Spark Job的提交与task本地化分析(源码阅读八)
我们又都知道,Spark中任务的处理也要考虑数据的本地性(locality),Spark目前支持PROCESS_LOCAL(本地进程)、NODE_LOCAL(本地节点)、NODE_PREF、RACK_LOCAL(本地机架)、ANY(任何)几种。其他都很好理解,NODE_LOCAL会在spark日志中执行拉取数据所执行的task时,打印出来,因为Spark是移动计算,而不是移动数据的嘛。
那么什么是NODE_PREF?
当Driver应用程序刚刚启动,Driver分配获得的Executor很可能还没有初始化,所以有一部分任务的本地化级别被设置为NO_PREF.如果是ShuffleRDD,其本地性始终为NO_PREF。这两种本地化级别是NO_PREF的情况,在任务分配时会被优先分配到非本地节点执行,达到一定的优化效果。
那么下来我们从job的任务提交开始玩起~
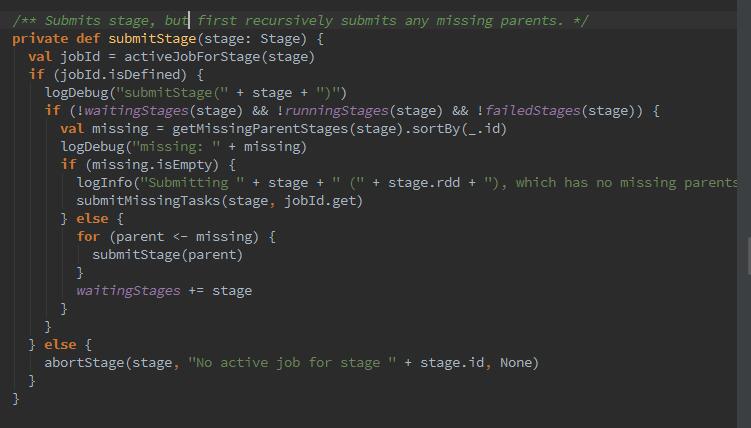
getMissingParentStages方法用来找到Stage的所有不可用的父Stage.从代码可以到这里是个递归的调用,submitWaitingStages实际上循环waitingStages中的stage并调用submitStaghe:
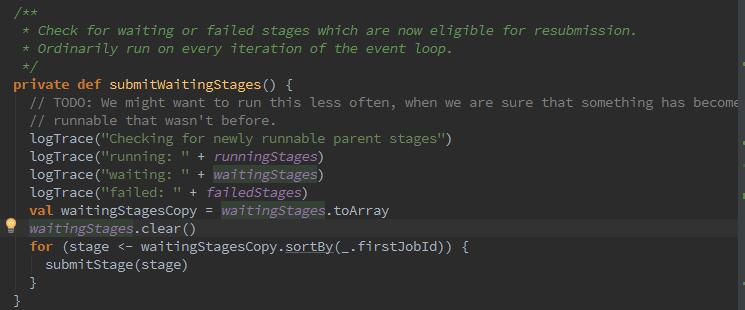
那么下来开始提交task,提交task的入口是submitMissingTasks,此函数在Stage没有可用的父stage时,被调用处理当前Stage未提交的任务。
1、那么在没有父stage时,会首先调用paendingPartitions.clear 用于清空pendingTasks.由于当前Stage的任务刚开始提交,所以需要清空,便于记录需要计算的任务。
2、将当前Stage加入运行中的Stage集合,是用HashSet进行构造的。
3、找出位计算的partition,如果Stage是map任务,那么outputLocs中partition对应的List为Nil,说明此partition还未计算。如果Stage不是map任务,那么需要获取stage的finalJob,调用finished方法判断每个partition的任务是否完成。
