C++高并发场景下读多写少的解决方案
C++高并发场景下读多写少的解决方案
概述
一谈到高并发的解决方案,往往能想到模块水平拆分、数据库读写分离、分库分表,加缓存、加mq等,这些都是从系统架构上解决。单模块作为系统的组成单元,其性能好坏也能很大的影响整体性能,本文从单模块下读多写少的场景出发,探讨其解决方案,以其更好的实现高并发。
不同的业务场景,读和写的频率各有侧重,有两种常见的业务场景:
- 读多写少:典型场景如广告检索端、白名单更新维护、loadbalancer
- 读少写多:典型场景如qps统计
本文针对读多写少(也称一写多读)场景下遇到的问题进行分析,并探讨一种合适的解决方案。
分析
读多写少的场景,服务大部分情况下都是处于读,而且要求读的耗时不能太长,一般是毫秒或者更低的级别;更新的频率就不是那么频繁,如几秒钟更新一次。通过简单的加互斥锁,腾出一片临界区,往往能到达预期的效果,保证数据更新正确。
 @w=300@h=300
@w=300@h=300
但是,只要加了锁,就会带来竞争,即使加的是读写锁,虽然读之间不互斥,但写一样会影响读,而且读写同时争夺锁的时候,锁优先分配给写(读写锁的特性)。例如,写的时候,要求所有的读请求阻塞住,等到写线程或协程释放锁之后才能读。如果写的临界区耗时比较大,则所有的读请求都会受影响,从监控图上看,这时候会有一根很尖的耗时毛刺,所有的读请求都在队列中等待处理,如果在下个更新周期来之前,服务能处理完这些读请求,可能情况没那么糟糕。但极端情况下,如果下个更新周期来了,读请求还没处理完,就会形成一个恶性循环,不断的有读请求在队列中等待,最终导致队列被挤满,服务出现假死,情况再恶劣一点的话,上游服务发现某个节点假死后,由于负载均衡策略,一般会重试请求其他节点,这时候其他节点的压力跟着增加了,最终导致整个系统出现雪崩。
因此,加锁在高并发场景下要尽量避免,如果避免不了,需要让锁的粒度尽量小,接近无锁(lock-free)更好,简单的对一大片临界区加锁,在高并发场景下不是一种合适的解决方案
双缓冲
有一种数据结构叫双缓冲,其这种数据结构很常见,例如显示屏的显示原理,显示屏显示的当前帧,下一帧已经在后台的buffer准备好,等时间周期一到,就直接替换前台帧,这样能做到无卡顿的刷新,其实现的指导思想是空间换时间,这种数据结构的工作原理如下:
- 数据分为前台和后台
- 所有读线程读前台数据,不用加锁,通过一个指针来指向当前读的前台数据
- 只有一个线程负责更新,更新的时候,先准备好后台数据,接着直接切指针,这之后所有新进来的读请求都看到了新的前台数据
- 有部分读还落在老的前台那里处理,因为更新还不算完成,也就不能退出写线程,写线程需要等待所有落在老前台的线程读完成后,才能退出,在退出之前,顺便再更新一遍老前台数据(也就当前的新后台),可以保证前后台数据一致,这点在做增量更新的时候有用
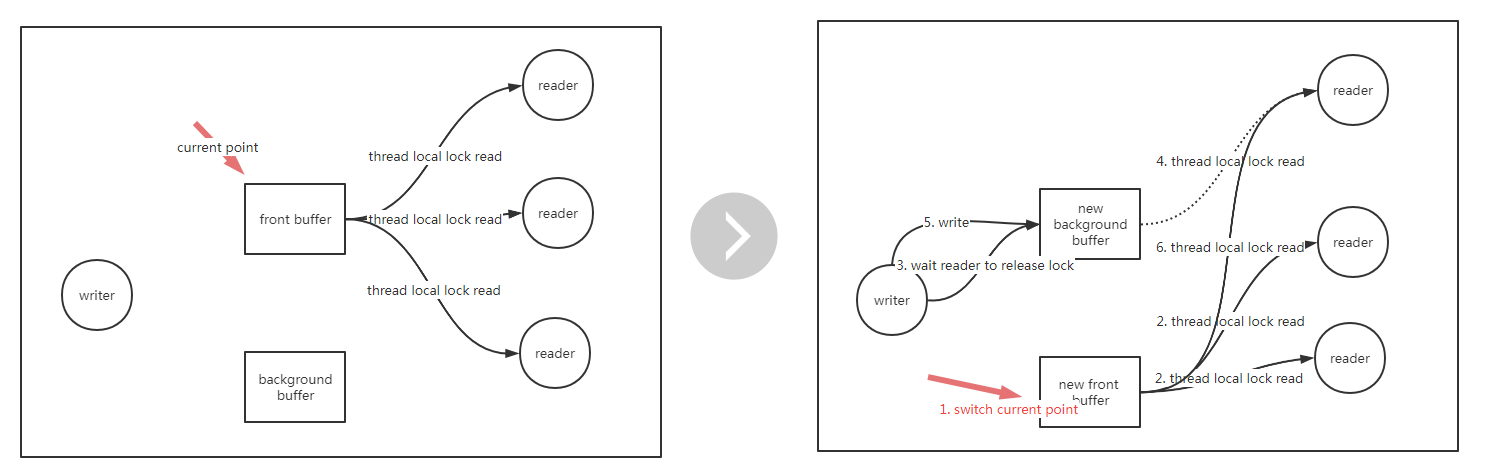
工程实现上需要攻克的难点
- 写线程要怎么知道所有的读线程在老前台中的读完成了呢?
一种做法是让各个读线程都维护一把锁,读的时候锁住,这时候不会影响其他线程的读,但会影响写,读完后释放锁(某些时候可能会有通知写线程的开销,但写本身很少),写线程只需要确认锁有没有释放了,确认完了后马上释放,确认这个动作非常快(小于25ns,1s=103ms=106us=10^9ns),读线程几乎不会感觉到锁的存在。 - 每个线程都有一把自己的锁,需要用全局的map来做线程id和锁的映射吗?
