Elasticsearch(ES)分词器的那些事儿
1. 概述
分词器是Elasticsearch中很重要的一个组件,用来将一段文本分析成一个一个的词,Elasticsearch再根据这些词去做倒排索引。
今天我们就来聊聊分词器的相关知识。
2. 内置分词器
2.1 概述
Elasticsearch 中内置了一些分词器,这些分词器只能对英文进行分词处理,无法将中文的词识别出来。
2.2 内置分词器介绍
standard:标准分词器,是Elasticsearch中默认的分词器,可以拆分英文单词,大写字母统一转换成小写。
simple:按非字母的字符分词,例如:数字、标点符号、特殊字符等,会去掉非字母的词,大写字母统一转换成小写。
whitespace:简单按照空格进行分词,相当于按照空格split了一下,大写字母不会转换成小写。
stop:会去掉无意义的词,例如:the、a、an 等,大写字母统一转换成小写。
keyword:不拆分,整个文本当作一个词。
2.3 查看分词效果通用接口
GET http://192.168.1.11:9200/_analyze
参数:
{
"analyzer": "standard",
"text": "I am a man."
}
响应:
{
"tokens": [
{
"token": "i",
"start_offset": 0,
"end_offset": 1,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "am",
"start_offset": 2,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "a",
"start_offset": 5,
"end_offset": 6,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "man",
"start_offset": 7,
"end_offset": 10,
"type": "<ALPHANUM>",
"position": 3
}
]
}
3. IK分词器
3.1 概述
Elasticsearch中内置的分词器不能对中文进行分词,因此我们需要再安装一个能够支持中文的分词器,IK分词器就是个不错的选择。
3.2 下载IK分词器
下载网址:https://github.com/medcl/elasticsearch-analysis-ik
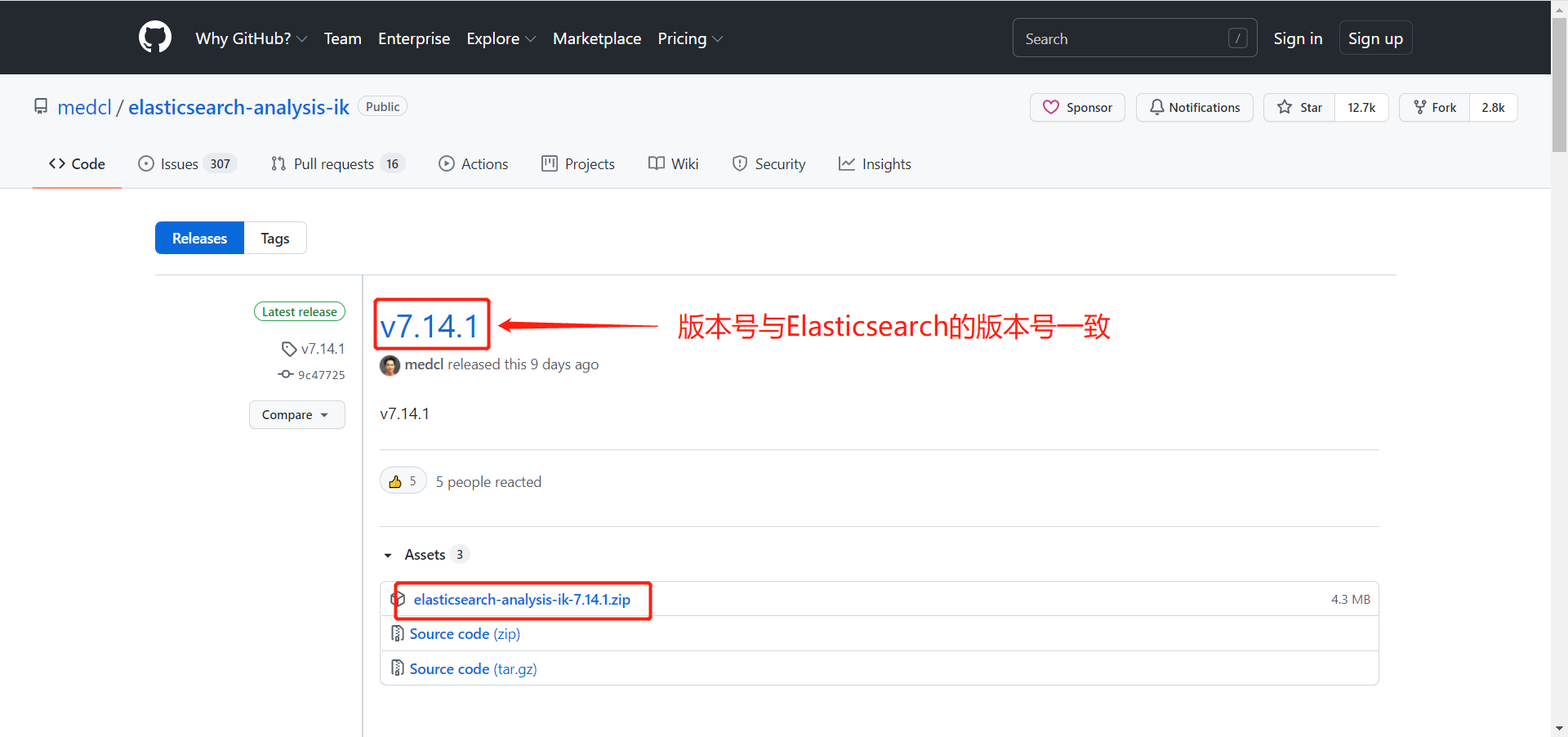
3.3 IK分词器的安装
1)为IK分词器创建目录
# cd /usr/local/elasticsearch-7.14.1/plugins
# mkdir ik
2)将IK分词器压缩包拷贝到CentOS7的目录下,例如:/home
3)将压缩包解压到刚刚创建的目录
# unzip elasticsearch-analysis-ik-7.14.1.zip -d /usr/local/elasticsearch-7.14.1/plugins/ik/
4)重启Elasticsearch
3.4 IK分词器介绍
ik_max_word: 会将文本做最细粒度的拆分,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,适合 Phrase 查询。
