efcore分表分库原理解析
ShardingCore
ShardingCore 易用、简单、高性能、普适性,是一款扩展针对efcore生态下的分表分库的扩展解决方案,支持efcore2+的所有版本,支持efcore2+的所有数据库、支持自定义路由、动态路由、高性能分页、读写分离的一款组件,如果你喜欢这组件或者这个组件对你有帮助请点击下发star让更多的.neter可以看到使用
Gitee Star 助力dotnet 生态 Github Star
经过了3个星期再次发一篇博客来介绍本框架的实现原理通过本篇文章可以有助于您阅读源码和提出宝贵意见。之前通过两篇文章简单的介绍了sharding-core的核心聚合原理(ShardingCore 如何呈现“完美”分表)和高性能分页原理实现(ShardingCore是如何针对分表下的分页进行优化的),这两篇文章主要是针对分表分库下数据获取的一个解决方案的思路并不涉及到太多efcore(.net)的知识。
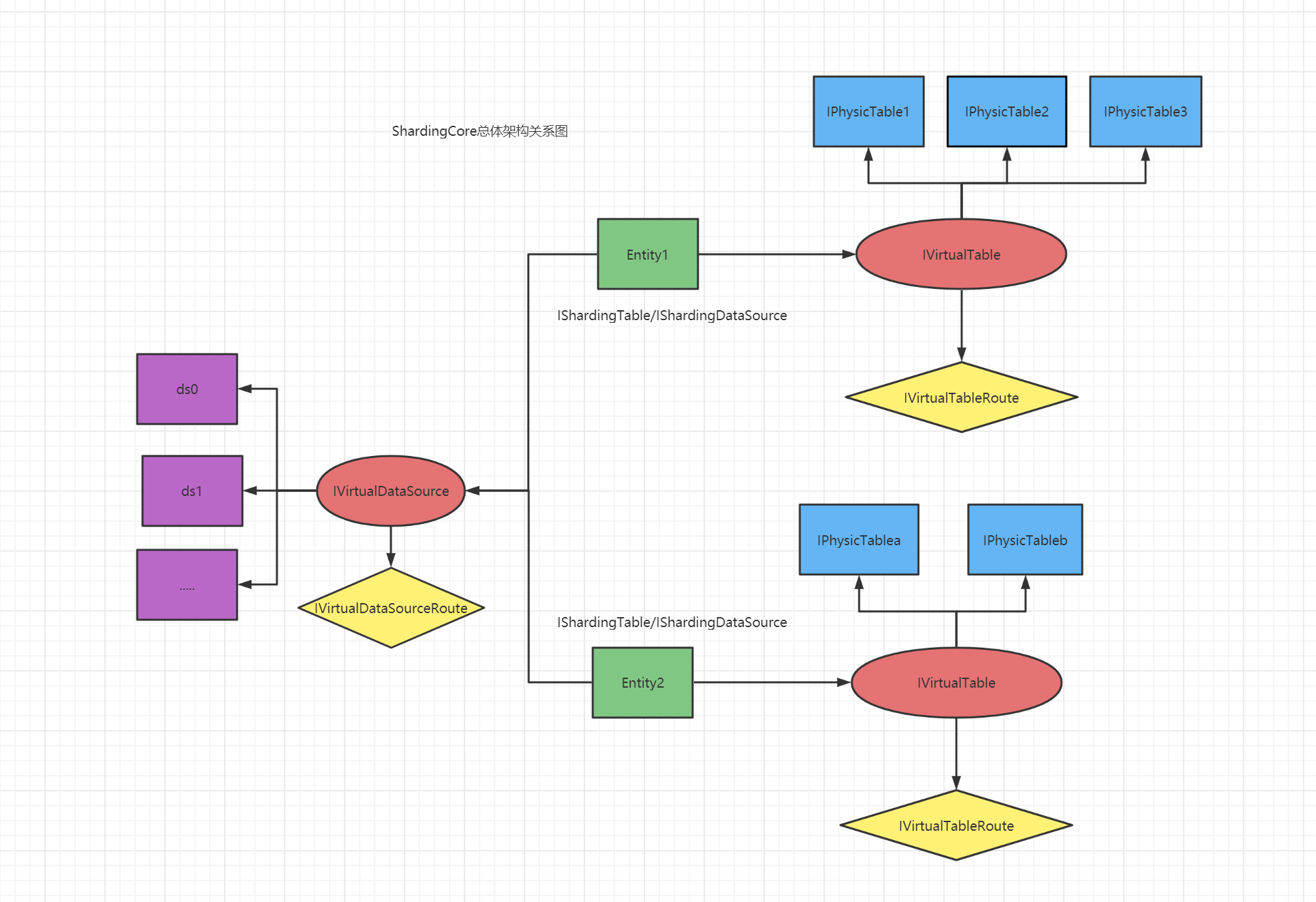
通过关系图我们可以看到目前一个shardingdbcontext下主要是以entity作为媒介通过两个虚拟表和虚拟数据源为桥梁来实现一对多的关系映射
首先先说下经过了3个星期目前本框架已经具有了3个星期前不具备的一些功能,主要是有以下几个功能上的改进和添加
分库支持
之前的框架仅支持分表,思路是先将分表做到相对完成度比较高后在实现分库,毕竟分表对于大部分用户而言使用场景更高,目前已经实现针对数据对象实现了分库的实现,当然您还是可以在分库的基础上在实现分表,这两者是不冲突的
services.AddShardingDbContext<DefaultShardingDbContext, DefaultDbContext>(
o =>
o.UseSqlServer("Data Source=localhost;Initial Catalog=ShardingCoreDBxx0;Integrated Security=True;")
).Begin(o =>
{
o.CreateShardingTableOnStart = true;
o.EnsureCreatedWithOutShardingTable = true;
})
.AddShardingQuery((conStr, builder) => builder.UseSqlServer(conStr).UseLoggerFactory(efLogger)
.UseQueryTrackingBehavior(QueryTrackingBehavior.NoTracking))
.AddShardingTransaction((connection, builder) =>
builder.UseSqlServer(connection).UseLoggerFactory(efLogger))
.AddDefaultDataSource("ds0","Data Source=localhost;Initial Catalog=ShardingCoreDBxx0;Integrated Security=True;")
.AddShardingDataSource(sp =>//添加额外两个数据源一共3个库
{
return new Dictionary<string, string>()
{
{"ds1", "Data Source=localhost;Initial Catalog=ShardingCoreDBxx1;Integrated Security=True;"},
{"ds2", "Data Source=localhost;Initial Catalog=ShardingCoreDBxx2;Integrated Security=True;"},
};
}).AddShardingDataSourceRoute(o =>
{
o.AddShardingDatabaseRoute<SysUserModVirtualDataSourceRoute>();
}).End();
支持code-first
相信很多使用efcore的用户其实是更加喜欢脱离数据库开发,在开发的时候不进行数据库层面的操作而只专注于代码的业务编写来保证高效性,配合efcore的fluent api 可以做到很完美的开发时候不关注数据库,效率拉满
//创建迁移sqlgenerator
/// <summary>
