seq2seq之双向解码
在文章《玩转Keras之seq2seq自动生成标题》中我们已经基本探讨过seq2seq,并且给出了参考的Keras实现。
本文则将这个seq2seq再往前推一步,引入双向的解码机制,它在一定程度上能提高生成文本的质量(尤其是生成较长文本时)。本文所介绍的双向解码机制参考自《Synchronous Bidirectional Neural Machine Translation》,最后笔者也是用Keras实现的。
背景介绍
研究过seq2seq的读者都知道,常见的seq2seq的解码过程是从左往右逐字(词)生成的,即根据encoder的结果先生成第一个字;然后根据encoder的结果以及已经生成的第一个字,来去生成第二个字;再根据encoder的结果和前两个字,来生成第三个词;依此类推。总的来说,就是在建模如下概率分解
\]
当然,也可以从右往左生成,也就是先生成倒数第一个字,再生成倒数第二个字、倒数第三个字,等等。问题是,不管从哪个方向生成,都会有方向性倾斜的问题。比如,从左往右生成的话,前几个字的生成准确率肯定会比后几个字要高,反之亦然。在《Synchronous Bidirectional Neural Machine Translation》给出了如下的在机器翻译任务上的统计结果:
| Model | The first 4 tokens | The last 4 tokens |
|---|---|---|
| L2R | 40.21% | 35.10% |
| R2L | 35.67% | 39.47% |
L2R和R2L分别是指从左往右和从右往左的解码生成。从表中我们可以看到,如果从左往右解码,那么前四个token的准确率有40%左右,但是最后4个token的准确率只有35%;反过来也差不多。这就反映了解码的不对称性。
为了消除这种不对称性,《Synchronous Bidirectional Neural Machine Translation》提出了一个双向解码机制,它维护两个方向的解码器,然后通过Attention来进一步对齐生成。
双向解码
虽然本文参考自《Synchronous Bidirectional Neural Machine Translation》,但我没有完全精读原文,我只是凭自己的直觉粗读了原文,大致理解了原理之后自己实现的模型,所以并不保证跟原文完全一致。此外,这篇论文并不是第一篇做双向解码生成的论文,但它是我看到的双向解码的第一篇论文,所以我就只实现了它,并没有跟其他相关论文进行对比。
基本思路
既然叫双向“解码”,那么改动就只是在decoder那里,而不涉及到encoder,所以下面的介绍中也只侧重描述decoder部分。还有,要注意的是双向解码只是一个策略,而下面只是一种参考实现,并不是标准的、唯一的,这就好比我们说的seq2seq也只是序列到序列生成模型的泛指,具体encoder和decoder怎么设计,有很多可调整的地方。
首先,给出一个简单的示意动图(Seq2Seq的双向解码机制图示),来演示双向解码机制的设计和交互过程:
Your browser does not support video
如图所示,双向解码基本上可以看成是两个不同方向的解码模块共存,为了便于描述,我们将上方称为L2R模块,而下方称为R2L模块。开始情况下,大家都输入一个起始标记(上图中的S),然后L2R模块负责预测第一个字,而R2L模块负责预测最后一个字;接着,将第一个字(以及历史信息)传入到L2R模块中,来预测第二个字,为了预测第二个字,除了用到L2R模块本身的编码外,还用到R2L模块已有的编码结果;反之,将最后一个字(以及历史信息)传入到R2L模块,再加上L2R模块已有的编码信息,来预测倒数第二个字;依此类推,直到出现了结束标记(上图中的E)。
数学描述
换句话说,每个模块预测每一个字时,除了用到模块内部的信息外,还用到另一模块已经编码好的信息序列,而这个“用”是通过Attention来实现的。用公式来说,假设当前情况下L2R模块要预测第nn个字,以及R2L模块要预测倒数第nn个字。假设经过若干层编码后,得到的R2L向量序列(对应图中左上方的第二行)为:
\]
而R2L的向量序列(对应图中左下方的倒数第二行)为:
\]
如果是单向解码的话,我们会用\(h^{(l2r)}_n\)作为特征来预测第n个字,或者用\(h^{(r2l)}_n\)作为特征来预测倒数第n个字。
在双向解码机制下,我们以\(h^{(l2r)}_n\)为query,然后以\(H^{(r2l)}\)为key和value来做一个Attention,用Attention的输出作为特征来预测第n个字,这样在预测第n个字的时候,就可以提前“感知”到后面的字了;同样地,我们以\(h^{(r2l)}_n\)为query,然后以\(H^{(l2r)}\)为key和value来做一个Attention,用Attention的输出作为特征来预测倒数第n个字,这样在预测倒数第n个字的时候,就可以提前“感知”到前面的字了。上面示意图中,上面两层和下面两层之间的交互,就是指Attention。在下面的代码中,用到的是最普通的乘性Attention(参考《〈Attention is All You Need〉浅读(简介+代码)》)。
模型实现
上面就是双向解码的基本原理和做法。可以感觉到,这样一来,seq2seq的decoder也变得对称起来了,这是一个很漂亮的特点。当然,为了完全实现这个模型,还需要思考一些问题:
怎么训练?
