Hive(九)【自定义函数】
自定义函数
Hive 自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
用户自定义函数类别分为以下三种
UDF(User-Defined-Function)
一进一出
UDAF(User-Defined Aggregation Function)
多进一出;如聚集函数
UDTF(User-Defined Table-Generating Functions)
一进多出;如炸裂函数(explode)
临时函数:只存在当前会话,切换或断开就没有了,和当前use的库没有关系
删除临时函数:drop temporary function 函数名 或者 断开会话
永久函数:和库关联,在创建的时候需要指定库a.函数名,在使用的时候如果当前使用的库就是
编程步骤
(1)官方文档:https://cwiki.apache.org/confluence/display/Hive/HivePlugins
(2)继承Hive提供的类
3.x逐渐弃用UDF类,推荐用下面的
org.apache.hadoop.hive.ql.udf.generic.GenericUDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
(3)实现类中的抽象方法
(4)在hive的命令行窗口创建函数
添加jar
add jar linux_jar_path
创建function
create [temporary] function [dbname.]function_name AS class_name;
(5)在hive的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;
案例
需求
1.创建工程
2.导入依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
3.创建类
MyLen.java
package com.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* @description: 自定义UDF函数类, 求输入数据长度,只能处理一个hive的基本类型参数
* @author: HaoWu
* @create: 2020/6/30 11:39
*/
//hive3.X的UDF类已废除,推荐用GenericUDF
public class MyLen extends GenericUDF {
/**
* 初始化
*
* @param objectInspectors 输入参数类型的鉴别器对象
* @return 返回值类型的鉴别器对象
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
//判断输入参数的个数
if (objectInspectors.length != 1) {
throw new UDFArgumentLengthException("input args nums Error...");
}
//判断输入参数的类型是否为hive基本类型
if (!objectInspectors[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)) {
throw new UDFArgumentTypeException(0, "input args type Error...");
}
//函数本身返回int,需要返回int类型的鉴别器对象
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 函数处理逻辑
*
* @param deferredObjects
* @return
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
if (deferredObjects[0].get() == null) {
return 0;
}
Object obj = deferredObjects[0];
int len = obj.toString().length();
return len;
}
@Override
public String getDisplayString(String[] strings) {
return "";
}
}
4.打jar包
打包插件
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 指定主类 -->
<mainClass>com.hive.udf.MyLen</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
打包package,然后改名为mylen_udf.jar
5.上传hive所在服务器
[atguigu@hadoop102 datas]$ tree /opt/module/hive/datas/
/opt/module/hive/datas/
└── my_len.jar
6.将jar添加到hive的classpath
add jar /opt/module/hive/datas/mylen_udf.jar
7.创建临时函数与开发好的java class关联
create temporary function mylenudf as "com.hive.udf.MyLen"
8.测试自定义函数
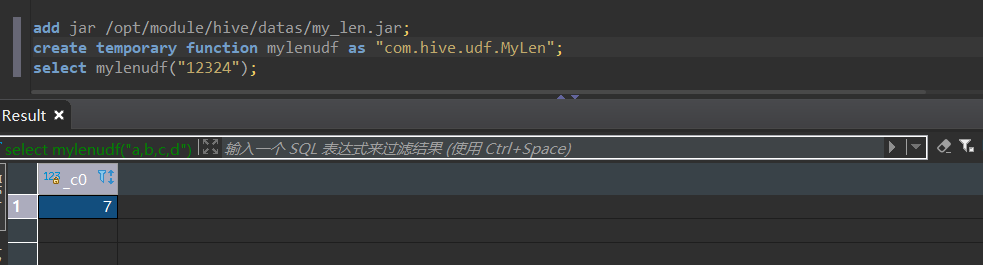
临时函数和永久函数
创建临时函数
添加jar包的类路径给hive,注意是临时生效
add jar /opt/module/hive/datas/myudf.jar;
创建临时函数
create temporary function my_len as "com.atguigu.hive.udf.MyStringLength";
删除临时函数
drop temporary function my_len;
注意:临时函数只跟会话有关系,只要会话不断,在当前会话下,任意一个库都可以使用。其他会话全都不能使用。
创建永久函数
注意:因为永久函数是永久生效的,我们推出当前会话以后,其他会话也要使用永久函数,因此我们就不能简单的使用add jar来添加hive的类路径了
创建永久函数
注意:此时要使用USING JAR的方式来添加函数的jar包类路径,并且这个路径必须是hdfs路径
create function my_len2 as "com.atguigu.hive.udf.MyStringLength" USING JAR 'hdfs://hadoop102:9820/hivejar/myudf.jar';
删除永久函数
drop function my_len2;
注意:永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。