IK分词器介绍来源于GitHub:https://github.com/medcl/elasticsearch-analysis-ik
3.5 分词效果
GET http://192.168.1.11:9200/_analyze
参数:
{
"analyzer": "ik_max_word",
"text": "我是一名Java高级程序员"
}
响应:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "一名",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "一",
"start_offset": 2,
"end_offset": 3,
"type": "TYPE_CNUM",
"position": 3
},
{
"token": "名",
"start_offset": 3,
"end_offset": 4,
"type": "COUNT",
"position": 4
},
{
"token": "java",
"start_offset": 4,
"end_offset": 8,
"type": "ENGLISH",
"position": 5
},
{
"token": "高级",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 6
},
{
"token": "程序员",
"start_offset": 10,
"end_offset": 13,
"type": "CN_WORD",
"position": 7
},
{
"token": "程序",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 8
},
{
"token": "员",
"start_offset": 12,
"end_offset": 13,
"type": "CN_CHAR",
"position": 9
}
]
}
4. 自定义词库
4.1 概述
在进行中文分词时,经常出现分析出的词不是我们想要的,这时我们就需要在IK分词器中自定义我们自己词库。
例如:追风人,分词后,只有 追风 和 人,而没有 追风人,导致倒排索引后查询时,用户搜 追风 或 人 可以搜到 追风人,搜 追风人 反而搜不到 追风人。
4.2 自定义词库
# cd /usr/local/elasticsearch-7.14.1/plugins/ik/config
# vi IKAnalyzer.cfg.xml
在配置文件中增加自己的字典

# vi my.dic
在文本中加入 追风人,保存。
重启Elasticsearch即可。
5. 综述
今天简单聊了一下 Elasticsearch(ES)分词器的相关知识,希望可以对大家的工作有所帮助。
欢迎大家帮忙点赞、评论、加关注 :)
关注追风人聊Java,每天更新Java干货。
Elasticsearch(ES)分词器的那些事儿的更多相关文章
- elasticsearch kibana + 分词器安装详细步骤
elasticsearch kibana + 分词器安装详细步骤 一.准备环境 系统:Centos7 JDK安装包:jdk-8u191-linux-x64.tar.gz ES安装包:elasticse ...