/// https://github.com/Coldairarrow/EFCore.Sharding/blob/master/src/EFCore.Sharding.SqlServer/ShardingSqlServerMigrationsSqlGenerator.cs
/// </summary>
public class ShardingSqlServerMigrationsSqlGenerator<TShardingDbContext> : SqlServerMigrationsSqlGenerator where TShardingDbContext:DbContext,IShardingDbContext
{
public ShardingSqlServerMigrationsSqlGenerator(MigrationsSqlGeneratorDependencies dependencies, IRelationalAnnotationProvider migrationsAnnotations) : base(dependencies, migrationsAnnotations)
{
}
protected override void Generate(
MigrationOperation operation,
IModel model,
MigrationCommandListBuilder builder)
{
var oldCmds = builder.GetCommandList().ToList();
base.Generate(operation, model, builder);
var newCmds = builder.GetCommandList().ToList();
var addCmds = newCmds.Where(x => !oldCmds.Contains(x)).ToList();
MigrationHelper.Generate<TShardingDbContext>(operation, builder, Dependencies.SqlGenerationHelper, addCmds);
}
}
//添加迁移codefirst的contextfactory基本和starup一样如果是以非命令执行比如 `_context.Database.Migrate()`那么startup也需要添加` .ReplaceService<IMigrationsSqlGenerator, ShardingSqlServerMigrationsSqlGenerator<DefaultShardingTableDbContext>>()`
public class DefaultDesignTimeDbContextFactory: IDesignTimeDbContextFactory<DefaultShardingTableDbContext>
{
static DefaultDesignTimeDbContextFactory()
{
var services = new ServiceCollection();
services.AddShardingDbContext<DefaultShardingTableDbContext, DefaultTableDbContext>(
o =>
o.UseSqlServer("Data Source=localhost;Initial Catalog=ShardingCoreDBMigration;Integrated Security=True;")
.ReplaceService<IMigrationsSqlGenerator, ShardingSqlServerMigrationsSqlGenerator<DefaultShardingTableDbContext>>()//区别替换掉原先的迁移
).Begin(o =>
{
o.CreateShardingTableOnStart = false;
o.EnsureCreatedWithOutShardingTable = false;
o.AutoTrackEntity = true;
})
.AddShardingQuery((conStr, builder) => builder.UseSqlServer(conStr)
.UseQueryTrackingBehavior(QueryTrackingBehavior.NoTracking))
.AddShardingTransaction((connection, builder) =>
builder.UseSqlServer(connection))
.AddDefaultDataSource("ds0",
