MinkowskiPooling池化(下)
MinkowskiPooling池化(下)
MinkowskiPoolingTranspose
class MinkowskiEngine.MinkowskiPoolingTranspose(kernel_size, stride, dilation=1, kernel_generator=None, dimension=None)
稀疏张量的池转置层。
展开功能,然后将其除以贡献的非零元素的数量。
__init__(kernel_size, stride, dilation=1, kernel_generator=None, dimension=None)
用于稀疏张量的高维解卷层。
Args:
kernel_size (int, optional): 输出张量中内核的大小。如果未提供,则region_offset应该是 RegionType.CUSTOM并且region_offset应该是具有大小的2D矩阵N×D 这样它列出了所有D维度的 N 偏移量。.
stride (int, or list, optional): stride size of the convolution layer. If non-identity is used, the output coordinates will be at least stride ×× tensor_stride away. When a list is given, the length must be D; each element will be used for stride size for the specific axis.
dilation (int, or list, optional): 卷积内核的扩展大小。给出列表时,长度必须为D,并且每个元素都是轴特定的膨胀。所有元素必须> 0。
kernel_generator (MinkowskiEngine.KernelGenerator, optional): 定义自定义内核形状。
dimension(int):定义所有输入和网络的空间的空间尺寸。例如,图像在2D空间中,网格和3D形状在3D空间中。
cpu() → T
将所有模型参数和缓冲区移至CPU。
返回值:
模块:selfcuda(device: Optional[Union[int, torch.device]] = None) → T
将所有模型参数和缓冲区移至GPU。
这也使关联的参数并缓冲不同的对象。因此,在构建优化程序之前,如果模块在优化过程中可以在GPU上运行,则应调用它。
参数:
设备(整数,可选):如果指定,则所有参数均为
复制到该设备
返回值:
模块:self
double() →T
将所有浮点参数和缓冲区强制转换为double数据类型。
返回值:
模块:self
float() →T
将所有浮点参数和缓冲区强制转换为float数据类型。
返回值:
模块:self
forward(input: SparseTensor.SparseTensor, coords: Union[torch.IntTensor, MinkowskiCoords.CoordsKey, SparseTensor.SparseTensor] = None)
input (MinkowskiEngine.SparseTensor): Input sparse tensor to apply a convolution on.
coords ((torch.IntTensor, MinkowskiEngine.CoordsKey, MinkowskiEngine.SparseTensor), optional): If provided, generate results on the provided coordinates. None by default.
to(*args, **kwargs)
Moves and/or casts the parameters and buffers.
This can be called as
to(device=None, dtype=None, non_blocking=False)
to(dtype, non_blocking=False)
to(tensor, non_blocking=False)
to(memory_format=torch.channels_last)
其签名类似于torch.Tensor.to(),但仅接受所需dtype的浮点s。另外,此方法将仅将浮点参数和缓冲区强制转换为dtype (如果给定的话)。device如果给定了整数参数和缓冲区 ,但dtype不变。当 non_blocking被设置时,它试图转换/如果可能异步相对于移动到主机,例如,移动CPU张量与固定内存到CUDA设备。
请参见下面的示例。
Args:
device (torch.device): the desired device of the parameters
and buffers in this module
dtype (torch.dtype): the desired floating point type of
the floating point parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
memory_format (torch.memory_format): the desired memory
format for 4D parameters and buffers in this module (keyword only argument)
Returns:
Module: self
Example:
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16)
type(dst_type: Union[torch.dtype, str]) → T
Casts all parameters and buffers to dst_type.
Arguments:
dst_type (type or string): the desired type
Returns:
Module: self
MinkowskiGlobalPooling
class MinkowskiEngine.MinkowskiGlobalPooling(average=True, mode=<GlobalPoolingMode.AUTO: 0>)
将所有输入功能集中到一个输出。
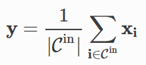
将稀疏坐标减少到原点,即将每个点云减少到原点,返回batch_size点的数量[[0,0,…,0],[0,0,…,1] ,, [0, 0,…,2]],其中坐标的最后一个元素是批处理索引。
Args:
average (bool): 当为True时,返回平均输出。如果不是,则返回所有输入要素的总和。
cpu() → T
将所有模型参数和缓冲区移至CPU。
返回值:
模块:自我
Module: self
cuda(device: Optional[Union[int, torch.device]] = None) → T
将所有模型参数和缓冲区移至GPU。
这也使关联的参数并缓冲不同的对象。因此,在构建优化程序之前,如果模块在优化过程中可以在GPU上运行,则应调用它。
参数:
device (int, optional): if specified, all parameters will be
copied to that device
Returns:
Module: self
double() → T
将所有浮点参数和缓冲区强制转换为double数据类型。
Returns:
Module: self
float() → T
将所有浮点参数和缓冲区强制转换为float数据类型。
返回值:
模块:self
forward(input)
to(*args, **kwargs)
移动和/或强制转换参数和缓冲区。
这可以称为
to(device=None, dtype=None, non_blocking=False)
to(dtype, non_blocking=False)
to(tensor, non_blocking=False)
to(memory_format=torch.channels_last)
其签名类似于torch.Tensor.to(),但仅接受所需dtype的浮点s。另外,此方法将仅将浮点参数和缓冲区强制转换为dtype (如果给定的话)。device如果给定了整数参数和缓冲区 ,dtype不变。当 non_blocking被设置时,它试图转换/如果可能异步相对于移动到主机,例如,移动CPU张量与固定内存到CUDA设备。
请参见下面的示例。
Args:
device (torch.device): the desired device of the parameters
and buffers in this module
dtype (torch.dtype): the desired floating point type of
the floating point parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
memory_format (torch.memory_format): the desired memory
format for 4D parameters and buffers in this module (keyword only argument)
Returns:
Module: self
Example:
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16)
type(dst_type: Union[torch.dtype, str]) → T
Casts all parameters and buffers to dst_type.
