Hive实战UDF 外部依赖文件找不到的问题

关注公众号:
大数据技术派,回复“资料”,领取1000G资料。
其实这篇文章的起源是,我司有数据清洗时将ip转化为类似中国-湖北-武汉地区这种需求。由于ip服务商提供的Demo,只能在本地读取,我需要将ip库上传到HDFS分布式存储,每个计算节点再从HDFS下载到本地。
那么到底能不能直接从HDFS读取呢?跟我强哥讲了这件事后,不服输的他把肝儿都熬黑了,终于给出了解决方案。
关于外部依赖文件找不到的问题
其实我在上一篇的总结中也说过了你需要确定的上传的db 文件在那里,也就是你在hive 中调用add file之后 会出现添加后的文件路径或者使用list 命令来看一下
今天我们不讨论这个问题我们讨论另外一个问题,外部依赖的问题,当然这个问题的引入本来就很有意思,其实是一个很简单的事情。
为什么要使用外部依赖
重点强调一下我们的外部依赖并不是单单指的是jar包依赖,我们的程序或者是UDF 依赖的一切外部文件都可以算作是外部依赖。
使用外部依赖的的原因是我们的程序可能需要一些外部的文件,或者是其他的一些信息,例如我们这里的UDF 中的IP 解析库(DB 文件),或者是你需要在UDF 访问一些网络信息等等。
为什么idea 里面可以运行上线之后不行
我们很多如人的一个误区就是明明我在IDEA 里面都可以运行为什么上线或者是打成jar 包之后就不行,其实你在idea 可以运行之后不应该直接上线的,或者说是不应该直接创建UDF 的,而是先应该测试一下jar 是否可以正常运行,如果jar 都不能正常运行那UDF 坑定就运行报错啊。
接下来我们就看一下为什么idea 可以运行,但是jar 就不行,代码我们就不全部粘贴了,只粘贴必要的,完整代码可以看前面一篇文章
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
converter = ObjectInspectorConverters.getConverter(arguments[0], PrimitiveObjectInspectorFactory.writableStringObjectInspector);
String dbPath = Ip2Region.class.getResource("/ip2region.db").getPath();
File file = new File(dbPath);
if (file.exists() == false) {
System.out.println("Error: Invalid ip2region.db file");
return null;
}
DbConfig config = null;
try {
config = new DbConfig();
searcher = new DbSearcher(config, dbPath);
} catch (DbMakerConfigException | FileNotFoundException e) {
e.printStackTrace();
}
return PrimitiveObjectInspectorFactory.writableStringObjectInspector;
}
这就是我们读取外部配置文件的方法,我们接下来写一个测试
@Test
public void ip2Region() throws HiveException {
Ip2Region udf = new Ip2Region();
ObjectInspector valueOI0 = PrimitiveObjectInspectorFactory.javaStringObjectInspector;
ObjectInspector[] init_args = {valueOI0};
udf.initialize(init_args);
String ip = "220.248.12.158";
GenericUDF.DeferredObject valueObj0 = new GenericUDF.DeferredJavaObject(ip);
GenericUDF.DeferredObject[] args = {valueObj0};
Text res = (Text) udf.evaluate(args);
System.out.println(res.toString());
}
我们发现是可以正常运行的,这里我们把它打成jar 包再运行一下,为了方便测试我们将这个测试方法改成main 方法,我们还是先在idea 里面运行一下
我们发现还是可以正常运行,我们接下来打个jar包试一下
Error: Invalid ip2region.db file
java.io.FileNotFoundException: file: /Users/liuwenqiang/workspace/code/idea/HiveUDF/target/HiveUDF-0.0.4.jar!/ip2region.db (No such file or directory)
at java.io.RandomAccessFile.open0(Native Method)
at java.io.RandomAccessFile.open(RandomAccessFile.java:316)
at java.io.RandomAccessFile.<init>(RandomAccessFile.java:243)
at java.io.RandomAccessFile.<init>(RandomAccessFile.java:124)
at org.lionsoul.ip2region.DbSearcher.<init>(DbSearcher.java:58)
at com.kingcall.bigdata.HiveUDF.Ip2Region.main((Ip2Region.java:42)
Exception in thread "main" java.lang.NullPointerException
