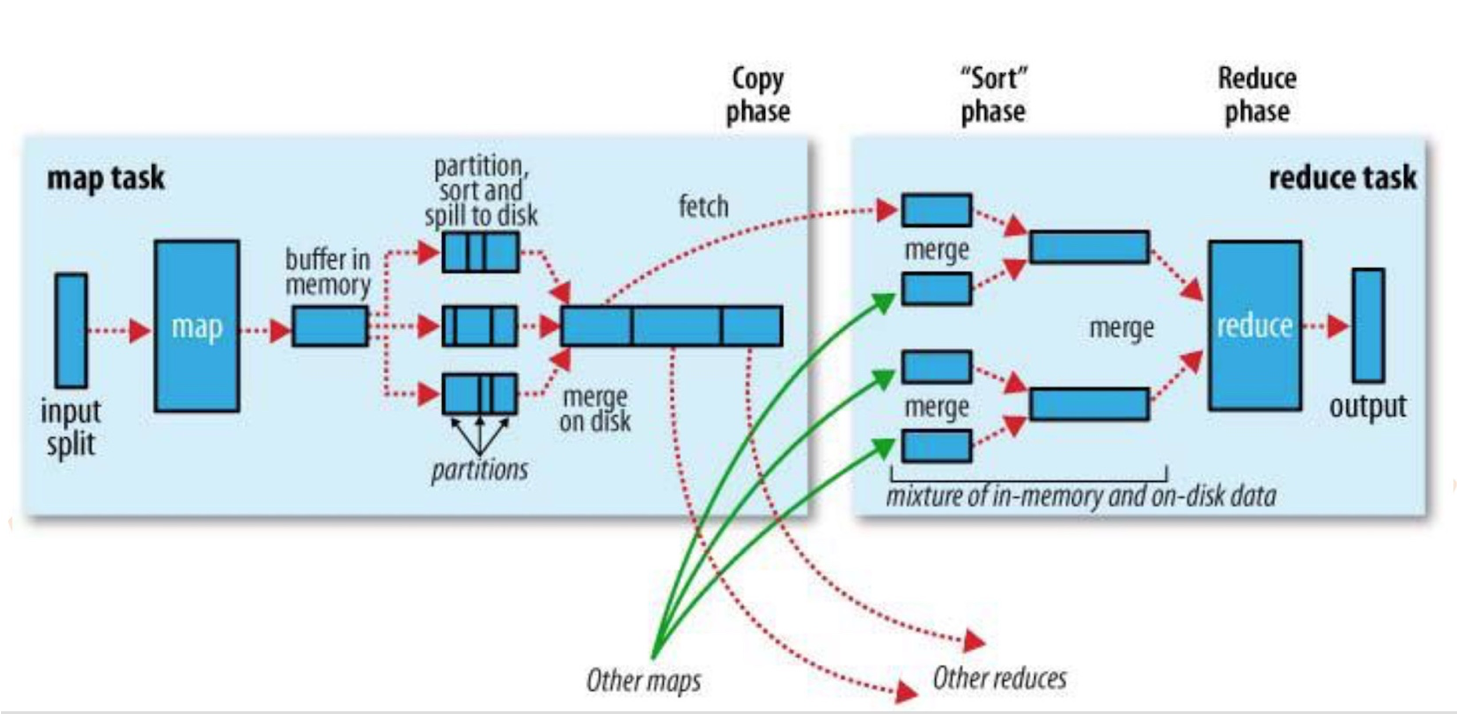
这张图是官网对Shuffle过程的描述,我们来分别看下map端和reduce端做了什么, 如何做的.
Map端
- map执行task时, 输入数据来源于HDFS的block, 在MapReduce概念中, map的task只读取split. split与block的对应关系可能是多对一, 默认是一对一.
- map在写磁盘之前, 会根据最终要传给的reduce把数据划分成相应的分区(partition). 每个分区中,后台线程按键进行排序,如果有combiner,它在排序后的输出上运行.(combiner可以使map的结果更紧凑,减少写磁盘的数据和传递给reduce的数据[省空间和io])
- map产生文件时, 并不是简单地将它写到磁盘. 它利用缓冲的方式把数据写到内存并处于效率的考虑进行与排序.(如图中 buffer in memory). 每一个map都有一个环形内存缓冲区用于存储任务输出.缓冲区大小默认100MB, 一旦达到阈值(默认80%), 一个后台线程便开始把内容溢出(split)到磁盘.(如果在此期间[split期间]缓冲区被填满,map会被阻塞,直到写磁盘过程完成.