- Elasticsearch之分词器的作用
前提 什么是倒排索引? Analyzer(分词器)的作用是把一段文本中的词按一定规则进行切分.对应的是Analyzer类,这是一个抽象类,切分词的具体规则是由子类实现的,所以对于不同的语言,要用不同的 ...
- Elasticsearch之分词器的工作流程
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch的分词器的一般工作流程: 1.切分关键词 2.去除停用词 3.对于英文单词,把所有字母转为小写(搜索时不区分 ...
- Elasticsearch修改分词器以及自定义分词器
Elasticsearch修改分词器以及自定义分词器 参考博客:https://blog.csdn.net/shuimofengyang/article/details/88973597
- ES 09 - 定制Elasticsearch的分词器 (自定义分词策略)
目录 1 索引的分析 1.1 分析器的组成 1.2 倒排索引的核心原理-normalization 2 ES的默认分词器 3 修改分词器 4 定制分词器 4.1 向索引中添加自定义的分词器 4.2 测 ...
- 【分词器及自定义】Elasticsearch中文分词器及自定义分词器
中文分词器 在lunix下执行下列命令,可以看到本来应该按照中文”北京大学”来查询结果es将其分拆为”北”,”京”,”大”,”学”四个汉字,这显然不符合我的预期.这是因为Es默认的是英文分词器我需要为 ...
- elasticsearch中文分词器(ik)配置
elasticsearch默认的分词:http://localhost:9200/userinfo/_analyze?analyzer=standard&pretty=true&tex ...
- elasticsearch 分析器 分词器
参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html 在全文搜索(Fu ...
- ElasticSearch中分词器组件配置详解
首先要明确一点,ElasticSearch是基于Lucene的,它的很多基础性组件,都是由Apache Lucene提供的,而es则提供了更高层次的封装以及分布式方面的增强与扩展. 所以要想熟练的掌握 ...
随机推荐
- CentOS帮助类语法
目录 一.man获取帮助信息 二.help获得shell内置命令的帮助信息 三.history查看所有命令历史 补充:Linux常用快捷键 一.man获取帮助信息 基本语法:man [命令或配置文件] ...
- Special Forms and Syntax Sugars in Clojure
(...): function literals, p40, 64; '(...): suppress evaluation, p24; _(...): comments, p18; ".. ...
- git只提交部分修改的文件(提交指定文件)
在我们的项目中,经常会在本地编译一些代码,还未写完,测试那边来告诉你要改改某个文件的bug,非常着急,此时改完了,提交的时候,自己还在编译的代码并不想提交,此时,你可以利用git这些指令帮助你! 1/ ...
- SpringBoot开发一
项目介绍 牛客高级项目课,主要是完成牛客网的讨论社区的搭建.项目在github上. 涉及到的技术架构: Spring,SpringBoot,SpringMVC,MyBatis,Redis,Kafka( ...
- MySQL JOIN的使用
JOIN的使用 JOIN 理论 MySQL 七种 JOIN 的 SQL 编写 环境搭建 # 创建部门表 CREATE TABLE tbl_dept ( id INT NOT NULL AUTO_INC ...
- Java - Enum 枚举类型
目录 前言 应用 定义 基本Enum特性 Enum的静态导入 Enum中添加新方法 Switch语句中的Enum Enum的继承 EnumSet的使用 EnumMap的使用 常量相关方法 枚举值向枚举 ...
- C#协作试取消线程
https://segmentfault.com/q/1010000017109927using System; using System.Collections.Generic; using Sys ...
- 如何在github上传本地项目代码
首先你要在github上申请一个账号 网址:https://github.com/ 然后你要下载一个git工具 网址:https://gitforwindows.org/ 进入官网直接下载就行,下载完 ...
- HDFS简介及基本概念
(一)HDFS简介及其基本概念 HDFS(Hadoop Distributed File System)是hadoop生态系统的一个重要组成部分,是hadoop中的的存储组件,在整个Hadoop中 ...
- 【java虚拟机】常用的jvm配置参数
转自:https://www.cnblogs.com/pony1223/p/8661219.html 零.在IDE的后台打印GC日志: 既然学习JVM,阅读GC日志是处理Java虚拟机内存问题的基础技 ...