不需要,而且这样做全局map就要加全局锁了,又回到了刚开始分析中遇到的问题了。其实,每个线程可以有私有存储(thread local storage,简称TLS),如果是协程,就对应这协程的TLS(但对于go语言,官方是不支持TLS的,想实现类似功能,要么就想办法获取到TLS,要么就不要基于协程锁,而是用全局锁,但尽量让锁粒度小,本文主要针对C++语言,暂时不深入讨论其他语言的实现)。这样每个读线程锁的是自己的锁,不会影响到其他的读线程,锁的目的仅仅是为了保证读优先。
对于线程私有存储,可以使用pthread_key_create, pthread_setspecific,pthread_getspecific系列函数
核心代码实现
读
template <typename T, typename TLS>
int DoublyBufferedData<T, TLS>::Read(
typename DoublyBufferedData<T, TLS>::ScopedPtr* ptr) { // ScopedPtr析构的时候,会释放锁
Wrapper* w = static_cast<Wrapper*>(pthread_getspecific(_wrapper_key)); // 非首次读,获取pthread local lock
if (BAIDU_LIKELY(w != NULL)) {
w->BeginRead(); // 锁住
ptr->_data = UnsafeRead();
ptr->_w = w;
return 0;
}
w = AddWrapper();
if (BAIDU_LIKELY(w != NULL)) {
const int rc = pthread_setspecific(_wrapper_key, w); // 首次读,设置pthread local lock
if (rc == 0) {
w->BeginRead();
ptr->_data = UnsafeRead();
ptr->_w = w;
return 0;
}
}
return -1;
}
写
template <typename T, typename TLS>
template <typename Fn>
size_t DoublyBufferedData<T, TLS>::Modify(Fn& fn) {
BAIDU_SCOPED_LOCK(_modify_mutex); // 加锁,保证只有一个写
int bg_index = !_index.load(butil::memory_order_relaxed); // 指向后台buffer
const size_t ret = fn(_data[bg_index]); // 修改后台buffer
if (!ret) {
return 0;
}
// 切指针
_index.store(bg_index, butil::memory_order_release);
bg_index = !bg_index;
// 等所有读老前台的线程读结束
{
BAIDU_SCOPED_LOCK(_wrappers_mutex);
for (size_t i = 0; i < _wrappers.size(); ++i) {
_wrappers[i]->WaitReadDone();
}
}
// 确认没有读了,直接修改新后台数据,对其新前台
const size_t ret2 = fn(_data[bg_index]);