- 每次内存缓冲区达到阈值移出,就会新建一个溢出文件(split file)(上图 partition,sort and split to disk). 因此在map任务最后一个记录输出之后,任务完成之前会把一出的多个文件合并成一个已分区且已排序的输出文件.(上图 merge on task)
Reduce端
- map的输出文件在map运行的机器的本地磁盘(reduce一般不写本地), map的输出文件包括多个分区需要的数据, reduce的输入需要集群上多个map的输出. 每个map的完成时间可能不同, 因此只要有一个map任务完成, reduce就开始复制其输出.(上图 fetch阶段) reduce有少量复制线程(默认5个),因此能够并行取得map输出(带宽瓶颈).
- reduce如何知道从哪台机器获取map结果? map执行完会通知master, reduce总有一个线程定期轮询master(心跳)可以获得map输出的位置. master会等到所有reduce完成之后再通知map删除其输出.
- 如果map的输出很小,会被复制到reduce任务jvm的内存.否则map输出会被复制到磁盘(又写磁盘)
- 复制完所有map输出后,reduce任务进入排序合并阶段(其实是合并阶段,因为map的输出上有序的).这个维持顺序的合并过程是循环进行的.(比如50个map输出,合并因子是10(默认值), 则合并将进行5次, 每次合并10个文件, 最终有5个中间文件)
- 在最后reduce阶段,直接把数据输入reduce函数(上面的5个中间文件不会再合并成一个已排序的中间文件). 输出直接写到文件系统, 一般为HDFS.
map输出为什么要排序?
- key存在combine操作,排序之后相同的key在一起方便合并.
- reduce按照key读数据时, 按照key的顺序去读, 遇到不一样的 key时即可知道之前的key的数据是否读取完毕. 如果没排序,则需要把全部数据都做处理.
上面就是MapReduce的Shuffle过程, 其实Spark2.0之后的Shuffle过程与MapReduce的基本一致,都是基于排序的,早期spark版本中的shuffle是基于hash的,让我们来一起看下.
Spark中的Shuffle
Spark有两种Shuffle机制. 一种是基于Hash的Shuffle, 还有一种是基于Sort的Shuffle.在Shuffle机制转变的过程中, 主要的一个优化点就是产生的小文件个数.
 
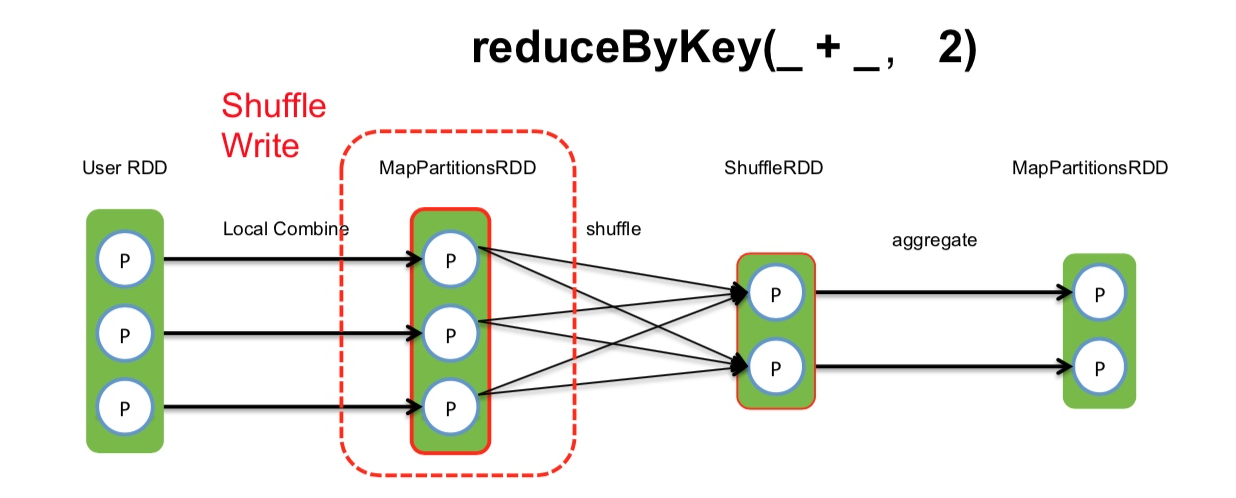
以上图为例,在Spark的算子reduceByKey(_ + _, 2)产生的shuffle中,我们先看Shuffle Write阶段.
Shuffle Write (Hash-based)

 

如图所示, hash-based的Shuffle, 每个map会根据reduce的个数创建对应的bucket, 那么bucket的总数量是: M * R (map的个数 * reduce的个数).