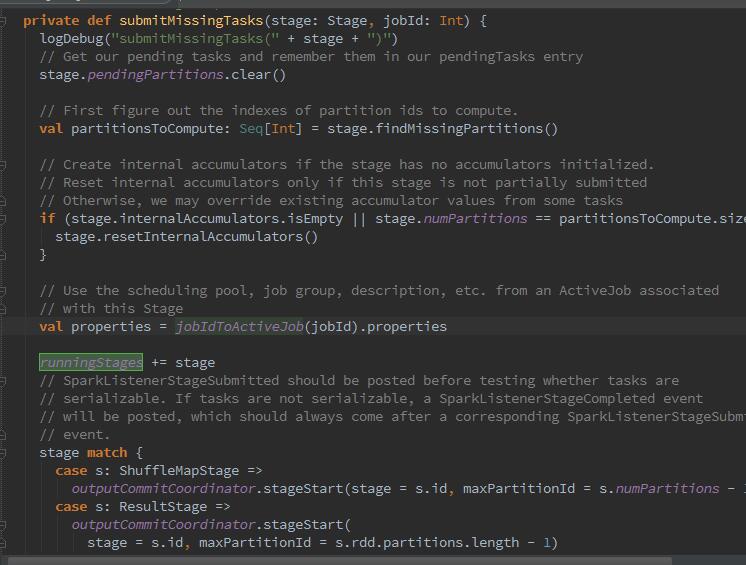
4、然后通过stage.makeNewStageAttemp,使用StageInfo.fromStage方法创建当前Stage的_latestInfo:
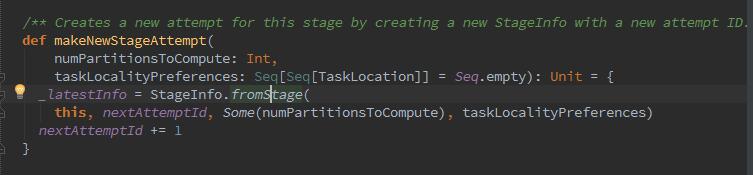
5、如果是Stage Map任务,那么序列化Stage的RDD及ShuffleDependency,如果Stage不是map任务,那么序列化Stage的RDD及resultOfJob的处理函数。最终这些序列化得到的字节数组需要用sc.broadcast进行广播。

6、最后,创建所有Task、当前stage的id、jobId等信息创建TaskSet,并调用taskScheduler的submitTasks,批量提交Stage及其所有Task.
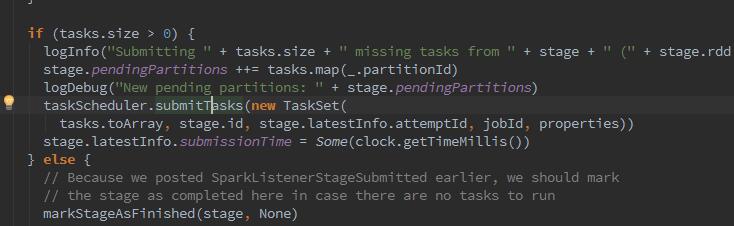
有可能同时有多个任务提交,所以就有了调度策略FIFO,那么下来调用LocalBackend的reviveOffers方法,向local-Actor发送ReviveOffers消息。localActor对ReviveOffers消息的匹配执行reviveOffers方法。调用TaskSchedulerImpl的resourceOffers方法分配资源,最后调用Executor的launchTask方法运行任务。
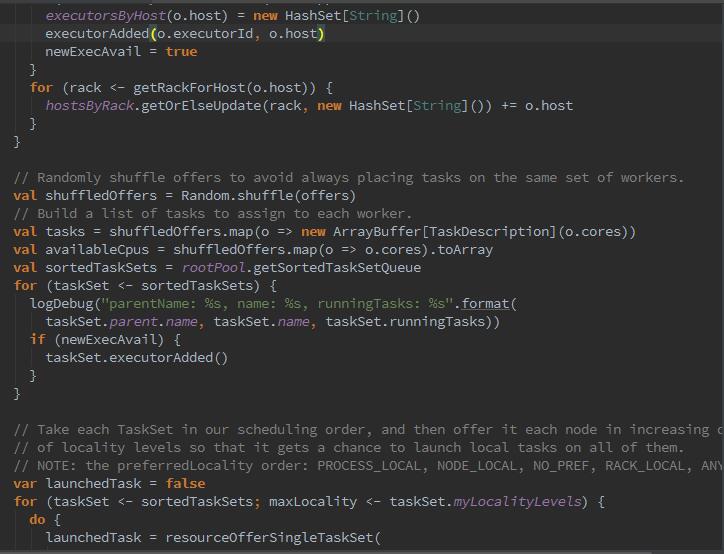
同时你会发现,这里有段代码,shuffleOffers = Random.shuffle(offers),是为了计算资源的分配与计算,对所有WorkerOffer随机洗牌,避免将任务总是分配给同样的WorkerOffer。
好了,知道了整个流程,下来我们来看一下本地化问题:

myLocalityLevles:当前TaskSetManager允许使用的本地化级别。那么这里的computeValidLocalityLevels方法是用于计算有效的本地化缓存级别。如果存在Executor中的有待执行的任务,且PROCESS_LOCAL本地化的等待时间不为0,且存在Executor已被激活,那么允许的本地化级别里包括PROCESS_LOCAL.