"Data Source=localhost;Initial Catalog=ShardingCoreDBMigration;Integrated Security=True;")
.AddShardingTableRoute(o =>
{
o.AddShardingTableRoute<ShardingWithModVirtualTableRoute>();
o.AddShardingTableRoute<ShardingWithDateTimeVirtualTableRoute>();
}).End();
services.AddLogging();
var buildServiceProvider = services.BuildServiceProvider();
ShardingContainer.SetServices(buildServiceProvider);
new ShardingBootstrapper(buildServiceProvider).Start();
}
public DefaultShardingTableDbContext CreateDbContext(string[] args)
{
return ShardingContainer.GetService<DefaultShardingTableDbContext>();
}
}
1.初始化添加迁移(Add-Migration EFCoreSharding -Context DefaultShardingTableDbContext -OutputDir Migrations\ShardingMigrations)
2.更新数据库(Update-Database -Context DefaultShardingTableDbContext -Verbose)
3.获取迁移脚本( Script-Migration -Context DefaultShardingTableDbContext)用于生产环境
支持自动追踪
efcore的好用功能之一(自动追踪)开启后可以帮助程序实现更多的功能,虽然之前也是支持的但是就是用体验而言之前的需要手动attach而目前支持了自动化,当然也不可能和efcore原生的100%完美,当然框架默认不开启自动追踪
services.AddShardingDbContext<DefaultShardingTableDbContext, DefaultTableDbContext>(
o =>
o.UseSqlServer("Data Source=localhost;Initial Catalog=ShardingCoreDBMigration;Integrated Security=True;")
.ReplaceService<IMigrationsSqlGenerator,ShardingSqlServerMigrationsSqlGenerator<DefaultShardingTableDbContext>>()
).Begin(o =>
{
o.CreateShardingTableOnStart = false;
o.EnsureCreatedWithOutShardingTable = false;
o.AutoTrackEntity = true;//添加对应代码可以让整个框架进行自动追踪支持
})
.AddShardingQuery((conStr, builder) => builder.UseSqlServer(conStr))
.AddShardingTransaction((connection, builder) =>
builder.UseSqlServer(connection))
.AddDefaultDataSource("ds0",
"Data Source=localhost;Initial Catalog=ShardingCoreDBMigration;Integrated Security=True;")
.AddShardingTableRoute(o =>
{
o.AddShardingTableRoute<ShardingWithModVirtualTableRoute>();
o.AddShardingTableRoute<ShardingWithDateTimeVirtualTableRoute>();
}).End();
单次查询核心线程数控制