怎么预测?
训练方案
跟普通的seq2seq一样,基本的训练方案就是用所谓的Teacher-Forcing的方式来进行训练,即L2R方向在预测第n个字的时候,假设前n−1个字都是准确知道的,而R2L方向在预测倒数第n个字的时候,假设倒数第n−1,n−2,…,1个字都是准确知道的。最终的loss是两个方向的逐字交叉熵的平均。
不过这样的训练方案实在是无可奈何之举,后面我们会分析它信息泄漏的弊端。
双向束搜索
现在讨论预测过程。
如果是常规的单向解码的seq2seq,我们会使用beam search(束搜索)的算法,给出概率尽可能大的序列。所谓beam search,指的是依次逐字解码,每次只保留概率最大的topk条“临时路径”,直到出现结束标记为止。
到了双向解码这里,情况变得复杂了一些。我们依然用beam search的思路,但是同时缓存两个方向的topk结果,也就是说,L2R和R2L两个方向各存topk条临时路径。此外,由于双向解码时,L2R的解码是要参考R2L已有的解码结果的,所以当我们要预测下一个字时,除了要枚举概率最高的topk个字、枚举topk条L2R的临时路径外,还要枚举topk条R2L的临时路径,所以一共要计算topk3那么多个组合。而计算完成后,采用了一种最简单的思路:对每种“字 - L2R临时路径”的得分在“R2L临时路径”这一维度上做了平均,使得的分数变回topk2个,作为每种“字 - L2R临时路径”的得分,再从这topk2个组合中,选出分数最高的topk个。而R2L这边的解码,则要进行反向的、相同的处理。最后,如果L2R和R2L两个方向都解码出了完成的句子,那么就选择概率(得分)最高的那个。
这样的整个过程,我们称之为“双向束搜索(双向beam search)”。如果读者自己比较熟悉单向的beam search,甚至自己都写过beam search的话,上述过程其实不难理解(看看代码就更容易懂了),它算是单向beam search自然延伸。当然,如果对beam search本身不了解的话,看上述搜索的过程应该是云里雾里的。所以想要弄清楚原理的读者,应该要从常规的单向beam search出发,先把它弄懂了,然后再看上述解码过程的描述,最后再看看下面给出的参考代码,就容易弄懂了。
代码参考
下面是笔者给出了双向解码的参考实现,整体还是跟之前的《玩转Keras之seq2seq自动生成标题》一致,只是解码端从双向换成单向了:
https://github.com/bojone/seq2seq/blob/master/seq2seq_bidecoder.py
注:测试环境还是跟之前差不多,大概是Python 2.7 + Keras 2.2.4 + Tensorflow 1.8。用Python 3.x或者其他环境的朋友,如果你们能自己改,那就做相应的改动,如果你们自己不会改,那也请你们别来问我了,我实在没有空也没有义务帮你们跑通每一个环境。本文只讨论seq2seq技术相关的内容可否?
在这个实现里,我觉得有必要解释一下起始标记和结束标记的事情。在之前的单向解码的例子中,笔者是用2作为起始标记,用3作为结束标记。到了双向解码这里,一个很自然的问题就是:L2R和R2L两个方向是不是应该要用两套起始和结束标记呢?
其实这个应该没有什么标准答案,我觉得不管是共用一套还是维护两套起止标记,结果可能都差不多。至于我在上面的参考代码中,使用的方案有点另类,但我认为比较符合直觉,具体是:依然是只用一套,但是在L2R方向中,用2作为起始标记、3作为结束标记,而在R2L方向中,用3作为起始标记、2作为结束标记。
思考分析
最后,我们进一步思考一下这种双向解码方案。尽管将解码过程对称化是一个很漂亮的特点,但也不代表它完全没有问题了,将它思考得更深入一些,有助于我们更好地理解和使用它。
- 改进生成的原因
一个有意思的问题是:看上去双向解码确实能提高句子首尾的生成质量,但会不会同时降低中间部分的生成质量?
