【python爬虫】用python编写LOL战绩查询
介绍一个简单的python爬虫,通过Tkinter创建一个客户端,当输入要查询的LOL用户名称的时候,可以显示出当前用户的所在服务器,当前战力和当前段位。
爬取网页地址:http://lol.duowan.com/zdl/
python版本:2.7
需要用到的模块:Tkinter urllib2 json sys
实例代码:
import urllib2, json, threading
from Tkinter import *
import sys reload(sys)
sys.setdefaultencoding('utf-8') def get_zhanji():
name = str(et.get())
url = 'http://api.lolbox.duowan.com/api/v2/player/search/?player_name_list=%s&callback=jQuery111200161216930093' \
'95033_1470488155157&_=1470488155158' % name
res = urllib2.urlopen(url)
html = res.read()[44:-1]
print html
zhanji = json.loads(html)[u'player_list']
t.delete(0.0, END)
for i in zhanji:
print '服务器:%s 当前战力:%s' % (i['game_zone']['alias'], i['box_score'])
print '当前段位:%s' % (i['tier_rank']['tier']['full_name_cn'] + i['tier_rank']['rank']['name'])
# print i['game_zone']['alias']
# print zhangji
# print html
t.insert(END, '服务器:%s 当前战力:%s' % (i['game_zone']['alias'], i['box_score']))
t.insert(END, '当前段位:%s\n' % (i['tier_rank']['tier']['full_name_cn'] + i['tier_rank']['rank']['name'])) def rukou():
if et.get() == '':
print '请输入召唤师名称'
else:
get_zhanji() # def qidong():
# t1 = threading.Thread(target=rukou)
# t1.start()
# get_zhanji()
# print len(jQuery11120016121693009395033_1470488155157() root = Tk()
root.title('LOL战绩查询')
root.geometry() et = Entry(root, font=('宋体, 16'))
et.grid() b = Button(root, text='开始查询', font=('宋体, 12'), command=rukou)
b.grid() t = Text(root, font=('宋体, 16'))
t.grid() root.mainloop()
界面效果展示:
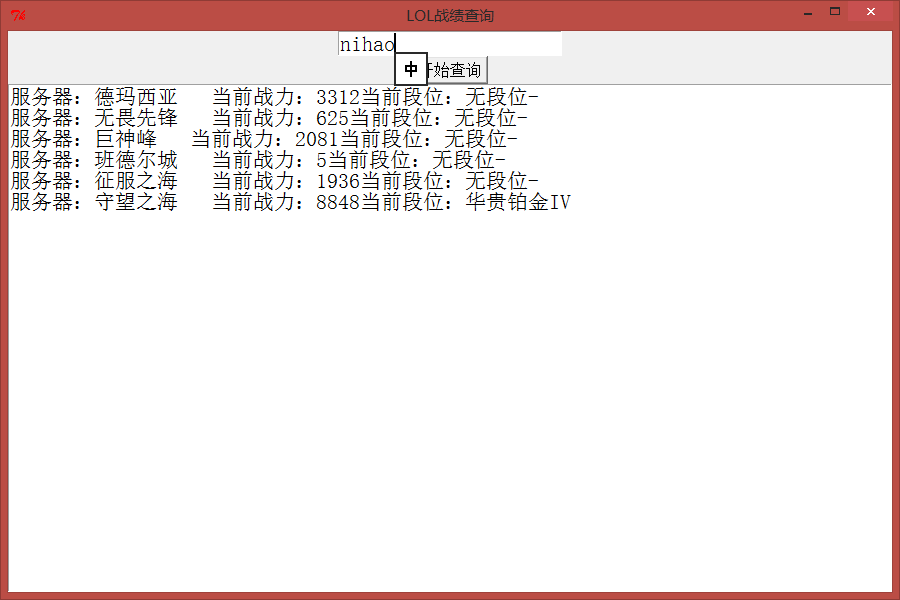
【python爬虫】用python编写LOL战绩查询的更多相关文章
- python爬虫之12306网站--火车票信息查询
python爬虫之12306网站--火车票信息查询 思路: 1.火车票信息查询是基于车站信息查询,先完成车站信息查询,然后根据车站信息查询生成的url地址去查询当前已知出发站和目的站的所有车次车票信息 ...