return ret2;
}
完整实现请参考brpc的DoublyBufferData
简单说说golang中双缓冲的实现
普通的双缓冲加载实现
基于计数器,用atomic,保证原子性,读进入临界区,计数器+1,退出-1,写判断计数器为0则切换,但计数器是全局锁。这种方案C++也可以采取,只是计数器毕竟也是全局锁,性能会差那么一丢丢。即使用智能指针shared_ptr,也会面临智能指针引用计数互斥的问题。之所以用计数器,而不用TLS,是因为go不支持TLS,对比TLS版本和计数器版本,TLS性能更优,因为没有抢计数器的互斥问题,但抢计数器本身很快,性能没测试过,可以试试。
sync.Map的实现
也是基于计数器,只是计数器是为了让读前台缓存失效的概率不要太高,有抑制和收敛的作用,实现了读的无锁,少部分情况下,前台缓存读不到数据的时候,会去读后台缓存,这时候也要加锁,同时计数器+1。计数器数值达到一定程度(超过后台缓存的元素个数),就执行切换
是否适用于读少写多的场景
不合适,双缓冲优先保证读的性能,写多读少的场景需要优先保证写的性能。
相关文献
brpc对于双buffer的描述:https://www.bookstack.cn/read/incubator-brpc/3c7745da34a1418b.md#DoublyBufferedData
go实现的双buffer(但读是互斥的,性能先对较差):http://blog.codeg.cn/2016/01/27/double-buffering/
双buffer的三种实现方案:https://juejin.cn/post/6844904130989801479
一写多读:https://blog.csdn.net/lqt641/article/details/55058137
高并发下的系统设计:https://www.cnblogs.com/flame540/p/12817529.html
基于计数器的实现:https://www.cnblogs.com/gaoxingnjiagoutansuo/p/15773361.html#4998436
C++高并发场景下读多写少的解决方案的更多相关文章
- C++高并发场景下读多写少的优化方案
概述 一谈到高并发的优化方案,往往能想到模块水平拆分.数据库读写分离.分库分表,加缓存.加mq等,这些都是从系统架构上解决.单模块作为系统的组成单元,其性能好坏也能很大的影响整体性能,本文从单模块下读 ...
- HttpClient在高并发场景下的优化实战
在项目中使用HttpClient可能是很普遍,尤其在当下微服务大火形势下,如果服务之间是http调用就少不了跟http客户端找交道.由于项目用户规模不同以及应用场景不同,很多时候可能不需要特别处理也. ...
- Qunar机票技术部就有一个全年很关键的一个指标:搜索缓存命中率,当时已经做到了>99.7%。再往后,每提高0.1%,优化难度成指数级增长了。哪怕是千分之一,也直接影响用户体验,影响每天上万张机票的销售额。 在高并发场景下,提供了保证线程安全的对象、方法。比如经典的ConcurrentHashMap,它比起HashMap,有更小粒度的锁,并发读写性能更好。线程安全的StringBuilder取代S
Qunar机票技术部就有一个全年很关键的一个指标:搜索缓存命中率,当时已经做到了>99.7%.再往后,每提高0.1%,优化难度成指数级增长了.哪怕是千分之一,也直接影响用户体验,影响每天上万张机 ...