(假如分别有1k个map和reduce,将产生1百万的小文件!)
如上图所示,2个core, 4个map task, 3个reduce task 产生了4*3 = 12个小文件.(每个文件中是不排序的)
Shuffle Write (Hash-based) 优化!
由于hash-based产生的小文件太多, 对文件系统的压力很大, 后来做了优化.
把同一个core上的多个map输出到同一个文件. 这样文件数就变成了 core * R个.如下图: 
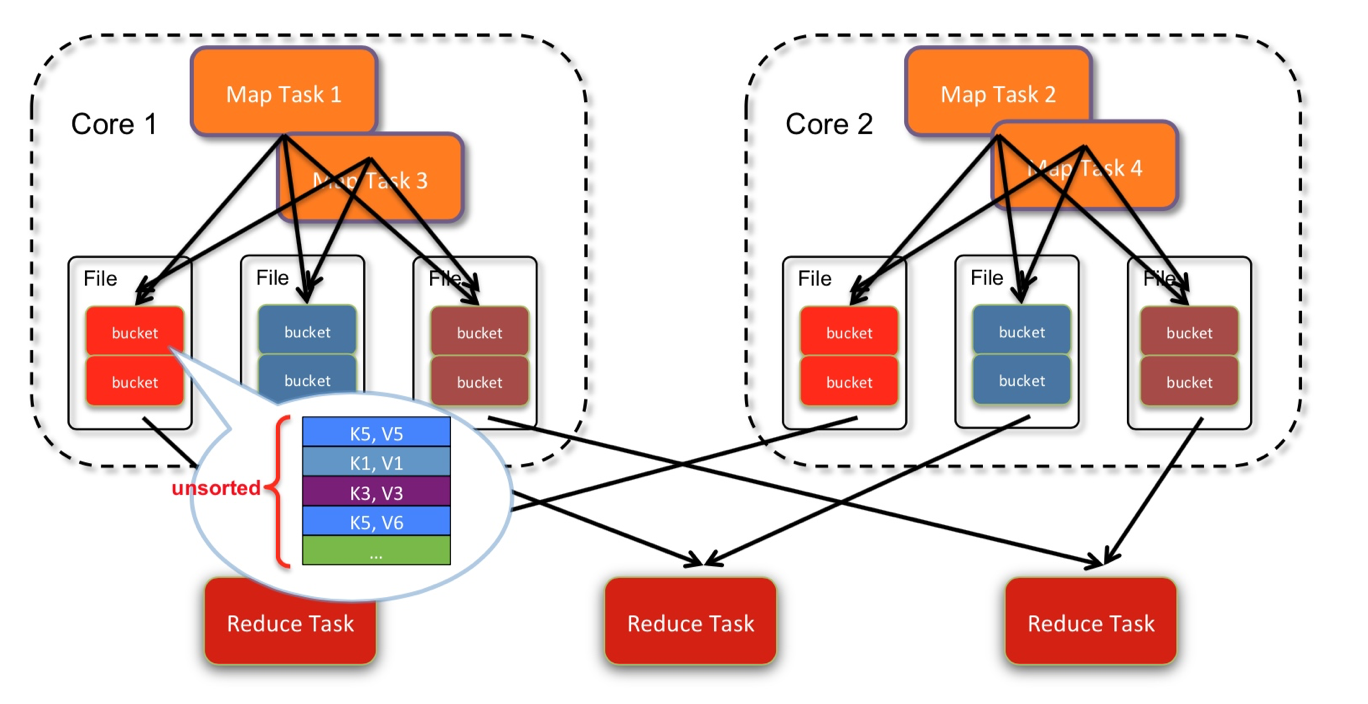
2个core, 4个map task, 3个 reduce task, 产生了2*3 = 6个文件.
(每个文件中仍然不是排序的)
Shuffle Write (Sort-based)
由于优化后的hash-based Shuffle的文件数为: core * R, 产生的小文件仍然过大, 所以引入了 sort-based Shuffle 

sort-based Shuffle中, 一个map task 输出一个文件.
文件在一些到磁盘之前, 会根据key进行排序. 排序后, 分批写入磁盘. task完成之后会将多次溢写的文件合并成一个文件. 由于一个task只对应一个磁盘文件, 因此还会单独写一份索引文件, 标识下游各个task的数据对应在文件中的起始和结束offset.