然后使用永久函数的时候,需要在指定的库里面操作,或者在其他库里面使用的话得加上 库名.函数名
二.UDTF案例
1.创建类
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.json.JSONArray;
import java.util.ArrayList;
import java.util.List;
/**
* @description: UDTF函数功能(类似于explode函数功能)
* 入参:将json数组字符串
* 出参:将json数组的每一个元素作为一行输出
*
* @author: HaoWu
* @create: 2020年08月15日
*/
public class ExplodeJSONArrayUDTF extends GenericUDTF {
/*
初始化方法
*/
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
//1.获取传入的参数
List<? extends StructField> inputFields = argOIs.getAllStructFieldRefs();
//2.判断参数个数是否为一个?
if (inputFields.size() != 1) {
throw new UDFArgumentException("只需要一个参数");
}
//3.定义返回值名称和类型
//返回的字段名
List<String> fieldNames = new ArrayList<>();
fieldNames.add("action");
//返回的字段类型
List<ObjectInspector> fieldOIs = new ArrayList<>();
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
/*
生成返回的数据
*/
@Override
public void process(Object[] objects) throws HiveException {
//1.获取传入的数据
String jsonArray = objects[0].toString();
//2.将string转化为json数组
JSONArray actions = new JSONArray(jsonArray);
//3.循环取出json数组的元素,依次写出
for (int i = 0; i < actions.length(); i++) {
String[] result = new String[1];
result[0]=actions.getString(i);
//写出
forward(result);
}
}
@Override
public void close() throws HiveException {
}
}
2.打包上传
将hivefunction-1.0-SNAPSHOT.jar上传到hadoop102的/opt/module,然后再将该jar包上传到HDFS的/user/hive/jars路径下
[root@hadoop102 module]$ hadoop fs -mkdir -p /user/hive/jars
[root@hadoop102 module]$ hadoop fs -put warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar /user/hive/jars
3.创建临时函数
hive> create function explode_json_array as 'com.hivescript.ExplodeJSONArrayUDTF' using jar 'hdfs://hadoop102:8020/user/hive/jars/warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar';
Added [/tmp/ca6c5ab9-c76b-406b-9d1f-63aa32523f2f_resources/warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar] to class path
Added resources: [hdfs://hadoop102:8020/user/hive/jars/warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar]
OK
Time taken: 1.093 seconds
4.测试
测试数据
[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]
hive> select explode_json_array('[{"name":"大郎","sex":"男","age":"25"},{"name":"西门庆","sex":"男","age":"47"}]');
OK
{"name":"大郎","sex":"男","age":"25"}
{"name":"西门庆","sex":"男","age":"47"}
Time taken: 2.906 seconds, Fetched: 2 row(s)
注意
如果修改了自定义函数重新生成jar包怎么处理?只需要替换HDFS路径上的旧jar包,然后重启Hive客户端即可。
Hive(九)【自定义函数】的更多相关文章
- Hadoop生态圈-hive编写自定义函数
Hadoop生态圈-hive编写自定义函数 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hive的自定义函数之UDTF(User-Defined Table-Generating Functions)
Hadoop生态圈-Hive的自定义函数之UDTF(User-Defined Table-Generating Functions) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function)
Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hive的自定义函数之UDF(User-Defined-Function)
Hadoop生态圈-Hive的自定义函数之UDF(User-Defined-Function) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- 【Hive】自定义函数
Hive的自定义函数无法满足实际业务的需要,所以为了扩展性,Hive官方提供了自定义函数来实现需要的业务场景. 1.定义 (1)udf(user defined function): 自定义函数,特 ...