说人话就是本次查询路由坐落到10张表,之前的做法是开启10个线程并行查询10次后获取到对应的迭代器,目前添加了核心查询线程数控制,如果您设置了5,本次查询路由到10张表,会议开始开启5个线程,后续每完成一个开启一个新新线程,并且支持超时时间,可以保证在一定时间内执行完成,完不成就超时,防止查询坐落的表过多而一次性大量开启线程从而导致程序消耗过多资源
.Begin(o =>
{
o.CreateShardingTableOnStart = true;
o.EnsureCreatedWithOutShardingTable = true;
o.AutoTrackEntity = true;
o.ParallelQueryMaxThreadCount = 10;//并发查询线程数
o.ParallelQueryTimeOut=TimeSpan.FromSeconds(10);//查询并发等待超时时间
}
读写分离延迟处理
框架目前支持全局定义和局部定义是否启用读写分离,如果您开启了读写分离那么数据库和数据库之间的数据同步延迟会是一个很严重的问题他会让你没办法很好的查询到刚修改的数据,而sharding-core为这个场景提供了手动切换是否使用writeonly字符串;用来保证消除读写分离时带来的延迟,而造成数据处理上的异常。而且程序也提供了读写分离策略除了随机和轮询外额外有一个配置可以配置读写分离真正执行是依据dbcontext还是每次都是最新的,每次都是最新的会有一个问题,你明明分页count出来是10条可能查询只返回了9条或者其他数据,所以再次基础上进行了设置是否按dbcontext就是说同一个dbcontext是一样的链接,dbcontext默认是scope就是说一次请求下面是一样的当然也可以设置成每次都是最新的具体自行考虑根据业务
以上一些功能的添加和优化是之前sharding-core版本所不具备的,其他功能也在不断的完善中。
接下来我将来讲解下sharding-core的实现原理如何让efcore实现sharding功能,并且完美的无感知使用dbcontext。
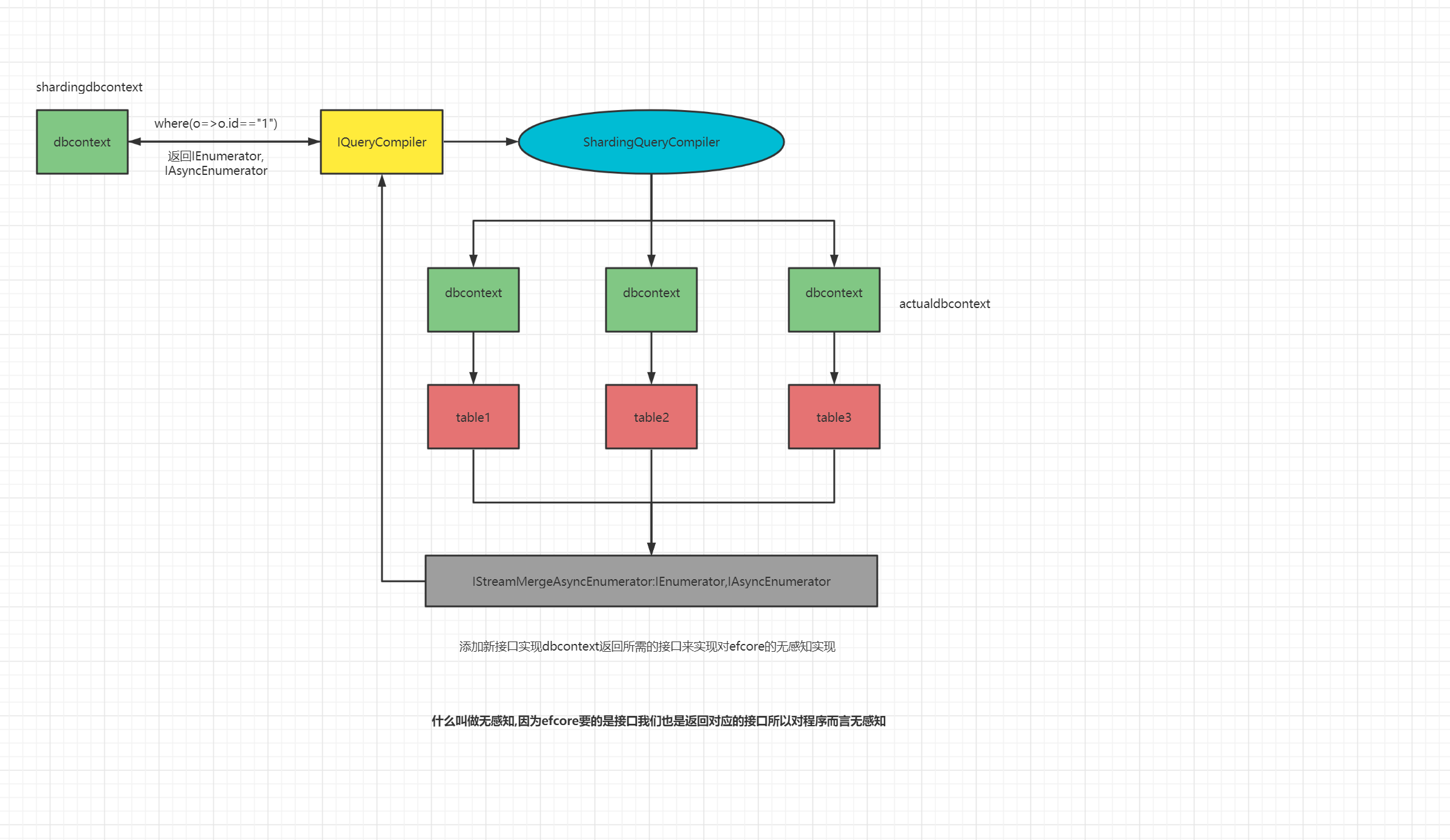
ShardingDbContext的扩展
在sharding-core中核心api接口依然是通过dbcontext的继承来实现的,首先是拦截sql,总的有两条路可以走1.通过efcore提供的拦截器拦截sql配合antlr4实现对sql语句的分析和从新分裂出对应的语句来进行查询最后通过多个datareader进行流式聚合。2.通过拦截iqueryable的lambda表达式来分裂成多个ienumerator进行聚合,在这里我选择了后者因为相比表达式的解析字符串的解析更加吃力而且本人也不是很熟悉antlr4所以选择了后者。那么如何进行拦截的,这个熟悉linq的同学肯定都知道一个iqueryable都会有一个对应的provider这两个是一对的,又得益于efcore的开放型设计通过替换两个核心接口来实现IDbSetSource和 IQueryCompiler,下面就简单说下这两个接口在efcore中的作用
IDbSetSource
用于针对efcore的dbcontext.set<entity>()和dbset<entity>()进行拦截和api重构具体是现代吗ShardingDbSetSource
IQueryCompiler
efcore核心查询编译,用于对表达式进行编译后缓存起来,所有的查询都会通过IQueryCompiler核心接口,那么通过自己实现这两个接口接管对应的表达式后对表达式进行分析就可以获取到对应的where子句,在通过将表达式进行路由后并行请求流式聚合返回对应的IEnumerator或者IAsyncEnumerator就可以实现无感知使用sharding-core,感觉和使用efcore一毛一样。具体实现代码ShardingQueryCompiler
AtcualDbContext扩展
用过efcore的都应该知道目前efcore的机制就是一个对象一张表,在这个机制下面如果你想实现上图的功能只能创建多个dbcontext然后让对应的dbcontext的对象映射到对应的表里面而不是固定的Entitiy对应table,那么如何让对应的对象Entity对应table1和table2和table3呢?
//dbcontext下的这个方法在dbcontext被创建后第一次调用Model属性会被加载如果缓存已存在那么不会被多次加载
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
}
