附: Python爬虫 数据库保存数据
1.笔记
#-*- codeing = utf-8 -*-
#@Time : 2020/7/15 22:49
#@Author : HUGBOY
#@File : hello_sqlite3.py
#@Software: PyCharm
'''---------------|Briefing|------------------
sqlite3
——a new way to save data !
------------------------------------'''
import sqlite3
#连接
print("Connect code:")
# conn = sqlite3.connect("sql.database")#创建/打开数据库文件
#
# c = conn.cursor()#获取游标
#
# sql = '''
# create table company
# (id int primary key not null,
# name text not null,
# age int not null,
# address char(58),
# salary real);
# ''' #三个点多行语句
#
# #第一次创建 c.execute(sql)#执行sql语句
#
# conn.commit()#提交保存
#
# print("建表成功!")
#
# conn.close()#关闭数据库
2.实例
效果
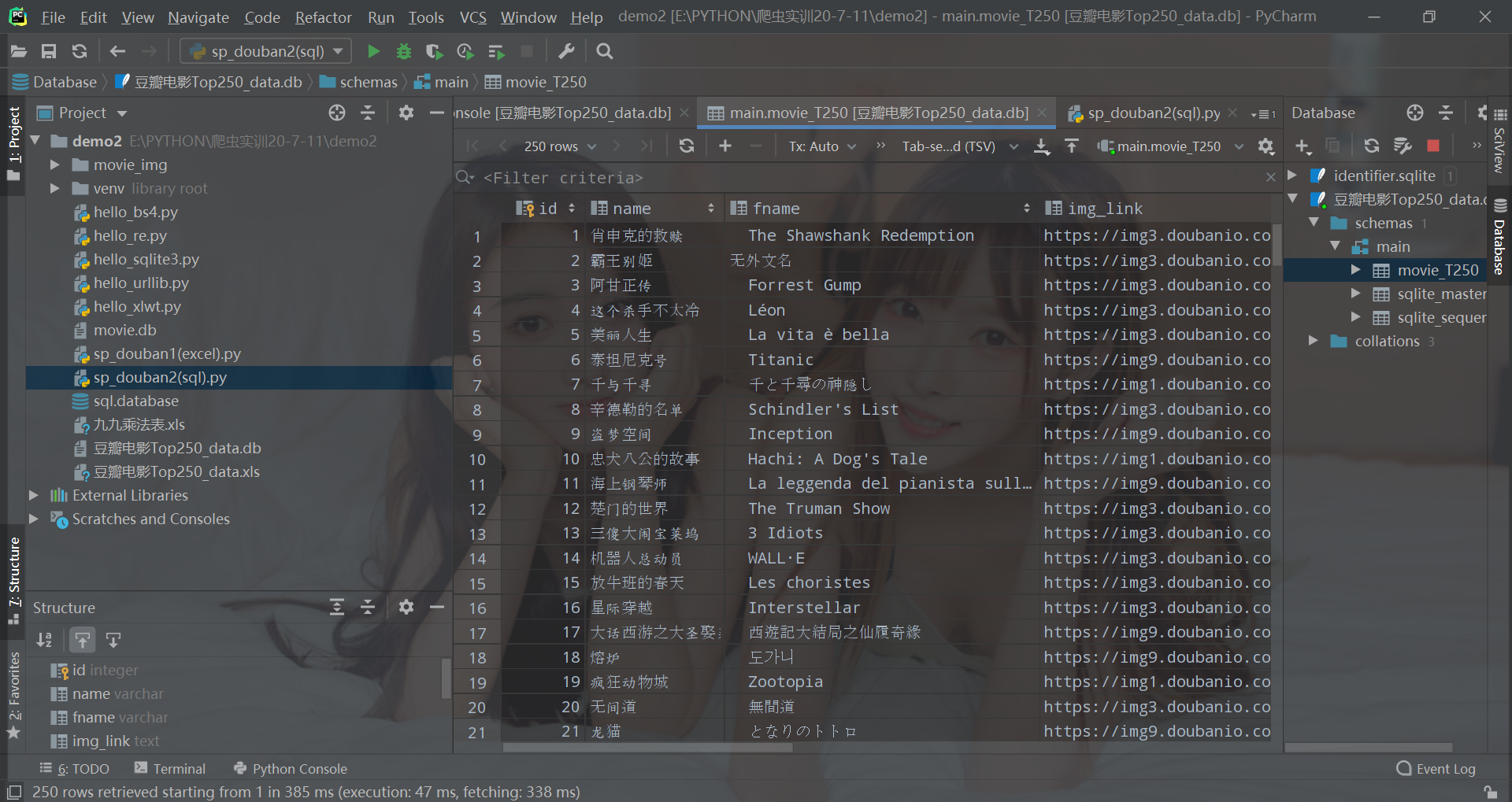
原码
#-*- codeing = utf-8 -*-
#@Time : 2020/7/16 12:12
#@Author : HUGBOY
#@File : sp_douban2(sql).py
#@Software: PyCharm
# -*- codeing = utf-8 -*-
# @Time : 2020/7/12 19:11
# @Author : HUGBOY
# @File : sp_douban1(excel).py
# @Software: PyCharm
'''----------------------|简介|------------------
#爬虫
#爬取豆瓣TOP250电影数据
#1.爬取网页
#2.逐一解析数据
#3.保存数据
----------------------------------------------'''
from bs4 import BeautifulSoup # 网页解析、获取数据
import re # 正则表达式
import urllib.request, urllib.error # 指定URL、获取网页数据
import random
import xlwt # 存到excel的操作
import sqlite3 # 存到数据库操作
import os
from urllib.request import urlretrieve#保存电影海报图
def main():
baseurl = "https://movie.douban.com/top250/?start="
datalist = getdata(baseurl)
#savepath = ".\\豆瓣电影Top250_data.xls"
#savedata(datalist,savepath)
dbpath = ("豆瓣电影Top250_data.db")
savedata(datalist,dbpath)
# 正则表达式匹配规则
findTitle = re.compile(r'<span class="title">(.*)</span>') # 影片片名
findR = re.compile(r'<span class="inq">(.*)</span>') # 一句话评
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') # 影片评分
findPeople = re.compile(r'<span>(\d*)人评价</span>') # 影评人数-/d 代表数字
findLink = re.compile(r'<a href="(.*?)">') # 影片链接
findImg = re.compile(r'<img.*src="(.*?)"', re.S) # 影片图片-re.S 允许.中含换行符
findBd = re.compile(r'<p class="">(.*?)</p>', re.S) # 影片简介
def getdata(baseurl):
datalist = []
getimg = 0
for i in range(0, 10): # 调用获取页面信息的函数*10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页原码
# 解析网页
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):