- Hive中自定义函数
Hive的自定义的函数的步骤: 1°.自定义UDF extends org.apache.hadoop.hive.ql.exec.UDF 2°.需要实现evaluate函数,evaluate函数支持重 ...
- [Hive_12] Hive 的自定义函数
0. 说明 UDF //user define function //输入单行,输出单行,类似于 format_number(age,'000') UDTF //user define table-g ...
- Hive中如何添加自定义UDF函数以及oozie中使用hive的自定义函数
操作步骤: 1. 修改.hiverc文件 在hive的conf文件夹下面,如果没有.hiverc文件,手工自己创建一个. 参照如下格式添加: add jar /usr/local/hive/exter ...
- Hive(9)-自定义函数
一. 自定义函数分类 当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数. 根据用户自定义函数类别分为以下三种: 1. UDF(User-Defined-Functi ...
- 三 Hive 数据处理 自定义函数UDF和Transform
三 Hive 自定义函数UDF和Transform 开篇提示: 快速链接beeline的方式: ./beeline -u jdbc:hive2://hadoop1:10000 -n hadoop 1 ...
随机推荐
- 全志Tina_dolphin播放音视频裸流(h264,pcm)验证
最近在验证tina对裸流音视频的支持,主要指h264视频裸流及pcm音频裸流. 在原始sdk中有针对很多video和audio类型的parser,但就是没有找到pcm和h264的parser,所以需要 ...
- PCIE学习笔记--TLP Header详解(三)
目录篇地址为:http://blog.chinaaet.com/justlxy/p/5100053481 Completions Completions的TLP Header的格式如下图所示: 这里来 ...
- Luogu P2081 [NOI2012]迷失游乐园 | 期望 DP 基环树
题目链接 基环树套路题.(然而各种错误调了好久233) 当$m=n-1$时,原图是一棵树. 先以任意点为根做$dp$,求出从每一个点出发,然后只往自己子树里走时路径的期望长度. 接着再把整棵树再扫一遍 ...
- cf14C Four Segments(计算几何)
题意: 给四个线段(两个端点的坐标). 判断这四个线段能否构成一个矩形.(矩形的四条边都平行于X轴或Y轴) 思路: 计算几何 代码: class Point{ public: int x,y; voi ...
- APP 自动化之系统按键事件(五)
转载记录方便后续自己使用: 代码就一句driver.keyevent()括号内填入的是物理按键的数字代号 代号表: 电话键 KEYCODE_CALL 拨号键 5 KEYCODE_ENDCALL 挂机键 ...
- 《手把手教你》系列技巧篇(四十)-java+ selenium自动化测试-JavaScript的调用执行-下篇(详解教程)
1.简介 在实际工作中,我们需要对处理的元素进行高亮显示,或者有时候为了看清楚做跟踪鼠标点击了哪些元素需要标记出来.今天宏哥就在这里把这种测试场景讲解和分享一下. 2.用法 创建一个执行 JS 的对象 ...
- vue引入elementUI(第三方样式库)
前置: 在已经安装好vue的前提下 ,没有安装vue参考: vue搭建教程 elementUI官网组件使用文档: elementUI使用文档 1.终端直接运行安装命令 npm i element-ui ...
- Intellij IDEA 内存设置的问题 及解决
在IDEA上运行较大项目时,编译量很大,可能会报出 Error:java: java.lang.OutOfMemoryError: Java heap space 的错误,解决方法如下:java.la ...
- 72.Financial Management
描述 Larry graduated this year and finally has a job. He's making a lot of money, but somehow never se ...
- .NET Protobuf包装器库
Wodsoft Protobuf Wrapper 内容 关于 需求 安装 用法 序列化 反序列化 字段定义 字段排序 非空构造函数对象 获取Protobuf包装器 高级 支持的属性类型与Protobu ...