Java IO学习笔记二:DirectByteBuffer与HeapByteBuffer
作者:Grey
原文地址:Java IO学习笔记二:DirectByteBuffer与HeapByteBuffer
ByteBuffer.allocate()与ByteBuffer.allocateDirect()的基本使用
这两个API封装了一个统一的ByteBuffer返回值,在使用上是无差别的。
import java.nio.ByteBuffer;
public class TestByteBuffer {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
System.out.println("position: " + buffer.position());
System.out.println("limit: " + buffer.limit());
System.out.println("capacity: " + buffer.capacity());
System.out.println("mark: " + buffer);
buffer.put("123".getBytes());
System.out.println("-------------put:123......");
System.out.println("mark: " + buffer);
buffer.flip();
System.out.println("-------------flip......");
System.out.println("mark: " + buffer);
buffer.get();
System.out.println("-------------get......");
System.out.println("mark: " + buffer);
buffer.compact();
System.out.println("-------------compact......");
System.out.println("mark: " + buffer);
buffer.clear();
System.out.println("-------------clear......");
System.out.println("mark: " + buffer);
}
}
输出结果是:
mark: java.nio.DirectByteBuffer[pos=0 lim=1024 cap=1024]
-------------put:123......
mark: java.nio.DirectByteBuffer[pos=3 lim=1024 cap=1024]
-------------flip......
mark: java.nio.DirectByteBuffer[pos=0 lim=3 cap=1024]
-------------get......
mark: java.nio.DirectByteBuffer[pos=1 lim=3 cap=1024]
-------------compact......
mark: java.nio.DirectByteBuffer[pos=2 lim=1024 cap=1024]
-------------clear......
mark: java.nio.DirectByteBuffer[pos=0 lim=1024 cap=1024]
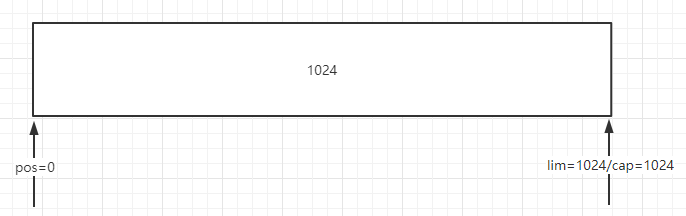
当分配好1024空间后,未对ByteBuffer做任何操作的时候,position最初就是0位置,limit和capcity都是1024位置,如图:
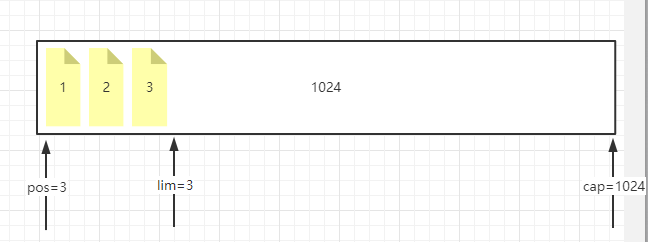
当put进去123三个字符以后:

执行flip后,pos会回到原点,lim会到目前写入的位置,这个方法主要用于读取数据:
调用get方法,拿出一个byte,如下图:

调用compact,会把前面拿掉的1个Byte位置填充:

调用clear会让整个内存回到初始分配状态:

ByteBuffer.allocate()与ByteBuffer.allocateDirect()方法的区别
可以参考:
Ron Hitches in his excellent book Java NIO seems to offer what I thought could be a good answer to your question:
Operating systems perform I/O operations on memory areas. These memory areas, as far as the operating system is concerned, are contiguous sequences of bytes. It's no surprise then that only byte buffers are eligible to participate in I/O operations. Also recall that the operating system will directly access the address space of the process, in this case the JVM process, to transfer the data. This means that memory areas that are targets of I/O perations must be contiguous sequences of bytes. In the JVM, an array of bytes may not be stored contiguously in memory, or the Garbage Collector could move it at any time. Arrays are objects in Java, and the way data is stored inside that object could vary from one JVM implementation to another.
For this reason, the notion of a direct buffer was introduced. Direct buffers are intended for interaction with channels and native I/O routines. They make a best effort to store the byte elements in a memory area that a channel can use for direct, or raw, access by using native code to tell the operating system to drain or fill the memory area directly.