at com.kingcall.bigdata.HiveUDF.Ip2Region.main(Ip2Region.java:48)
我们发现jar 包已经报错了,那你的UDF 肯定运行不了了啊,其实如果你仔细看的话就知道为什么报错了 /Users/liuwenqiang/workspace/code/idea/HiveUDF/target/HiveUDF-0.0.4.jar!/ip2region.db 其实就是这个路径,我们很明显看到这个路径是不对的,所以这就是我们UDF报错的原因
依赖文件直接打包在jar 包里面不香吗
上面找到了这个问题,现在我们就看一下如何解决这个问题,出现这个问题的原因就是打包后的路径不对,导致我们的不能找到这个依赖文件,那我们为什要这个路径呢。这个主要是因为我们使用的API 的原因
DbConfig config = new DbConfig();
DbSearcher searcher = new DbSearcher(config, dbPath);
也就是说我们的new DbSearcher(config, dbPath) 第二个参数传的是DB 的路径,所以我们很自然的想到看一下源码是怎么使用这个路径的,能不能传一个其他特定的路径进去,其实我们从idea 里面可以运行就知道,我们是可以传入一个本地路径的。
这里我们以memorySearch 方法作为入口
// 构造方法
public DbSearcher(DbConfig dbConfig, String dbFile) throws FileNotFoundException {
this.dbConfig = dbConfig;
this.raf = new RandomAccessFile(dbFile, "r");
}
// 构造方法
public DbSearcher(DbConfig dbConfig, byte[] dbBinStr) {
this.dbConfig = dbConfig;
this.dbBinStr = dbBinStr;
this.firstIndexPtr = Util.getIntLong(dbBinStr, 0);
this.lastIndexPtr = Util.getIntLong(dbBinStr, 4);
this.totalIndexBlocks = (int)((this.lastIndexPtr - this.firstIndexPtr) / (long)IndexBlock.getIndexBlockLength()) + 1;
}
// memorySearch 方法
public DataBlock memorySearch(long ip) throws IOException {
int blen = IndexBlock.getIndexBlockLength();
// 读取文件到内存数组
if (this.dbBinStr == null) {
this.dbBinStr = new byte[(int)this.raf.length()];
this.raf.seek(0L);
this.raf.readFully(this.dbBinStr, 0, this.dbBinStr.length);
this.firstIndexPtr = Util.getIntLong(this.dbBinStr, 0);
this.lastIndexPtr = Util.getIntLong(this.dbBinStr, 4);
this.totalIndexBlocks = (int)((this.lastIndexPtr - this.firstIndexPtr) / (long)blen) + 1;
}
int l = 0;
int h = this.totalIndexBlocks;
long dataptr = 0L;
int m;
int p;
while(l <= h) {
m = l + h >> 1;
p = (int)(this.firstIndexPtr + (long)(m * blen));
long sip = Util.getIntLong(this.dbBinStr, p);
if (ip < sip) {
h = m - 1;
} else {
long eip = Util.getIntLong(this.dbBinStr, p + 4);
if (ip <= eip) {
dataptr = Util.getIntLong(this.dbBinStr, p + 8);
break;
}
l = m + 1;
}
}
if (dataptr == 0L) {
return null;
} else {
m = (int)(dataptr >> 24 & 255L);
p = (int)(dataptr & 16777215L);
int city_id = (int)Util.getIntLong(this.dbBinStr, p);
String region = new String(this.dbBinStr, p + 4, m - 4, "UTF-8");
return new DataBlock(city_id, region, p);
}
}
其实我们看到memorySearch 方法首先是读取DB 文件到内存的字节数组然后使用,而且我们看到有这样一个字节数组的构造方法DbSearcher(DbConfig dbConfig, byte[] dbBinStr)
既然读取文件不行,那我们能不能直接传入字节数组呢?其实可以的
DbSearcher searcher=null;
DbConfig config = new DbConfig();
try {
config = new DbConfig();
} catch (DbMakerConfigException e) {
e.printStackTrace();
}