当然,理论上这是有可能的,但实际测试时不是很严重。一方面,seq2seq架构的信息编码和解码能力还是很强的,所以不会轻易损失信息;另一方面,我们自己去评估一个句子的质量的时候,往往会重点关注首尾部分,如果首尾部分都很合理,而中间部分不至于太糟糕的话,那么我们都认为它是一个合理的句子;反过来,如果首或尾不合理的话,我们会觉得这个句子很糟糕。这样一来,把句子首尾的生成质量提高了,整体的生成质量也就提高了。
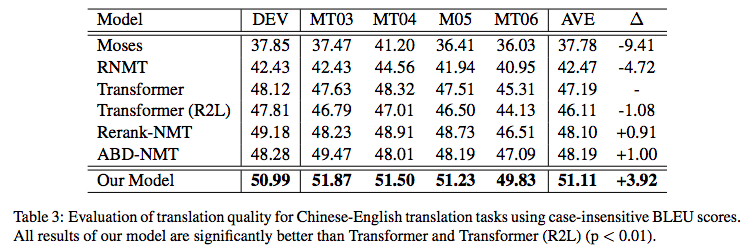
原论文中双向解码相对其它单向模型带来的提升
- 对应不上概率模型
对于单向解码,我们有清晰的概率解释,即在估计条件概率p(Y|X)(也就是(1))。但是在双向解码的时候,我们发现压根儿不知道怎么对应上一个概率模型,换句话说,我们感觉我们是在算概率,感觉效果也有了,却不知道真正算得是啥,因为条件概率的条件依赖完全已经被打乱了。
当然,如果真的有实效的话,理论美感差点也无妨,我说的这一点只是理论审美的追求,大家见仁见智就好。
- 信息提前泄漏
所谓信息泄漏,指的是本来作为预测目标的标签被用来做输入了,从而导致训练阶段的loss虚低(或者准确率虚高)。
由于在双向解码中,L2R端的解码要去读取R2L端已有的向量序列,而在训练阶段,为了预测R2L端的第n个字,是需要传入前n−1个字的,这样一来,越解码到后面,信息泄漏就越严重。如下图所示:
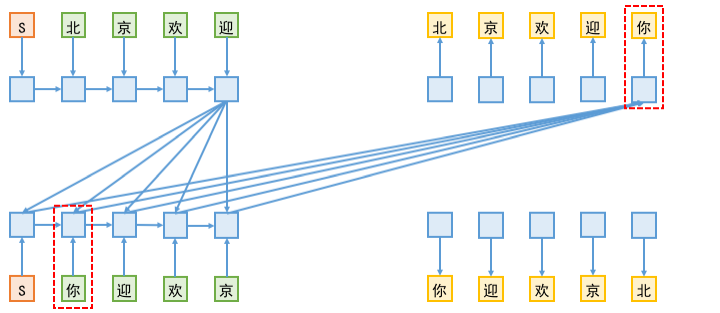
上图为信息泄漏示意图。训练阶段,当L2R端在预测“你”的时候,事实上用到了传入到R2L端的“你”标签;反之,R2L端预测“北”字的时候,同样存在这个问题,即用到了L2R的“北”字标签。
信息泄漏的一个表观现象是:训练到后期,双向解码中L2R和R2L两个方向的交叉熵之和,比单独训练单向解码模型时的单个交叉熵还要小,这并不是因为双向解码带来多大的拟合提升,而正是信息泄漏的体现。
既然训练过程中把信息泄漏了,那为什么这样的模型还有用呢?我想,大概的原因在文章一开头的表格中就给出了。还是刚才的例子,L2R端在预测最后一个字“你”的时候,会用到了R2L端所有的已知信息;而R2L端是从右往左逐字解码的,按照文章一开头的表格的统计数据,我们不难想象到,对于R2L端来说,倒数第一个字的预测准确率应该是最高的。这样一来,假设R2L的倒数第一个字真的能以很高的准确率预测成功的话,那信息泄漏也变成不泄漏了———因为信息泄漏是因为我们人为地传入了标签,但如果预测的结果本身就跟标签一致,那泄漏也不再是泄漏了。
当然,原论文还提供了一个策略来缓解这个泄漏问题,大概做法是先用上述方式训练一版模型,然后对于每个训练样本,用模型生成对应的预测结果(伪标签),接着再去训练模型,这一次训练模型是传入伪标签来预测正确标签,这样就尽可能地保持了训练和预测的一致性。
文章小结
本文介绍并实现了一种seq2seq的双向解码机制,它将整个解码过程对称化了,从而在一定程度上使得生成质量更高了。个人认为这种改进的尝试还是有一定的价值的,尤其是对于追求形式美的读者来说。所以就将其介绍一番。
除此之外,文章也分析了这种双向解码可能存在的问题,给出了笔者自己的看法。敬请各位读者多多交流直角~
如果您需要引用本文,请参考:
苏剑林. (Aug. 09, 2019). 《seq2seq之双向解码 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/6877
seq2seq之双向解码的更多相关文章
- 深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用. 1. seq2seq模型介绍 seq2se ...