Direct byte buffers are usually the best choice for I/O operations. By design, they support the most efficient I/O mechanism available to the JVM. Nondirect byte buffers can be passed to channels, but doing so may incur a performance penalty. It's usually not possible for a nondirect buffer to be the target of a native I/O operation. If you pass a nondirect ByteBuffer object to a channel for write, the channel may implicitly do the following on each call:
Create a temporary direct ByteBuffer object.
Copy the content of the nondirect buffer to the temporary buffer.
Perform the low-level I/O operation using the temporary buffer.
The temporary buffer object goes out of scope and is eventually garbage collected.
This can potentially result in buffer copying and object churn on every I/O, which are exactly the sorts of things we'd like to avoid. However, depending on the implementation, things may not be this bad. The runtime will likely cache and reuse direct buffers or perform other clever tricks to boost throughput. If you're simply creating a buffer for one-time use, the difference is not significant. On the other hand, if you will be using the buffer repeatedly in a high-performance scenario, you're better off allocating direct buffers and reusing them.
Direct buffers are optimal for I/O, but they may be more expensive to create than nondirect byte buffers. The memory used by direct buffers is allocated by calling through to native, operating system-specific code, bypassing the standard JVM heap. Setting up and tearing down direct buffers could be significantly more expensive than heap-resident buffers, depending on the host operating system and JVM implementation. The memory-storage areas of direct buffers are not subject to garbage collection because they are outside the standard JVM heap.
The performance tradeoffs of using direct versus nondirect buffers can vary widely by JVM, operating system, and code design. By allocating memory outside the heap, you may subject your application to additional forces of which the JVM is unaware. When bringing additional moving parts into play, make sure that you're achieving the desired effect. I recommend the old software maxim: first make it work, then make it fast. Don't worry too much about optimization up front; concentrate first on correctness. The JVM implementation may be able to perform buffer caching or other optimizations that will give you the performance you need without a lot of unnecessary effort on your part.
allocate分配方式产生的内存开销是在JVM中的,allocateDirect分配方式产生的开销在JVM之外,以就是系统级的内存分配。系统级别内存的分配比JVM内存的分配要耗时多。所以并非不论什么时候 allocateDirect的操作效率都是很高的。
那什么时候使用堆内存,什么时候使用直接内存?
参考:NIO ByteBuffer 的 allocate 和 allocateDirect 的区别
什么情况下使用DirectByteBuffer(ByteBuffer.allocateDirect(int))?
1、频繁的native IO,即缓冲区 中转 从操作系统获取的文件数据、或者使用缓冲区中转网络数据等
2、不需要经常创建和销毁DirectByteBuffer对象
3、经常复用DirectByteBuffer对象,即经常写入数据到DirectByteBuffer中,然后flip,再读取出来,最后clear。。反复使用该DirectByteBuffer对象。
而且,DirectByteBuffer不会占用堆内存。。也就是不会受到堆大小限制,只在DirectByteBuffer对象被回收后才会释放该缓冲区。
什么情况下使用HeapByteBuffer(ByteBuffer.allocate(int))?
1、同一个HeapByteBuffer对象很少被复用,并且该对象经常是用一次就不用了,此时可以使用HeapByteBuffer,因为创建HeapByteBuffer开销比DirectByteBuffer低。
(但是!!创建所消耗时间差距只是一倍以下的差距,一般一次只会创建一个DirectByteBuffer对象反复使用,而不会创建几百个DirectByteBuffer,
所以在创建一个对象的情况下,HeapByteBuffer并没有什么优势,所以,开发中要使用ByteBuffer时,直接用DirectByteBuffer就行了)
源码
Java IO学习笔记二:DirectByteBuffer与HeapByteBuffer的更多相关文章
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
- Java IO学习笔记:概念与原理
Java IO学习笔记:概念与原理 一.概念 Java中对文件的操作是以流的方式进行的.流是Java内存中的一组有序数据序列.Java将数据从源(文件.内存.键盘.网络)读入到内存 中,形成了 ...
- Java IO学习笔记总结
Java IO学习笔记总结 前言 前面的八篇文章详细的讲述了Java IO的操作方法,文章列表如下 基本的文件操作 字符流和字节流的操作 InputStreamReader和OutputStreamW ...