- 零基础学习Python web开发、Python爬虫、Python数据分析,从基础到项目实战!
随着大数据和人工智能的发展,目前Python语言的上升趋势比较明显,而且由于Python语言简单易学,所以不少初学者往往也会选择Python作为入门语言. Python语言目前是IT行业内应用最为广泛 ...
- python爬虫之12306网站--车站信息查询
python爬虫查询车站信息 目录: 1.找到要查询的url 2.对信息进行分析 3.对信息进行处理 python爬虫查询全拼相同的车站 目录: 1.找到要查询的url 2.对信息进行分析 3.对信息 ...
- Python爬虫《Python网络爬虫相关基础概念》
引入 之前在授课过程中,好多同学都问过我这样的一个问题:为什么要学习爬虫,学习爬虫能够为我们以后的发展带来那些好处?其实学习爬虫的原因和为我们以后发展带来的好处都是显而易见的,无论是从实际的应用还是从 ...
- Python 爬虫+tkinter界面 实现历史天气查询
文章目录 一.实现效果 1. python代码 2. 运行效果 二.基本思路 1. 爬虫部分 2. tkinter界面 一.实现效果 很多人学习python,不知道从何学起.很多人学习python,掌 ...
- 【Python爬虫】第四课(查询照片拍摄地址)
首先,要能够查询到照片地址,查询的照片必须要开GPS拍,且上传时用原图…… 查询图片的exif信息,使用exifread包 import exifread img = exifread.process ...
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- 一个Python爬虫工程师学习养成记
大数据的时代,网络爬虫已经成为了获取数据的一个重要手段. 但要学习好爬虫并没有那么简单.首先知识点和方向实在是太多了,它关系到了计算机网络.编程基础.前端开发.后端开发.App 开发与逆向.网络安全. ...
- python 爬虫使用
python爬虫架构 Python 爬虫架构主要由五个部分组成,分别是 调度器.URL管理器.网页下载器.网页解析器.应用程序. 调度器:相当于一台电脑的CPU,主要负责调度URL管理器.下载器.解析 ...
随机推荐
- Hibernate学习第三天(2)(多对多关系映射)
1.1.1 Hibernate多对多关系的配置 1.1.1.1 创建表 l 用户表 CREATE TABLE `sys_user` ( `user_id` bigint(32) NO ...
- vmware实现物理机和虚拟机复制粘贴
要实现物理机和虚拟机的复制粘贴需要安装VMware Tools. 1.点击菜单栏--虚拟机--安装VMware Tools. 2.打开linux终端,进入/media/VMware Tools目录. ...
- 加密模块(md5)
一.md5加密 import hashlib s = ' print(s.encode()) m = hashlib.md5(s.encode())# 必须得传一个bytes类型的 print(m.h ...
- 【spring】 SpringMVC返回json数据的三种方式
配置方法一 **1.导入第三方的jackson包,jackson-mapper-asl-1.9.7.jar和jackson-core-asl-1.9.7.jar. 2.spring配置文件添加** & ...
- CF165D Beard Graph
$ \color{#0066ff}{ 题目描述 }$ 给定一棵树,有m次操作. 1 x 把第x条边染成黑色 2 x 把第x条边染成白色 3 x y 查询x~y之间的黑边数,存在白边输出-1 \(\co ...
- if __name__ == '__main__'是什么意思?如何理解?看到一个很有用的解答
小明.py 朋友眼中你是小明(__name__ == '小明'), 你自己眼中你是你自己(__name__ == '__main__'), 你编程很好, 朋友调你去帮他写程序(import 小明, 这 ...
- 怎样关闭adobe reader的自动更新
https://jingyan.baidu.com/article/1612d5004390ebe20f1eee50.html
- AtCoder - 2565 枚举+贪心
There is a bar of chocolate with a height of H blocks and a width of W blocks. Snuke is dividing thi ...
- sqlalchemy orm数据类型验证方法比较
1.在定义ORM模型时校验 sqlalchemy提供validates函数支持对字段的校验 from sqlalchemy.orm import validates class EmailAddres ...
- Vue 使用 axios post请求后台数据时 404
今天遇到Vue 使用 axios post请求后台数据时 404 使用postman 就能获取到 网上找了大半天 终于找到了解决方法,传送门:https://www.jianshu.com/p/b10 ...