说人话就是我可以再这边通过modelBuilder获取我自己想要的对象但是如果我把Entity映射到了table1那么这个dbcontext就会被缓存起来entity-table1这个关系也会被缓存起来没办法改变了,那么是否有办法可以解决这个机制呢有两个efcore的接口可以帮助我们实现这个功能,这个在博客园很多大神都已经实现过了具体是 IModelCacheKeyFactory和 IModelCustomizer
IModelCacheKeyFactory
用于将efcore的模型缓存进行判断是否和之前的模型缓存一致具体实现ShardingModelCacheKeyFactory
public class ShardingModelCacheKeyFactory : IModelCacheKeyFactory
{
public object Create(DbContext context)
{
if (context is IShardingTableDbContext shardingTableDbContext&&!string.IsNullOrWhiteSpace(shardingTableDbContext.RouteTail.GetRouteTailIdentity()))
{
return $"{context.GetType()}_{shardingTableDbContext.RouteTail.GetRouteTailIdentity()}";
}
else
{
return context.GetType();
}
}
}
IModelCustomizer
这个接口是efcore开放出来在模型缓存结构定义完成后初始化缓存前可以使用的接口,就是说我们并不需要在OnModelCreating方法中使用或者说不需要再次地方进行修改可以在IModelCustomizer接口内部实现,具体代码ShardingModelCustomizer
public class ShardingModelCustomizer<TShardingDbContext> : ModelCustomizer where TShardingDbContext : DbContext, IShardingDbContext
{
private Type _shardingDbContextType => typeof(TShardingDbContext);
public ShardingModelCustomizer(ModelCustomizerDependencies dependencies) : base(dependencies)
{
}
public override void Customize(ModelBuilder modelBuilder, DbContext context)
{
base.Customize(modelBuilder, context);
if (context is IShardingTableDbContext shardingTableDbContext&& shardingTableDbContext.RouteTail.IsShardingTableQuery())
{
var isMultiEntityQuery = shardingTableDbContext.RouteTail.IsMultiEntityQuery();
if (!isMultiEntityQuery)
{
var singleQueryRouteTail = (ISingleQueryRouteTail) shardingTableDbContext.RouteTail;
var tail = singleQueryRouteTail.GetTail();
var virtualTableManager = ShardingContainer.GetService<IVirtualTableManager<TShardingDbContext>>();
var typeMap = virtualTableManager.GetAllVirtualTables().Where(o => o.GetTableAllTails().Contains(tail)).Select(o => o.EntityType).ToHashSet();
//设置分表
var mutableEntityTypes = modelBuilder.Model.GetEntityTypes().Where(o => o.ClrType.IsShardingTable() && typeMap.Contains(o.ClrType));
foreach (var entityType in mutableEntityTypes)