Shuffle Read

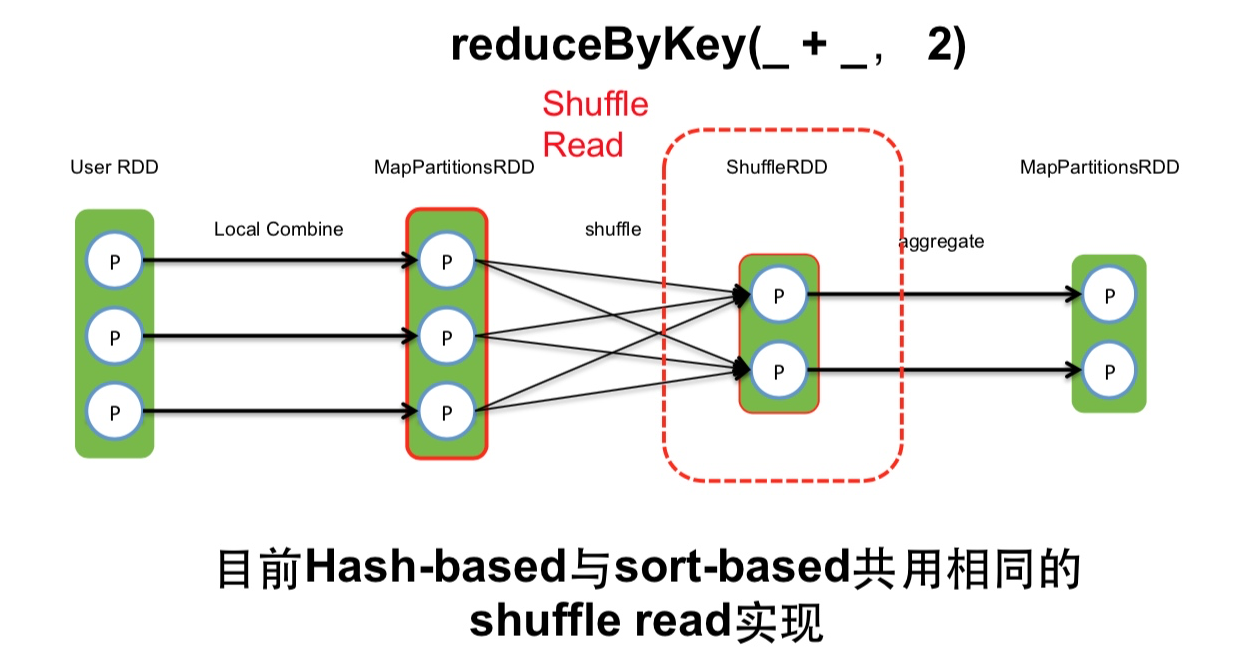
目前,hash-based 和 sort-based写方式公用相同的shuffle read.
如下图所示: 

shuffle read task从多个map的输出文件中fetch自己需要的已排序好的数据.
read task 会先从索引文件中获取自己需要的数据对应的索引, 在读文件的时候跳过对应的Block数据区, 只读当前自己这个task需要的数据.
什么时候开始fetch数据?
当 parent stage 的所有ShuffleMapTasks结束后再fetch(这里和MapReduce不同). 理论上讲, 一个ShuffleMapTask结束后就可以fetch, 但是为了迎合 stage 的概念(即一个stage如果其parent stages没有执行完,自己是不能被提交执行的),还是选择全部ShuffleMapTasks执行完再去 etch.因为fetch来的 FileSegments要先在内存做缓冲(默认48MB缓冲界限), 所以一次fetch的 FileSegments总大小不能太大. 一个 softBuffer里面一般包含多个 FileSegment,但如果某个FileSegment特别大的话, 这一个就可以填满甚至超过 softBuffer 的界限.
边 fetch 边处理还是一次性 fetch 完再处理?
边 fetch 边处理.本质上,MapReduce shuffle阶段就是边fetch边使用 combine()进行处理,只是combine()处理的是部分数据. MapReduce为了让进入 reduce()的records有序, 必须等到全部数据都shuffle-sort后再开始 reduce(). 因为Spark不要求shuffle后的数据全局有序,因此没必要等到全部数据 shuffle完成后再处理.
那么如何实现边shuffle边处理, 而且流入的records是无序的?答案是使用可以 aggregate 的数据结构, 比如 HashMap. 每从shuffle得到(从缓冲的 FileSegment中deserialize出来)一个 <key, value="">record, 直接将其放进 HashMap 里面.如果该HashMap已经存在相应的 Key. 那么直接进行 aggregate 也就是 func(hashMap.get(Key), Value).
Shuffle aggregate
shuffle read task拿到多个map产生的相同的key的数据后,需要对数据进行聚合,把相同key的数据放到一起,这个过程叫做aggregate. 