InputStream inputStream = Ip2Region.class.getResourceAsStream("/ip2region.db");
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[4096];
int n = 0;
while (-1 != (n = inputStream.read(buffer))) {
output.write(buffer, 0, n);
}
byte[] bytes = output.toByteArray();
searcher = new DbSearcher(config, bytes);
// 只能使用memorySearch 方法
DataBlock block = searcher.memorySearch(ip);
//打印位置信息(格式:国家|大区|省份|城市|运营商)
System.out.println(block.getRegion());
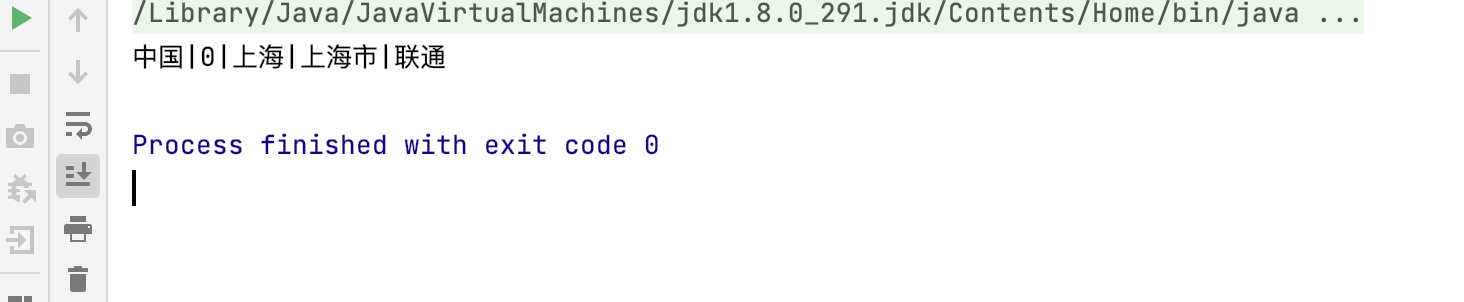
我们还是先在Idea 里面测试,我们发现是可以运行的,然后我们还是打成jar包进行测试,这次我们发现还是可以运行中国|0|上海|上海市|联通
也就是说我们已经把这个问题解决了,有没有什么问题呢?有那就是DB 文件在jar 包里面,不能单独更新,前面我们将分词的时候也水果,停用词库是随着公司的业务发展需要更新的 DB库也是一样的。
也就是说可以这样解决但是不完美,我看到有的人是这样做的他使用getResourceAsStream 把数据读取到内存,然后再写出成本地临时文件,然后再使用,我只想说这个解决方式也太不友好了吧
- 文件不能更新
- 需要写临时文件(权限问题,如果被删除了还得重写)
只能使用memorySearch 方法
这个原因值得说明一下,因为你使用其他两个search 方法的时候都会抛出异常Exception in thread "main" java.lang.NullPointerException
这主要是因为其他两个方法都是涉及到从文件读取数据进来,但是我们的raf 是null
学会独立思考并且解决问题
上面我们的UDF 其实已经可以正常使用了,但是有不足之处,这里我们就处理一下这个问题,前面我们说过了其实在IDEA 里的路径参数可以使用,那就说明传入本地文件是可以的,但是有一个问题就是我们的UDF 是可能在所有节点上运行的,所以传入本地路径的前提是需要保证所有节点上这个本地路径都可用,但是这样维护成本也很高,还不如直接将依赖放在jar 包里面。
继承DbSearcher
其实我们是可以将这个依赖放在OSS或者是HDFS 上的,但是这个时候你传入路径之后,还是有问题,因为构造方法里面读取文件的时候默认的是本地方法,其实这个时候你可以继承DbSearcher 方法,然后添加新的构造方法,完成从HDFS 上读取文件。
// 构造方法
public DbSearcher(DbConfig dbConfig, byte[] dbBinStr) {
this.dbConfig = dbConfig;
this.dbBinStr = dbBinStr;
this.firstIndexPtr = Util.getIntLong(dbBinStr, 0);
this.lastIndexPtr = Util.getIntLong(dbBinStr, 4);
this.totalIndexBlocks = (int)((this.lastIndexPtr - this.firstIndexPtr) / (long)IndexBlock.getIndexBlockLength()) + 1;
}
读取文件传入字节数组
还有一个方法就是我们直接使用第二个构造方法,dbBinStr 就是我们读取进来的字节数组,这个时候不论这个依赖是在HDFS 还是OSS 上你只要调用相关的API 就可以了,其实这个方法我们在读取jar包里面的文件的时候已经使用过了
下面的ctx就是OSS的上下问,用来从OSS上读取数据,同理你可以从任何你需要的地方读取数据。
DbConfig config = null;
try {
config = new DbConfig();
} catch (DbMakerConfigException e) {
e.printStackTrace();
}
InputStream inputStream = ctx.readResourceFileAsStream("ip2region.db");
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[4096];
int n = 0;
while (-1 != (n = inputStream.read(buffer))) {
output.write(buffer, 0, n);
}
byte[] bytes = output.toByteArray();
searcher = new DbSearcher(config, bytes);
总结
Idea里面使用文件路径是可以的,但是jar里面不行,要使用也是本地文件或者是使用getResourceAsStream获取InputStream;- 存储在
HDFS或者OSS上的文件也不能使用路径,因为默认是读取本地文件的; - 多思考,为什么,看看源码,最后请你思考一下怎么在外部依赖的情况下使用
binarySearch或者是btreeSearch方法;
猜你喜欢
数仓建模—宽表的设计
Spark SQL知识点与实战
Hive计算最大连续登陆天数
Hadoop 数据迁移用法详解
数仓建模分层理论
Hive实战UDF 外部依赖文件找不到的问题的更多相关文章
- linux寻找依赖文件
在linux下编译安装软件有时候会遇到依赖文件找不到的情况,很多时候可以通过 sudo apt install -f 来解决:实在找不到怎么办,还有一个绝招可以用: 安装 apt-file sudo ...