- Java IO学习笔记三
Java IO学习笔记三 在整个IO包中,实际上就是分为字节流和字符流,但是除了这两个流之外,还存在了一组字节流-字符流的转换类. OutputStreamWriter:是Writer的子类,将输出的 ...
- Java IO学习笔记一
Java IO学习笔记一 File File是文件和目录路径名的抽象表示形式,总的来说就是java创建删除文件目录的一个类库,但是作用不仅仅于此,详细见官方文档 构造函数 File(File pare ...
- Java IO学习笔记一:为什么带Buffer的比不带Buffer的快
作者:Grey 原文地址:Java IO学习笔记一:为什么带Buffer的比不带Buffer的快 Java中为什么BufferedReader,BufferedWriter要比FileReader 和 ...
- Java IO学习笔记三:MMAP与RandomAccessFile
作者:Grey 原文地址:Java IO学习笔记三:MMAP与RandomAccessFile 关于RandomAccessFile 相较于前面提到的BufferedReader/Writer和Fil ...
- Java IO学习笔记四:Socket基础
作者:Grey 原文地址:Java IO学习笔记四:Socket基础 准备两个Linux实例(安装好jdk1.8),我准备的两个实例的ip地址分别为: io1实例:192.168.205.138 io ...
- Java IO学习笔记六:NIO到多路复用
作者:Grey 原文地址:Java IO学习笔记六:NIO到多路复用 虽然NIO性能上比BIO要好,参考:Java IO学习笔记五:BIO到NIO 但是NIO也有问题,NIO服务端的示例代码中往往会包 ...
随机推荐
- [CTF]维吉尼亚密码(维基利亚密码)
[CTF]维吉尼亚密码(维基利亚密码) ----------------------百度百科 https://baike.baidu.com/item/维吉尼亚密码/4905472?fr=aladdi ...
- ExtJS4中Ext.onReady、Ext.define、Ext.create
1.Ext.onReady 说明:onReady内的语句块会在页面上下文加载后再执行. 2.Ext.define 说明:创建类,可以继承其他类,也可以被继承. 例子1: 1 <script ty ...
- TLS是如何保障数据传输安全(中间人攻击)
前言 前段时间和同事讨论HTTPS的工作原理,当时对这块知识原理掌握还是靠以前看了一些博客介绍,深度不够,正好我这位同事是密码学专业毕业的,结合他密码学角度对tls加解密这阐述,让我对这块原理有了更进 ...
- LeetCode 617. 合并二叉树 Java
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠. 你需要将他们合并为一个新的二叉树.合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 ...
- JMeter四种参数化方式
JMeter参数化是指把固定的数据动态化,这样更贴合实际的模拟用户请求,比如模拟多个不同账号.JMeter一共有四种参数化方式,分别是: CSV Data Set Config Function He ...
- x小结:certutil -hashfile D:\1.exe MD5
在Win7上,MD5不要使用小写,在Win10上没有这个问题 x小结:certutil -hashfile D:\1.exe MD5certutil -hashfile D:\1.exe SHA1ce ...
- 【转载】基于Linux命令行KVM虚拟机的安装配置与基本使用
基于Linux命令行KVM虚拟机的安装配置与基本使用 https://alex0227.github.io/2018/06/06/%E5%9F%BA%E4%BA%8ELinux%E5%91%BD%E4 ...
- Docker创建镜像以及私有仓库
Docker的安装及镜像.容器的基本操作详见博客https://blog.51cto.com/11134648/2160257下面介绍Docker创建镜像和创建私有仓库的方法,详细如下: 创建镜像 创 ...
- 二进制部署K8S-3核心插件部署
二进制部署K8S-3核心插件部署 5.1. CNI网络插件 kubernetes设计了网络模型,但是pod之间通信的具体实现交给了CNI往插件.常用的CNI网络插件有:Flannel .Calico. ...
- 1.4 重置root用户密码
图1-45 系统的欢迎界面 1.4 重置root用户密码 平日里让运维人员头疼的事情已经很多了,因此偶尔把Linux系统的密码忘记了并不用慌,只需简单几步就可以完成密码的重置工作.但是,如果您是第一 ...