Arguments:
dst_type (type or string): the desired type
Returns:
Module: self
MinkowskiPooling池化(下)的更多相关文章
- MinkowskiPooling池化(上)
MinkowskiPooling池化(上) 如果内核大小等于跨步大小(例如kernel_size = [2,1],跨步= [2,1]),则引擎将更快地生成与池化函数相对应的输入输出映射. 如果使用U网 ...
- 卷积和池化的区别、图像的上采样(upsampling)与下采样(subsampled)
1.卷积 当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去. ...
- 【小白学PyTorch】21 Keras的API详解(下)池化、Normalization层
文章来自微信公众号:[机器学习炼丹术].作者WX:cyx645016617. 参考目录: 目录 1 池化层 1.1 最大池化层 1.2 平均池化层 1.3 全局最大池化层 1.4 全局平均池化层 2 ...
- 测试EntityFramework,Z.EntityFramework.Extensions,原生语句在不同的查询中的表现。原来池化与非池化设定是有巨大的影响的。
Insert测试,只测试1000条的情况,多了在实际的项目中应该就要另行处理了. using System; using System.Collections.Generic; using Syste ...
- 由浅入深了解Thrift之客户端连接池化
一.问题描述 在上一篇<由浅入深了解Thrift之服务模型和序列化机制>文章中,我们已经了解了thrift的基本架构和网络服务模型的优缺点.如今的互联网圈中,RPC服务化的思想如火如荼.我 ...
- Deep Learning 学习随记(七)Convolution and Pooling --卷积和池化
图像大小与参数个数: 前面几章都是针对小图像块处理的,这一章则是针对大图像进行处理的.两者在这的区别还是很明显的,小图像(如8*8,MINIST的28*28)可以采用全连接的方式(即输入层和隐含层直接 ...
- 池化 - Apache Commons Pool
对于那些创建耗时较长,或者资源占用较多的对象,比如网络连接,线程之类的资源,通常使用池化来管理这些对象,从而达到提高性能的目的.比如数据库连接池(c3p0, dbcp), java的线程池 Execu ...
- 对象池化技术 org.apache.commons.pool
恰当地使用对象池化技术,可以有效地减少对象生成和初始化时的消耗,提高系统的运行效率.Jakarta Commons Pool组件提供了一整套用于实现对象池化的框架,以及若干种各具特色的对象池实现,可以 ...
- 高可用的池化 Thrift Client 实现(源码分享)
本文将分享一个高可用的池化 Thrift Client 及其源码实现,欢迎阅读源码(Github)并使用,同时欢迎提出宝贵的意见和建议,本人将持续完善. 本文的主要目标读者是对 Thrift 有一定了 ...
随机推荐
- DVWA之Command Injection
Command Injection Command Injection,即命令注入,是指通过提交恶意构造的参数破坏命令语句结构,从而达到执行恶意命令的目的.PHP命令注入攻击漏洞是PHP应用程序中常见 ...
- SMTP、POP3和IMAP邮件协议
目录 SMTP POP IMAP 总结 DNS记录中的MX记录 今天入职第一天,公司让配置个人的内网.外网邮箱,这可把我给搞晕了,本来以前就对邮箱这块不是很了解,平时也不怎么用邮箱,顶多有个QQ邮箱而 ...
- PHP 上传文件至阿里云OSS对象存储
简述 1.阿里云开通对象存储服务 OSS 并创建Bucket 2.下载PHP SDK至框架扩展目录,点我下载 3.码上code 阿里云操作 开通对象存储服务 OSS 创建 Bucket 配置Acces ...
- java.lang.NoSuchMethodError: org.springframework.util.Assert.state(ZLjava/util/function/Supplier;)V
更多精彩见微信公众号 at org.springframework.test.context.support.AbstractTestContextBootstrapper.buildMergedCo ...
- HashMap 的数据结构
目录 content append content HashMap 的数据结构: 数组 + 链表(Java7 之前包括 Java7) 数组 + 链表 + 红黑树(从 Java8 开始) PS:这里的& ...
- Nginx超详细常用功能演示,够用啦~~~
前言 Nginx("engine x")是一款是由俄罗斯的程序设计师Igor Sysoev所开发高性能的 Web和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服 ...
- Python 基础教程 —— Pandas 库常用方法实例说明
目录 1. 常用方法 pandas.Series 2. pandas.DataFrame ([data],[index]) 根据行建立数据 3. pandas.DataFrame ({dic}) ...
- 关于flume中涉及到时间戳的错误解决,Expected timestamp in the Flume even
在搭建flume集群收集日志写入hdfs时发生了下面的错误: java.lang.NullPointerException: Expected timestamp in the Flume event ...
- 使用chrony安装chrony
yum install chrony -y 使用chrony安装chrony 使用root用户登录~]# yum install chrony 默认的chrony进程位置/usr/sbin/c ...
- C++课程设计 通讯录管理系统 原码及解析
设计题目:通信录管理系统 用C++设计出模拟手机通信录管理系统,实现对手机中的通信录进行管理. (一)功能要求 查看功能:选择此功能时,列出下列三类选择. A 办公类B 个人类C 商务类,当选中某类时 ...