大致过程如下图:  

task把读来的 records 被逐个 aggreagte 到 HashMap 中,等到所有 records 都进入 HashMap,就得到最后的处理结果。
fetch 来的数据存放到哪里?
刚 fetch 来的 FileSegment 存放在 softBuffer 缓冲区,经过处理后的数据放在内存 + 磁盘上。
小结:
其实MapReduce Suffle 和 Spark的Shuffle在主要方面还是基本一致的, 比如:都是基于sort的.
细节上有一些区别, 比如 mapreduce完成一个map,就开始reduce, 而spark由于stage的概念,需要等所有ShuffleMap完成再ShuffleReduce.
大话Spark(4)-一文理解MapReduce Shuffle和Spark Shuffle的更多相关文章
- 大话Spark(3)-一图深入理解WordCount程序在Spark中的执行过程
本文以WordCount为例, 画图说明spark程序的执行过程 WordCount就是统计一段数据中每个单词出现的次数, 例如hello spark hello you 这段文本中hello出现2次 ...
- MapReduce Shuffle 和 Spark Shuffle 原理概述
Shuffle简介 Shuffle的本意是洗牌.混洗的意思,把一组有规则的数据尽量打乱成无规则的数据.而在MapReduce中,Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规 ...
- 彻底理解MapReduce shuffle过程原理
彻底理解MapReduce shuffle过程原理 MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapR ...
- MapReduce剖析笔记之一:从WordCount理解MapReduce的几个阶段
WordCount是一个入门的MapReduce程序(从src\examples\org\apache\hadoop\examples粘贴过来的): package org.apache.hadoop ...
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- 【Big Data - Hadoop - MapReduce】通过腾讯shuffle部署对shuffle过程进行详解
摘要: 通过腾讯shuffle部署对shuffle过程进行详解 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,TDW计算引擎包括两部分:MapReduce和Spark,两者内部都 ...
- Spark Shuffle之Sort Shuffle
源文件放在github,随着理解的深入,不断更新,如有谬误之处,欢迎指正.原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowled ...
- Spark 性能相关參数配置具体解释-shuffle篇
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 随着Spark的逐渐成熟完好, ...
- 理解MapReduce哲学
Google工程师将MapReduce定义为一般的数据处理流程.一直以来不能完全理解MapReduce的真义,为什么MapReduce可以“一般”? 最近在研究Spark,抛开Spark核心的内存计算 ...
随机推荐
- android静默安装和智能安装(转)
Android 静默安装和智能安装的实现方法 http://blog.csdn.net/fuchaosz/article/details/51852442 Android静默安装实现方案,仿360手机 ...
- adaboost python实现小样例
元算法是对其他算法进行组合的一种方式.单层决策树实际上是一个单节点的决策树.adaboost优点:泛化错误率低,易编码,可以应用在大部分分类器上,无参数调整缺点:对离群点敏感适用数据类型:数值型和标称 ...
- 【Interleaving String】cpp
题目: Given s1, s2, s3, find whether s3 is formed by the interleaving of s1 and s2. For example,Given: ...
- leetcode 【 Add Two Numbers 】 python 实现
题目: You are given two linked lists representing two non-negative numbers. The digits are stored in r ...
- 如何部署安装软件:vs2010 'VS' Inno Setup
一直以来就是调试程序,生成的文件在debug或者release下,当没有其他资源文件时,这些程序也不用打包,直接就能够运行,但是程序中总会有一些额外的资源文件,视频啊,图片啊.这些需要打包在一个安装文 ...
- Hive jdbc连接出现java.sql.SQLException: enabling autocommit is not supported
1.代码如下 String url = "jdbc:hive2://master135:10000/default"; String user = "root" ...
- [oldboy-django][2深入django]Form总结
1 form总结 # Form数据格式验证 - 原理: - 流程 a.写类LoginForm(Form): 字段名 = fields.xxFields() # 验证规则,本质是正则表达式(fields ...
- [oldboy-django][2深入django]后台生成form标签并设置标签的属性
# Form生成html标签 a. 通过Form生成Input输入框,Form标签,以及submit标签还是要在前端写的, 但是Form标签内的Input标签可以在后台实现:只需要按以下步骤 - vi ...
- sass和postcss
sass是css预处理器 需要安装node-sass支持 核心是c++编写 集成 sass-loader 把scss装换成css css-loader 找出@import和url()导入的语法,告诉w ...
- java 后台封装json数据学习总结(二)
一.JSONArray的应用 从json数组中得到相应java数组,如果要获取java数组中的元素,只需要遍历该数组. /* * 从json数组中得到相应java数组 * JSONArray下的toA ...