{
MappingToTable(entityType.ClrType, modelBuilder, tail);
}
}
else
{
var multiQueryRouteTail = (IMultiQueryRouteTail) shardingTableDbContext.RouteTail;
var entityTypes = multiQueryRouteTail.GetEntityTypes();
var mutableEntityTypes = modelBuilder.Model.GetEntityTypes().Where(o => o.ClrType.IsShardingTable() && entityTypes.Contains(o.ClrType)).ToArray();
foreach (var entityType in mutableEntityTypes)
{
var queryTail = multiQueryRouteTail.GetEntityTail(entityType.ClrType);
if (queryTail != null)
{
MappingToTable(entityType.ClrType, modelBuilder, queryTail);
}
}
}
}
}
private void MappingToTable(Type clrType, ModelBuilder modelBuilder, string tail)
{
var shardingEntityConfig = ShardingUtil.Parse(clrType);
var shardingEntity = shardingEntityConfig.EntityType;
var tailPrefix = shardingEntityConfig.TailPrefix;
var entity = modelBuilder.Entity(shardingEntity);
var tableName = shardingEntityConfig.VirtualTableName;
if (string.IsNullOrWhiteSpace(tableName))
throw new ArgumentNullException($"{shardingEntity}: not found original table name。");
#if DEBUG
Console.WriteLine($"mapping table :[tableName]-->[{tableName}{tailPrefix}{tail}]");
#endif
entity.ToTable($"{tableName}{tailPrefix}{tail}");
}
}
稍作解析进入后会先判断dbcontext真正执行的那个是否是需要分表的并且判断本次查询涉及到的表示一张还是多张,对此对象在数据库里的映射关系改成分表
到此为止efcore的查询架构已经算是非常清晰了
- 通过替换模型缓存接口和查询编译接口来实现查询编译时拦截sql和模型重建
- 通过类似适配器模式来实现对外dbcontext其实内部有多个dbcontext在进行真正的工作
上述几步让sharding-core在使用上和efcore一样除了配置方面,后续将会出更多的efcore的分表分库实践文章和继续开发完成其他orm的支持,当然这个改动将会非常大也希望各位.neter有喜欢的或者希望了解源码的或者想参与完善的多多支持
下一篇实现如何自定义路由,自定义路由的原理 where left
最后
本人会一致维护该框架,希望为.net生态做一份共享
Gitee Star 助力dotnet 生态 Github Star
QQ群:771630778
个人QQ:326308290(欢迎技术支持提供您宝贵的意见)
个人邮箱:326308290@qq.com
efcore分表分库原理解析的更多相关文章
- 使用MyCat分表分库原理分析
Mycat可以实现 读写分离 分表分库 主从复制是MySQL自带的哈~ 关于分片取模算法: 根据id进行取模 根据数据库集群的数量(或者说是表数量,mycat里面一个表对应一个库) 使用MyCat ...
- .Net下极限生产力之efcore分表分库全自动化迁移CodeFirst
.Net下极限生产力之分表分库全自动化Migrations Code-First ## 介绍 本文ShardinfCore版本x.6.x.x+ 本期主角: - [`ShardingCore`](htt ...