- 深度学习的seq2seq模型——本质是LSTM,训练过程是使得所有样本的p(y1,...,yT‘|x1,...,xT)概率之和最大
from:https://baijiahao.baidu.com/s?id=1584177164196579663&wfr=spider&for=pc seq2seq模型是以编码(En ...
- seq2seq+attention解读
1什么是注意力机制? Attention是一种用于提升Encoder + Decoder模型的效果的机制. 2.Attention Mechanism原理 要介绍Attention Mechanism ...
- 介绍 Seq2Seq 模型
2019-09-10 19:29:26 问题描述:什么是Seq2Seq模型?Seq2Seq模型在解码时有哪些常用办法? 问题求解: Seq2Seq模型是将一个序列信号,通过编码解码生成一个新的序列信号 ...
- 【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
http://spaces.ac.cn/archives/3924/ 关于字标注法 上一篇文章谈到了分词的字标注法.要注意字标注法是很有潜力的,要不然它也不会在公开测试中取得最优的成绩了.在我看来,字 ...
- 基于双向LSTM和迁移学习的seq2seq核心实体识别
http://spaces.ac.cn/archives/3942/ 暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下.模型的效果不是最好的,但是胜在“端到端”, ...
- 深度学习之注意力机制(Attention Mechanism)和Seq2Seq
这篇文章整理有关注意力机制(Attention Mechanism )的知识,主要涉及以下几点内容: 1.注意力机制是为了解决什么问题而提出来的? 2.软性注意力机制的数学原理: 3.软性注意力机制. ...
- 【译】深度双向Transformer预训练【BERT第一作者分享】
目录 NLP中的预训练 语境表示 语境表示相关研究 存在的问题 BERT的解决方案 任务一:Masked LM 任务二:预测下一句 BERT 输入表示 模型结构--Transformer编码器 Tra ...
- seq2seq模型以及其tensorflow的简化代码实现
本文内容: 什么是seq2seq模型 Encoder-Decoder结构 常用的四种结构 带attention的seq2seq 模型的输出 seq2seq简单序列生成实现代码 一.什么是seq2seq ...
随机推荐
- Linux系列(7) - 链接命令
硬链接 拥有相同的i节点和存储block块,可以看做事同一个文件 可通过i节点识别 不能跨分区 不能针对目录使用,只能针对文件 软链接 类似Windows快捷方式 软链接拥有自己的i节点和block块 ...
- windows10 升级并安装配置 jmeter5.3
一.安装配置JDK Jmeter5.3依赖JDK1.8+版本,JDK安装百度搜索JAVA下载JDK,地址:https://www.oracle.com/technetwork/java/javase/ ...
- K8s一键安装
安装案例: 系统:Centos可以多台Master(Master不能低于3台)多台Node此案例使用三台Master两台Node,用户名root,密码均为123456 master 192.168.2 ...
- jqGride的基本使用
1. 定义:jqGrid是一个在jQuery基础上封装一个表格控件,以ajax的方式和服务器端通信. 2. 使用方式: 2.1 项目中引入jqGride的文件: 2.2 搭建开发页面: 2.3 构建 ...
- openTSDB-采集器批量部署-tcollector
前提: 所需安装采集器服务器与部署服务器之间都已经配置无密码登录 1.安装服务器安装expect包 安装服务器与需要安装Tcollector服务器之间未配置无密登录需要此步. yum inst ...
- genymotion从本地拖拽apk到模拟器失败,报错“An error occured while deploying the file……”-解决方案
前两篇已经讲过genymotion的安装了,但genymotion构建的安卓模拟器的界面比较简洁,什么软件都没.那么我们进行测试之前,先将需要测试的apk安装到模拟器中,一般来说,直接将apk文件从本 ...
- sublime text 3 在Windows下配置sublimelinter-php的路径问题
首先用package control安装sublimelinter和sublimelinter-php,然后依次点击菜单preference-package settings-sublimelinte ...
- 鸿蒙内核源码分析(管道文件篇) | 如何降低数据流动成本 | 百篇博客分析OpenHarmony源码 | v70.01
百篇博客系列篇.本篇为: v70.xx 鸿蒙内核源码分析(管道文件篇) | 如何降低数据流动成本 | 51.c.h.o 文件系统相关篇为: v62.xx 鸿蒙内核源码分析(文件概念篇) | 为什么说一 ...
- Java MD5和SHA256等常用加密算法
前言 我们在做java项目开发的时候,在前后端接口分离模式下,接口信息需要加密处理,做签名认证,还有在用户登录信息密码等也都需要数据加密.信息加密是现在几乎所有项目都需要用到的技术,身份认证.单点登陆 ...
- Unity——基于UGUI的UI框架
基于UGUI的UI框架 一.Demo展示 二.关键类 MonoSingle 继承MonoBehaviour的单例基类:做了一些特殊处理: 保证场景中必须有GameInit名称的物体,所有单例管理器脚本 ...