- Hive 文件格式 & Hive操作(外部表、内部表、区、桶、视图、索引、join用法、内置操作符与函数、复合类型、用户自定义函数UDF、查询优化和权限控制)
本博文的主要内容如下: Hive文件存储格式 Hive 操作之表操作:创建外.内部表 Hive操作之表操作:表查询 Hive操作之表操作:数据加载 Hive操作之表操作:插入单表.插入多表 Hive语 ...
- [原创]java WEB学习笔记99:Spring学习---Spring Bean配置:自动装配,配置bean之间的关系(继承/依赖),bean的作用域(singleton,prototype,web环境作用域),使用外部属性文件
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- Hive基于UDF进行文本分词
本文大纲 UDF 简介 Hive作为一个sql查询引擎,自带了一些基本的函数,比如count(计数),sum(求和),有时候这些基本函数满足不了我们的需求,这时候就要写hive hdf(user de ...
- Gradle实战教程之依赖管理
这是从我个人网站中复制过来的,原文地址:http://coolshell.info/blog/2015/05/gradle-dependency-management.html,转载请注明出处. 简要 ...
- Hive的UDF实现及注意事项
Hive自身查询语言HQL能完毕大部分的功能,但遇到特殊需求时,须要自己写UDF实现.下面是一个完整的案例. 1.eclipse中编写UDF ①项目中增加hive的lib下的全部jar包和Hadoop ...
- hive 添加UDF(user define function) hive的insert语句
add JAR /home/hadoop/study/study2/utf.jar; package my.bigdata.udf; import org.apache.hadoop.hive.ql. ...
- VS2012中使用CEGUI项目发布到XP平台的问题(核心方法就一句话。“你项目使用的所有外部依赖库都用/MT编译。”)
接着上一篇文章,详细说说如何把一个带CEGUI的项目发布到XP平台. 这个问题纠缠了我好几天.这里把详细解决思路记下来.有同样问题的朋友可以少走很多弯路. 核心方法就一句话.“你项目使用的所有外部依赖 ...
- JBoss 系列十四:JBoss7/WildFly如何加载外部的文件或properties文件
http://www.tuicool.com/articles/M7ZR3y 原文 http://blog.csdn.net/kylinsoong/article/details/12623997 主 ...
随机推荐
- 菜鸡的Java笔记 第二十八 - java 包的定义
包的主要作用以及定义 包的导入操作 系统常见的开发包 jar 程序命令 包的定义 在任何的操作系统之中都有一个统一的共识:同一个目录下不能够存在有相同的文 ...
- [luogu5577]算力训练
(以下以$B$为进制,$m$为幂次,$n=B^{m}$) 定义$\oplus$为$k$进制下不进位加法,$\otimes$为$\oplus$卷积 令$f_{i,j}$表示前$i$个数的$\oplus$ ...
- [atARC075F]Mirrored
假设$n=\sum_{i=0}^{k}a_{i}10^{i}$(其中$a_{k}>0$),则有$d=f(n)-n=\sum_{i=0}^{k}(10^{k-i}-10^{i})a_{i}$,考虑 ...
- dart系列之:在dart中使用生成器
目录 简介 两种返回类型的generator Stream的操作 总结 简介 ES6中在引入异步编程的同时,也引入了Generators,通过yield关键词来生成对应的数据.同样的dart也有yie ...
- 明明pip安装python的模块了,pycharm还是找不到的解决方案
以前pycharm的安装包和python的环境一直都不能融合在一起,到了今天才知道,原来他们都是有自己的工作环境的 自己的工作环境(虚拟解释器)和安装python的工作环境(基本解释器)不是一个环境, ...
- 洛谷 P6383 -『MdOI R2』Resurrection(DP)
洛谷题面传送门 高速公路上正是补 blog 的时候,难道不是吗/doge,难不成逆在高速公路上写题/jy 首先形成的图显然是连通图并且有 \(n-1\) 条边.故形成的图是一棵树. 我们考虑什么样的树 ...
- Atcoder Regular Contest 072 C - Alice in linear land(思维题)
Atcoder 题面传送门 & 洛谷题面传送门 首先求出 \(s_i\) 表示经过 \(i\) 次操作后机器人会位于什么位置,显然 \(s_0=D\),\(s_i=\min(s_{i-1},| ...
- DP 做题记录 II.
里面会有一些数据结构优化 DP 的题目(如 XI.),以及普通 DP. *I. P3643 [APIO2016]划艇 题意简述:给出序列 \(a_i,b_i\),求出有多少序列 \(c_i\) 满足 ...
- 【GS文献】测序时代植物复杂性状育种之基因组选择
综述:Genomic Selection in the Era of Next Generation Sequencing for Complex Traits in Plant Breeding 要 ...
- nginx_update
软件下载 预编译 编译 配置 [root@MiWiFi-R1CM-srv ~]#wget -c https://nginx.org/download/nginx-1.15.0.tar.gz 通过-V查 ...