# print(item) #一部电影的所有信息
data = []
item = str(item)
# 提取影片详细信息
title = re.findall(findTitle, item)
if (len(title) == 2):
ctitle = title[0] # 中文名
data.append(ctitle)
otitle = title[1].replace("/", "") # 外文名-去掉'/'和""
data.append(otitle)
else:
data.append(title[0])
data.append("无外文名")
img = re.findall(findImg, item)[0]
data.append(img)
'''--------------------
爬取图片
--------------------'''
os.makedirs('./movie_img/', exist_ok=True)#创建保存目录
getimg+=1
str_getimg = str(getimg)
#格式 urlretrieve(IMAGE_URL, './img/image1.png')
urlretrieve(img, './movie_img/img'+str_getimg+'.png')
link = re.findall(findLink, item)[0] # re库:正则表达式找指定字符串
data.append(link)
rating = re.findall(findRating, item)[0]
data.append(rating)
people = re.findall(findPeople, item)[0]
data.append(people)
r = re.findall(findR, item)
if len(r) != 0:
r = r[0].replace("。", "")
data.append(r)
else:
data.append("无一句评")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd) # 替换</br>
bd = re.sub('/', " ", bd) # 替换/
data.append(bd.strip()) # 去掉空格
datalist.append(data) # 把一部电影信息存储
#print(datalist)
return datalist
# 得到指定Url网页内容
def askURL(url):
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0"}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html) 测试
except Exception as rel:
if hasattr(rel, "code"):
print(rel.code)
if hasattr(rel, "reason"):
print(rel.reason)
return html
def savedata(datalist,dbpath):
print("save data in sql ...")
create_db(dbpath)
conn = sqlite3.connect(dbpath)
c = conn.cursor()
for data in datalist:
for index in range(len(data)):
if index==4 or index==5:#score rated 类型为numeric
continue
data[index]='"'+data[index]+'"'
sql = '''
insert into movie_T250
(
name,fname,img_link,film_link,score,rated,one_cont,instroduction
)
values(%s)'''%",".join(data)
c.execute(sql)
conn.commit()
c.close()
conn.close()
def create_db(dbpath):
sql='''
create table movie_T250
(
id integer primary key autoincrement,
name varchar,
fname varchar,
img_link text,
film_link text,
score numeric,
rated numeric,
one_cont text,
instroduction text
);
'''
conn = sqlite3.connect(dbpath)
c = conn.cursor()
c.execute(sql)
conn.commit()
c.close()
print("create table success !")
if __name__ == "__main__":
main()
print("爬取完成,奥利给!")