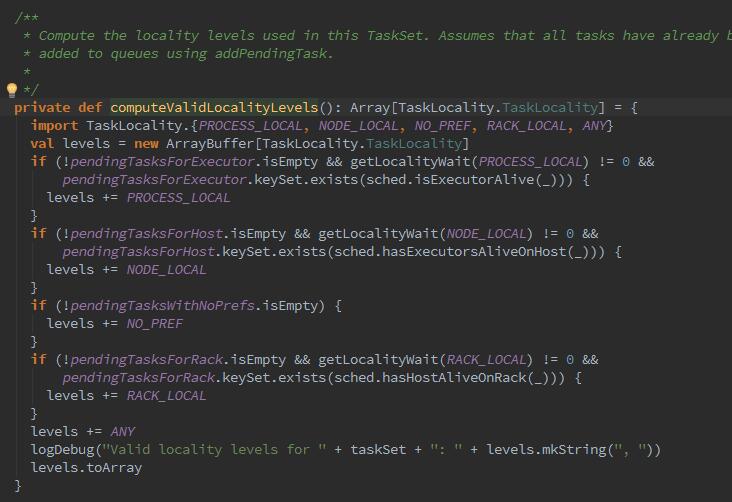
这里又发现新大陆,获取各个本地化级别的等待时间。
spark.locality.wait 本地化级别的默认等待时间
spark.locality.wait.process 本地进程的等待时间
spark.locality.wait.node 本地节点的等待时间
spark.locality.wait.rack 本地机架的等待时间
这些参数呢,在任务的运行很长且数量很多的情况下,适当调高这些参数可以显著提高性能,然而当这些参数值都已经超过任务的运行时长时,则需要调小这些参数。任何任务都希望被分配到可以从本地读取数据的节点上以得到最大的性能提升,然而每个任务的运行时长时不可预计的。当一个任务在分配时,如果没有满足最佳本地化(PROCESS_LOCAL)的资源时,如果固执的期盼得到最佳的资源,很可能被已经占用最佳资源但是运行时间很长的任务耽误,所以这些代码实现了当没有最佳本地化时,选择稍差点的资源。
参考文献:《深入理解Spark:核心思想与源码分析》
Spark Job的提交与task本地化分析(源码阅读八)的更多相关文章
- Spark BlockManager的通信及内存占用分析(源码阅读九)
之前阅读也有总结过Block的RPC服务是通过NettyBlockRpcServer提供打开,即下载Block文件的功能.然后在启动jbo的时候由Driver上的BlockManagerMaster对 ...
- Spark Job的提交与task本地化分析(源码阅读)
Spark中任务的处理也要考虑数据的本地性(locality),Spark目前支持PROCESS_LOCAL(本地进程).NODE_LOCAL(本地节点).NODE_PREF.RACK_LOCAL(本 ...
- vuex源码阅读分析
这几天忙啊,有绝地求生要上分,英雄联盟新赛季需要上分,就懒着什么也没写,很惭愧.这个vuex,vue-router,vue的源码我半个月前就看的差不多了,但是懒,哈哈.下面是vuex的源码分析在分析源 ...
- Spark源码阅读之存储体系--存储体系概述与shuffle服务
一.概述 根据<深入理解Spark:核心思想与源码分析>一书,结合最新的spark源代码master分支进行源码阅读,对新版本的代码加上自己的一些理解,如有错误,希望指出. 1.块管理器B ...