- .Net 下高性能分表分库组件-连接模式原理
ShardingCore ShardingCore 一款ef-core下高性能.轻量级针对分表分库读写分离的解决方案,具有零依赖.零学习成本.零业务代码入侵. Github Source Code 助 ...
- mycat原理及分表分库入门
1.什么是MyCat: MyCat是一个开源的分布式数据库系统,是一个实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原 ...
- efcore使用ShardingCore实现分表分库下的多租户
efcore使用ShardingCore实现分表分库下的多租户 介绍 本期主角:ShardingCore 一款ef-core下高性能.轻量级针对分表分库读写分离的解决方案,具有零依赖.零学习成本.零业 ...
- efcore在Saas系统下多租户零脚本分表分库读写分离解决方案
efcore在Saas系统下多租户零脚本分表分库读写分离解决方案 ## 介绍 本文ShardinfCore版本x.6.0.20+ 本期主角: - [`ShardingCore`](https://gi ...
- .Net下你不得不看的分表分库解决方案-多字段分片
.Net下你不得不看的分表分库解决方案-多字段分片 介绍 本期主角:ShardingCore 一款ef-core下高性能.轻量级针对分表分库读写分离的解决方案,具有零依赖.零学习成本.零业务代码入侵 ...
- 重新学习Mysql数据13:Mysql主从复制,读写分离,分表分库策略与实践
一.MySQL扩展具体的实现方式 随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量. 关于数据库的扩展主要包括:业务拆分.主从复制.读写分离.数据库分库 ...
- 分表分库解决方案(mycat,tidb,shardingjdbc)
公司最近有分表分库的需求,所以整理一下分表分库的解决方案以及相关问题. 1.sharding-jdbc(sharding-sphere) 优点: 1.可适用于任何基于java的ORM框架,如:JPA. ...
随机推荐
- 深入浅出Mybatis系列(一)---Mybatis简介
1.什么是MyBatis? MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且 ...
- File--字节流--字符流
File类 java.io.File 类是文件和目录路径名的抽象表示,主要用于文件和目录的创建.查找和删除等操作. 1.构造方法 public File(String pathname) :通过将给定 ...
- 梯度下降做做优化(batch gd、sgd、adagrad )
首先说明公式的写法 上标代表了一个样本,下标代表了一个维度: 然后梯度的维度是和定义域的维度是一样的大小: 1.batch gradient descent: 假设样本个数是m个,目标函数就是J(th ...
- 五分钟搞定Docker安装ElasticSearch
前言 项目准备上ElasticSearch,为了后期开发不卡壳只能笨鸟先飞,在整个安装过程中遇到以下三个问题. Docker安装非常慢 ElasticSearch-Head连接出现跨域 Elastic ...
- tensorflow 单机多卡 官方cifar10例程
测试了官方历程,看没有问题,加上时间紧任务重,就不深究了. 官方tutorials:https://www.tensorflow.org/tutorials/images/deep_cnn githu ...
- Linux系统的vsftpd服务配置
概述: FTP ( 文件传输协议 ) 是 INTERNET 上仍常用的最老的网络协议之一 , 它为系统提供了通过网络与远程服务器进行传输的简单方法FTP 服务器包的名称为 VSFTPD , 它代表 V ...
- 从kratos分析BBR限流源码实现
什么是自适应限流 自适应限流从整体维度对应用入口流量进行控制,结合应用的 Load.CPU 使用率.总体平均 RT.入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流 ...
- JDK1.8源码阅读笔记(1)Object类
JDK1.8源码阅读笔记(1)Object类 Object 类属于 java.lang 包,此包下的所有类在使⽤时⽆需⼿动导⼊,系统会在程序编译期间⾃动 导⼊.Object 类是所有类的基类,当⼀ ...
- Linux下sed找出IP中第四位
ip addr|sed -n '9p'|egrep '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'|sed -nr 's#^.*inet (.*) b ...
- 稚晖君-最小linux服务器运行 nginx + netcore
华为天才少年, B站科技大神,稚晖君(自称野生钢铁侠),多少科技爱好者拜服在他的全方位技术栈 今天我们就去入手一个他的量产产品 号称最小linux电脑 的"夸克" 到手之后,我们马 ...