附: Python爬虫 数据库保存数据的更多相关文章
- python查询数据库返回数据
python查询数据库返回数据主要运用到flask框架,pymysql 和 json‘插件’ #!/usr/bin/python # -*- coding: UTF-8 -*- import pymy ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- python爬虫26 | 把数据爬取下来之后就存储到你的MySQL数据库。
小帅b说过 在这几篇中会着重说说将爬取下来的数据进行存储 上次我们说了一种 csv 的存储方式 这次主要来说说怎么将爬取下来的数据保存到 MySQL 数据库 接下来就是 学习python的正确姿势 真 ...
- Python爬虫之三种数据解析方式
一.引入 二.回顾requests实现数据爬取的流程 指定url 基于requests模块发起请求 获取响应对象中的数据 进行持久化存储 其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需 ...
- python从数据库取数据后写入excel 使用pandas.ExcelWriter设置单元格格式
用python从数据库中取到数据后,写入excel中做成自动报表,ExcelWrite默认的格式一般来说都比较丑,但workbook提供可以设置自定义格式,简单记录个demo,供初次使用者参考. 一. ...
- python爬虫——抖音数据
最近挺火的抖音短视频,不仅带火了一众主播,连不少做电商的也进驻其中,于是今天我来扒一扒这火的不要不要的抖音数据: 一.抓包工具获取用户ID 对于手机app数据,抓包是最直接也是最常见的手段,常用的抓包 ...
- python爬虫系列之数据的存储(二):csv库的使用
上一篇我们讲了怎么用 json格式保存数据,这一篇我们来看看如何用 csv模块进行数据读写. 一.csv简介 CSV (Comma Separated Values),即逗号分隔值(也称字符分隔值,因 ...
- python爬虫:将数据保存到本地
一.python语句存储 1.with open()语句 with open(name,mode,encoding) as file: file.write() name:包含文件名称的字符串; mo ...
- 【原创】python爬虫获取网站数据并存入本地数据库
#coding=utf-8 import urllib import re import MySQLdb dbnumber = MySQLdb.connect('localhost', 'root', ...
随机推荐
- 让你的程序炫起来!少有人知道但超酷的 Python 进度条开源库
本文适合有 Python 基础的朋友 本文作者:HelloGitHub-Anthony HelloGitHub 推出的<讲解开源项目>系列,本期介绍让你快速拥有完美进度条的 Python ...
- elementui 表格格式化
<el-table-column prop="userType" label="角色" width="180" :formatter= ...
- Mybatis-plus 上
Mybatis-plus 上 简介 1.什么是Mybatis-plus MyBatis-Plus(简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发 ...
- SAP QM 检验批跳号解决
SAP QM 检验批跳号解决 在生产系统中,发现存在检验批规则或不规则跳号问题. 首先,查看事务代码SNRO编号范围对象QLOSE中BUFFER字段值,将其设置为NO BUFFER(无缓冲) 如果还存 ...
- JVM调试命令简介
1.JPS(查JAVA进程) 2.jinfo(查看正在运行java应用程序的扩展参数,包括Java System属性和JVM命令行参数:也可以动态的修改正在运行的JVM一些参数) 大部分的运行期参数是 ...
- 分布式锁的实现之 redis 篇
为什么需要分布式锁 引入经典的秒杀情景,100件商品供客户抢.如果是单机版的话,我们使用synchronized 或者 lock 都可以实现线程安全.但是如果多个服务器的话,synchronized ...
- 1.7.3- HTML表格属性
- 【JVM】空间分配担保机制
抛几个问题: 1.谁进行空间担保? JVM使用分代收集算法,将堆内存划分为年轻代和老年代,两块内存分别采用不同的垃圾回收算法,空间担保指的是老年代进行空间分配担保 2.什么是空间分配担保? 在发生Mi ...
- hdu1261 JAVA
题意: 一个A和两个B一共可以组成三种字符串:"ABB","BAB","BBA".给定若干字母和它们相应的个数,计算一共可以组成多少个不同的 ...
- 路由器逆向分析------QEMU的下载和安装(Linux平台)
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/68953160 一.QEMU源码的下载和编译 QEMU源码的github下载地址:h ...