- Flink源码分析 - 源码构建
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483692&idx=1&sn=18cddc1ee ...
- 【Azure 应用服务】Azure Function App使用SendGrid发送邮件遇见异常消息The operation was canceled,分析源码逐步最终源端
问题描述 在使用Azure Function App的SendGrid Binging功能,调用SendGrid服务器发送邮件功能时,有时候遇见间歇性,偶发性异常.在重新触发SendGrid部分的Fu ...
- 鸿蒙内核源码分析(源码结构篇) | 内核每个文件的含义 | 百篇博客分析OpenHarmony源码 | v18.04
百篇博客系列篇.本篇为: v18.xx 鸿蒙内核源码分析(源码结构篇) | 内核每个文件的含义 | 51.c.h .o 前因后果相关篇为: v08.xx 鸿蒙内核源码分析(总目录) | 百万汉字注解 ...
- java分析源码-ReentrantLock
一.前言 在分析了 AbstractQueuedSynchronier 源码后,接着分析ReentrantLock源码,其实在 AbstractQueuedSynchronizer 的分析中,已经提到 ...
- easyloader [easyui_1.4.2] 分析源码,妙手偶得之
用easyui很久了,但是很少去看源码. 有解决不了的问题就去百度... 今日发现,easyui的源码不难懂. 而且结合 easyloader 可以非常方便的逐个研究easyui的组件. 但是, ea ...
随机推荐
- Caused by: java.lang.NoClassDefFoundError:
tomcat启动不了 报错信息头如下: Caused by: java.lang.NoClassDefFoundError: at java.lang.Class.getDeclaredMethods ...
- PHP易混淆函数的区分方法及意义
1.echo和print的区别 PHP中echo和print的功能基本相同(输出),但是两者之间还是有细微差别的.echo输出后没有返回值,但print有返回值,当其执行失败时返回flase.因此 ...
- Win10(win7) 安装vs2015(2012)出现ASP.NET 4.0/4.5 尚未在 Web 服务器上注册 下载这个补丁安装就可以了
url:https://www.microsoft.com/zh-cn/download/details.aspx?id=44907&a03ffa40-ca8b-4f73-0358-c191d ...
- 浅谈 HTTPS 和 SSL/TLS 协议的背景与基础
来自:编程随想 >> 相关背景知识 要说清楚 HTTPS 协议的实现原理,至少需要如下几个背景知识. 大致了解几个基本术语(HTTPS.SSL.TLS)的含义 大致了解 HTTP 和 ...
- linux sed的使用
sed是一个很好的文件处理工具,本身是一个管道命令,主要是以行为单位进行处理, 可以将数据行进行替换.删除.新增.选取等特定工作. sed本质上是一个编辑器,但是它是非交互式的,这点与VIM不同:同时 ...
- data process for large scale datasets
Kmeans: 总体而言,速度(单线程): yael_kmeans > litekmeans ~ vl_kmeans 1.vl_kemans (win10 + matlab 15 + vs1 ...
- 解决Cannot delete or update a parent row: a foreign key constraint fails (`current_source_products`.`product_storage`, CONSTRAINT `product_storage_ibfk_3` FOREIGN KEY (`InOperatorID`)
出现这个异常的原因是因为设置了外键,造成无法更新或删除数据. 1.通过设置FOREIGN_KEY_CHECKS变量来避免这种情况 删除前设置 SET FOREIGN_KEY_CHECKS=0; 删除完 ...
- .gitignore失效问题解决
.gitignore失效背景: 本地Mac上使用Unity新建了一个项目,使用git init将项目初始化为仓库,此时commit.随后,加入.gitignore文件,再次commit.然后提交整个仓 ...
- jquery 无缝滚动 jquery.kxbdmarquee
DEMO http://code.ciaoca.com/jquery/kxbdmarquee/demo/ 官网 http://code.ciaoca.com/jquery/kxbdmarquee/ D ...
- Joomla及其类似软件的说明分析
Joomla不单单是一款免费的软件,还是在国外相当知名的及内容管理.web开发及手机应用开发等为一体的一套系统.Joomla是使用PHP语言加上MySQL数据库所开发的软件系统,可以在Linux. W ...