- 【转】记录PHP、MySQL在高并发场景下产生的一次事故
看了一篇网友日志,感觉工作中值得借鉴,原文如下: 事故描述 在一次项目中,上线了一新功能之后,陆陆续续的有客服向我们反应,有用户的个别道具数量高达42亿,但是当时一直没有到证据表示这是,确实存在,并且 ...
- 高并发场景下System.currentTimeMillis()的性能问题的优化 以及SnowFlakeIdWorker高性能ID生成器
package xxx; import java.sql.Timestamp; import java.util.concurrent.*; import java.util.concurrent.a ...
- 高并发场景下System.currentTimeMillis()的性能问题的优化
高并发场景下System.currentTimeMillis()的性能问题的优化 package cn.ucaner.alpaca.common.util.key; import java.sql.T ...
- 高并发场景下System.currentTimeMillis()的性能优化
一.前言 System.currentTimeMillis()的调用比new一个普通对象要耗时的多(具体耗时高出多少我也不知道,不过听说在100倍左右),然而该方法又是一个常用方法, 有时不得不使用, ...
- MySQL在大数据、高并发场景下的SQL语句优化和"最佳实践"
本文主要针对中小型应用或网站,重点探讨日常程序开发中SQL语句的优化问题,所谓“大数据”.“高并发”仅针对中小型应用而言,专业的数据库运维大神请无视.以下实践为个人在实际开发工作中,针对相对“大数据” ...
- 高并发场景下JVM调优实践之路
一.背景 2021年2月,收到反馈,视频APP某核心接口高峰期响应慢,影响用户体验. 通过监控发现,接口响应慢主要是P99耗时高引起的,怀疑与该服务的GC有关,该服务典型的一个实例GC表现如下图: 可 ...
随机推荐
- 一个超好用的 Python 标准库,彻底玩透路径操作
pathlib 学习 Python 时,尤其是在进行文件操作和数据处理时,经常会处理路径问题.最常用和常见的是 os.path 模块,它将路径当做字符串进行处理,如果使用不当可能导致难以察觉的错误,而 ...
- Python用xlrd读取Excel数据到list中再用xlwt把数据写入到新的Excel中
一.先用xlrd读取Excel数据到list列表中(存入列表中的数据如下图所示) import xlrd as xd #导入需要的包 import xlwt data =xd.open_workboo ...
- C51单片机中断实验
实验要求: 要求通过中断方式检测有无按键 判断哪个按键(编号0-9),并且在数码管上显示对应的0-9 代码部分 #include<reg51.h> char led_mod[]={0x3f ...
- TFTP协议介绍-python实现tftp客户端
1. TFTP协议介绍 TFTP(Trivial File Transfer Protocol,简单文件传输协议) 是TCP/IP协议族中的一个用来在客户端与服务器之间进行简单文件传输的协议 特点: ...
- SpringCloud微服务实战——搭建企业级开发框架(三十五):SpringCloud + Docker + k8s实现微服务集群打包部署-集群环境部署
一.集群环境规划配置 生产环境不要使用一主多从,要使用多主多从.这里使用三台主机进行测试一台Master(172.16.20.111),两台Node(172.16.20.112和172.16.20.1 ...
- css实现hover显示下拉菜单
原理比较简单,首先先隐藏下拉菜单即display:none,当鼠标hover后,设置display:block. <style> .menu-title { postion: relati ...
- Chrome导出导入书签
Chrome导出标签 Chrome导入书签
- 手把手教你如何使用 webpack5 的模块联邦新特性
想象一下,在webpack5还没出来前,前端使用第三方组件库,例如使用 dayjs 日期处理库,都是通过 npm i dayjs -s 安装 dayjs 模块到项目里,然后就可以通过 require ...
- 【九度OJ】题目1473:二进制数 解题报告
[九度OJ]题目1473:二进制数 解题报告 标签(空格分隔): 九度OJ http://ac.jobdu.com/problem.php?pid=1473 题目描述: 大家都知道,数据在计算机里中存 ...
- 【LeetCode】709. To Lower Case 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述: 题目大意 解题方法 ASIIC码操作 日期 题目地址:https:// ...